 Fedor
Fedor


Сас с внутрянкой сата, 7200 на четыре тера
Fedor
16 штук чтоль в 50 было
Fedor
И на одной из половин оно словило как раз ошибку и схлопнулось
 Alexey
Alexey
Народная мудрость: рейд - не бэкап.
Есть те, кто еще не делает бэкапы, те кто уже делает, и те кто делает и проверяет.
Fedor
 sexst
sexst
По этой статье 82% raid5 массивов не могут восстановиться
Ну потому, что в статье берётся worst case scenario. А в жизни между works case и best case охренеть какой разрыв
 Vladislav
Vladislav
Ну потому, что в статье берётся worst case scenario. А в жизни между works case и best case охренеть какой разрыв
Если бы это так позиционировалось то ладно, там это позиционируется как истина в последней инстанции по терверу (что нихуя не так)
sexst
Если бы это так позиционировалось то ладно, там это позиционируется как истина в последней инстанции по терверу (что нихуя не так)
Ну ептить. Считают то обычно для худшего сценария
 Айтуар
Айтуар
Вот нашел ту статейку
https://habr.com/en/articles/820551/
У нас диски по 5-8тб в аппаратном raid5. Сотни серверов. Пока за полтора года работы, при ребилде пару раз рейд развалился из-за выхода из строя второго диска при ребилде.
Fedor
Fedor
Если перефразировать, раз в сколько байт пролетит ошибка?
sexst
У нас диски по 5-8тб в аппаратном raid5. Сотни серверов. Пока за полтора года работы, при ребилде пару раз рейд развалился из-за выхода из строя второго диска при ребилде.
Тут ещё большой вопрос в том, сколько дисков в одном рейде
Vladislav
sexst
У нас диски по 5-8тб в аппаратном raid5. Сотни серверов. Пока за полтора года работы, при ребилде пару раз рейд развалился из-за выхода из строя второго диска при ребилде.
Второй вопрос: сколько раз за это время ребилдили?)
sexst
Хотя бы порядок
Айтуар
Второй вопрос: сколько раз за это время ребилдили?)
Лично наверное раз в месяц.
Ещё коллеги тоже делали.
Если суммировать, наверное раз в 2 недели точно.
sexst
Лично наверное раз в месяц.
Ещё коллеги тоже делали.
Если суммировать, наверное раз в 2 недели точно.
Ну то есть условно 2/40 бахнулось. Причем, подозреваю, не старьё.
Айтуар
Ну то есть условно 2/40 бахнулось. Причем, подозреваю, не старьё.
Диски были разные. Некоторые 5+ лет
Fedor
Fedor
Или это в сумме по всем массивам, раз в пару недель что-то вылетает?
sexst
Или это в сумме по всем массивам, раз в пару недель что-то вылетает?
Очевидно, что по всей инфре
Vladislav
 LordMerlin
LordMerlin
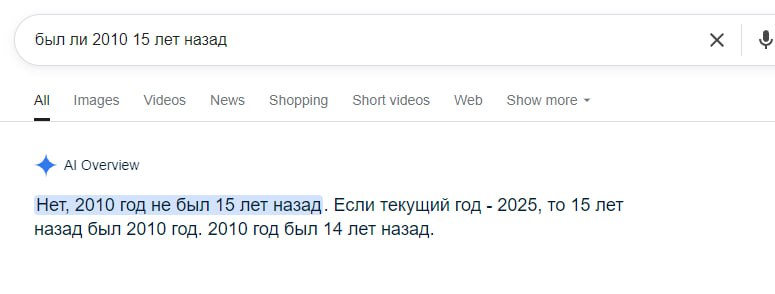
Зануда - вкл)
Это просто Гугл говно сделал))
Грок и Дипсик правильно отвечают даже если даты по разному менять))
Зануда - выкл))
А вообще да. Хорошее правило. Поддерживаем))
 Pavel
Pavel
 Alexey
Alexey
(разработчики ИИ начитались фантастики "Луна суровая хозяйка". В реальности так не будет. Поделка никогда не будет проявлять разум.)
 George
George
Ого что тащат https://github.com/openzfs/zfs/pull/17567
Vladislav
 Vladislav
Vladislav
(для понимания, что такое ADAPT)
Alexey
🙊
Pavel
Ого что тащат https://github.com/openzfs/zfs/pull/17567
Что-то подобное было в Synology вроде.
Там из остатков свободного места raid собирался.
Nikita
день добрый
имею сервак для логов с конфигом draid2:8d:36c:1s-0
что-то он стал у нас люто тормозить на запись, сислоги постоянно висят в D, очередь растёт, уменьшил нагрузку в 3 раза, не помогло никак, recordsize c 256k пробовал и 1М и 128к, меняется только compressratio
по сети прилетает 60М, на диск по iostat пишется 10М, но actual writes 200-600M, чего на аналогичных серверах с lvm вообще нет
то есть он плотно что-то пишет, на чтение нагрузки при этом вроде нет
по иотопу на первом месте txg_sync (70%+ io!), увеличил тайминг с 5с до 15, помогло, но не особо
и куча тредов
z_wr_int
z_wr_iss
не подскажете, что можно ещё посмотреть, подтюнить, куда копать?
Nikita
можно посмотреть zpool iostat, dmesg
в дмесге ничего, по iostat не меняется ничего, при изменении параметров zfs или снижения нагрузки на чтение
Vladislav
Если к примеру напрямую с них почитать через тот же DD 10GB в of=/dev/null - у них одинаково по времени?
 Ivan
Ivan
можно даже банально atop глянуть
 Nikita
Nikita
Если к примеру напрямую с них почитать через тот же DD 10GB в of=/dev/null - у них одинаково по времени?
могу попробовать, но в атопе красное по разным дискам вылезает
Vladislav
могу попробовать, но в атопе красное по разным дискам вылезает
Ну так может у Вас диски 5400 тошиба
Vladislav
Или зелёные вигейты
Nikita
диски ST20000NM007D-3DJ103 20Т
контроллер вроде такое LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02)
Vladislav
Так, хорошо
Vladislav
Теперь сколько их
Vladislav
И вообще, выводы команд
Nikita
https://pastebin.com/GRLcrdSa
Nikita
всё типа ок
Nikita
https://pastebin.com/WZwxjP75
вот iostat
Nikita
ну условно замечать начали с недели 2 назад, до этого полгода всё жило, не жаловались
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Там scrub начался. Интересно из-за него возможно 🧐
Nikita
он в паузе, если присмотреться
Nikita
проблеме 2 недели уже, это не связано со скрабом. и нагрузка на чтение околонулевая
Nikita
мне кажется, где-то в лимиты памяти упирается мб?
Ivan
https://pastebin.com/WZwxjP75
вот iostat
высокий r_await прыгает по дискам или же постоянно на одних и тех же дисках ?
Nikita
постоянно
Георгий подсказывает скорее всего потому что пишутся понемногу одновременно куча файлов
Ivan
постоянно
Георгий подсказывает скорее всего потому что пишутся понемногу одновременно куча файлов
кмк если задержка всегда на одних и тех же дисках, то с ними что-то не так.
Nikita
Нет, там всё одинаково на всех дисках
Игорь
Dedup?
Vladislav
день добрый
имею сервак для логов с конфигом draid2:8d:36c:1s-0
что-то он стал у нас люто тормозить на запись, сислоги постоянно висят в D, очередь растёт, уменьшил нагрузку в 3 раза, не помогло никак, recordsize c 256k пробовал и 1М и 128к, меняется только compressratio
по сети прилетает 60М, на диск по iostat пишется 10М, но actual writes 200-600M, чего на аналогичных серверах с lvm вообще нет
то есть он плотно что-то пишет, на чтение нагрузки при этом вроде нет
по иотопу на первом месте txg_sync (70%+ io!), увеличил тайминг с 5с до 15, помогло, но не особо
и куча тредов
z_wr_int
z_wr_iss
не подскажете, что можно ещё посмотреть, подтюнить, куда копать?
А, да, по этому вопросу
Во-первых, пришлите какой-нибудь SAR за часа 3 работы, лучше за день
Во-вторых, что по CPU, арку, доступному объему памяти
В-третьих, то есть до момент Х всё было ок на этой конфигурации? Что было изменено за день до момент Х?
Alexey
день добрый
имею сервак для логов с конфигом draid2:8d:36c:1s-0
что-то он стал у нас люто тормозить на запись, сислоги постоянно висят в D, очередь растёт, уменьшил нагрузку в 3 раза, не помогло никак, recordsize c 256k пробовал и 1М и 128к, меняется только compressratio
по сети прилетает 60М, на диск по iostat пишется 10М, но actual writes 200-600M, чего на аналогичных серверах с lvm вообще нет
то есть он плотно что-то пишет, на чтение нагрузки при этом вроде нет
по иотопу на первом месте txg_sync (70%+ io!), увеличил тайминг с 5с до 15, помогло, но не особо
и куча тредов
z_wr_int
z_wr_iss
не подскажете, что можно ещё посмотреть, подтюнить, куда копать?
Напишите, Вы когда считали массив, как Вы получили такую конфигурацию? draid2:8d:36c:1s-0
Как Вы посчитали такой массив?
 Alexander
Alexander
Судя по iostat (avgrq-sz=24=12к) у вас идет запись маленькими блоками, так что такое поведение ожидаемо. Что это - приложение так пишет или маленький recordsize?
Кроме того, у draid фиксированные размеры страйпа, поэтому все что меньше страйпа - дополняется нулями до размера страйпа. В том числе поэтому рекомендуется в draid использовать special vdev на ssd (у меня например даже на тестах чтения draid каждый раз писал один 4к блок на каждое чтение при даже при atime=off). Ну и стандартный совет использовать zfs v2.3.X т.к. получше с настройками по умолчанию...
Nikita
Это логи пишутся, много файлов
Alexander
zfs не самая быстрая файловая система. Но еще раз - судя по iostat оно у вас работает ожидаемо (24МБ/с 12к блоками) . Хотите быстрее - надо настраивать приложение (ну и zfs recordsize), чтобы писал бОльшим блоком (ну хотя бы 1М = 128к на диск при raidz8+2). Например попробуйте настроить ваш сислог (что у вас там rsyslog или syslog-ng - увеличьте буфер, чтобы копил больше логов и писал потом большим блоком). Настраивайте сеть. Это главное.
По zfs - проверьте настройки atime (relatime), zfs_vdev_(a)sync_write_max(min)_active, мониторьте zpool iostat
 Δαρθ
Δαρθ
 Arseniy
Arseniy
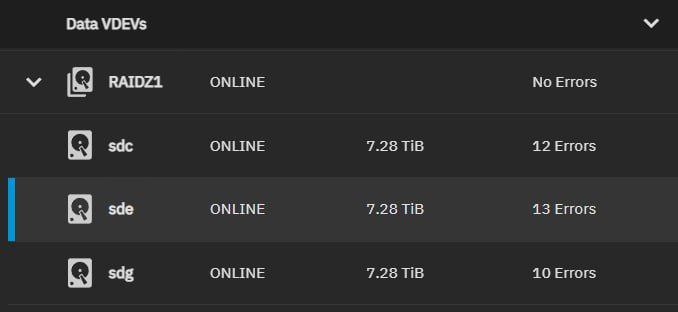
Господа, какие, на ваш взгляд, могут быть предпосылки, чтобы raidz1 внезапно сразу по всем 3 дискам оказался с ошибками?
Arseniy
 Станислав
Arseniy
Станислав
Arseniy
Контроллер чудит
Возможно. Есть методика проверки контроллера? Чёт на ум ничего не приходит. Только если взять заведомо новый диск, подрубить к этому же контроллеру, записать туда небольшой объем данных, и сделать scrub..
Vladislav
Бэкплейн,
Пыль,
Если поставил их одновременно из одной партии - дефект партии
Arseniy
Бэкплейн,
Пыль,
Если поставил их одновременно из одной партии - дефект партии
Исключаю. Неделю назад все перевтыкал, бэкплейна нет, все на кабелях. Диски из разных партий, дата производства разная.
Ну и чистил тоже все, естественно
George
Господа, какие, на ваш взгляд, могут быть предпосылки, чтобы raidz1 внезапно сразу по всем 3 дискам оказался с ошибками?
если равномерно все диски - точно что-то общее, аля контроллер/питание/мать