А reflinks (block_cloning) это новое?
Любопытно, а использование black хешей это тоже новое у человека?
 Vladislav
Vladislav


 Maksym
Maksym
Я хз с вами общаться противно. Сто лет сюда не заходил и не зайду больше.
 sexst
sexst
можно купить премиум и назначить цену за написание сообщения в ЛС. должно быстро окупиться 😃
Не, в личку ценник не выставить
sexst
можно купить премиум и назначить цену за написание сообщения в ЛС. должно быстро окупиться 😃
Каюсь, и правда можно выставить)
 Александр
Александр
Добрый день. Подскажите пожалуйста. У меня на сервере с Ubuntu есть root пул с установленными виртуальными машинами на нем. У меня стоит задача перенести пул на другой диск большего размера, так как нынешний уже забит. Что мне для этого подойдет лучше, клонирование или репликация?
 LordMerlin
LordMerlin
Что значит root пул? Всмысле там корень системы и там же диски виртуалок?
Тогда странное.
Ставьте отдельно диск под виртуалки и переносите туда.
 Alexey
Alexey
посмотрите команды zfs send [poolname]/[dataset | volume]
и zfs receive [poolname]/[dataset | volume]
например, есть zfs volume: zp1/windows-disk. Его нужно перенести в пул zp2, тогда общая команда:
zfs send zp1/windows-disk | zfs receive zp2/windows-disk
жюн
А если диск клонировать на больший и резайнуть раздел zfs'a после загрузчика до максимума - оно же должно схавать это и увеличить размер пула
Александр
Что значит root пул? Всмысле там корень системы и там же диски виртуалок?
Тогда странное.
Ставьте отдельно диск под виртуалки и переносите туда.
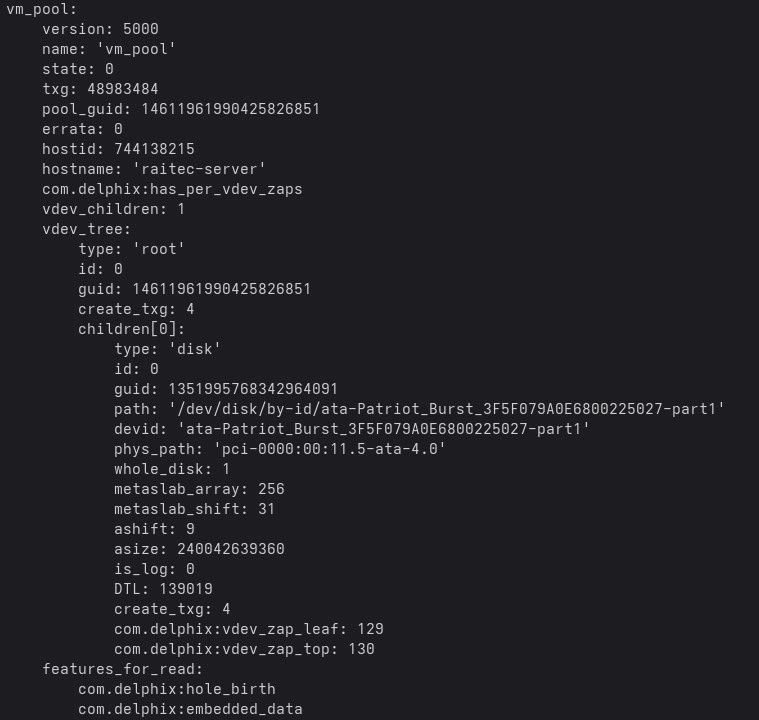 LordMerlin
LordMerlin
Красивое. пул из одного диска и ashift на ссд = 9
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
С коллегами спор зашёл. Благо ли zfs, или ж... и почему-то они уперто отстаивают позицию, что мол иные ФС проще восстановить, это раз. Два, то что если какая-то ошибка закроется, то все, данные потеряны и ничего не сделать. Отсюда вопрос, кто-то пытался как-то экспериментировать, какие-то кейсы, примеры восстановления итд есть?
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Мол если память не ecc, и произойдёт сбой, то будто бы целый датасет ляжет, но это будто бы не так. Но не уверен
Georg🎞️🎥
Мол если память не ecc, и произойдёт сбой, то будто бы целый датасет ляжет, но это будто бы не так. Но не уверен
Да все может лечь так то
Какая система гарантирует что что то точно восстановится интересно кстати
Vladislav
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Да все может лечь так то
Какая система гарантирует что что то точно восстановится интересно кстати
Ну мол аппаратный рейд проще восстановить)
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Это касается любой ФС
Где-то попадалась статья, где описывали теоретические расчёты, сколько и где битов должны сбойнуть, чтобы что-то пошло не так, вероятность низкая
Georg🎞️🎥
Помню … открыл коллега массив после сбоя питания , а он пуст девственно
Georg🎞️🎥
В прошлом году дело было
Железный рейд
Alexander
Мол если память не ecc, и произойдёт сбой, то будто бы целый датасет ляжет, но это будто бы не так. Но не уверен
Примеры восстановления можно в и-нете посмотреть. для примера - https://www.lissyara.su/articles/freebsd/file_system/zfs_recovery/
В целом, не думаю, что как-то принципиально отличается от восстановления других FS.
Касательно памяти с чётностью, совсем никак не связано именно с zfs, т.к. ноги совсем из другого растут. Для примера, в эксплуатационной документации (согласованной с ФСБ)на железки с прграммными СКЗИ ( криптопровайдерами) необходимо пергружать не реже, чем раз в 3 дня (если память без чётности) и можно вообще не пергружать, если память с чётностью. Т.е. это просто следствие появления ошибок в памяти, безотносительно какой-либо файловой системы.
 Roman
Roman
Roman
Roman
Что не отменяет того факта, что с битой памятью у тебя будет повреждение обычной фс.
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Тесты хочу придумать какие-то, но будто бы кого не убедить, того не убедить
Nik
Так то и образ любой ляжет, без есс легко, суть то в самой есс, разве нет?
Nik
А может и работать, но кривые данные могут в БД записаться, как и везде без есс.
Nik
Для зфс есть другие плюсы без есс это отправка снапшотов например, сжатие
 Fedor
Fedor
имхо больше вероятности битфлипов с коллизиями чексумм пакетов при передаче данных по нешифрованным каналам (без проверки hmac/etc).
что касается ецц и зфс - так же имхо - если требуется условно абсолютная достоверность данных, то зфс вместе с ецц тут хорош тем, что он либо обеспечит эту достоверность, либо сигнализирует о том, что данные больше не равны чексумме и восстановит данные их резервного блока, в котором сумма сошлась.
sexst
Мол если память не ecc, и произойдёт сбой, то будто бы целый датасет ляжет, но это будто бы не так. Но не уверен
Жопа не в том, что сбой произойдёт - это статистика и ожидаемо.
Жопа когда он в важном месте произошел, а вы не задетектили и дальше пердолите этот битый кусок блоба
sexst
И, сюрприз! В этом кейсе большинство fs вам вообще ничего о самом факте ошибки не скажет в принципе. Даже если ecc
sexst
А убеждать не нужно. Есть ряд разных fs на разные случаи жизни. Волшебной таблетки нет
Vladislav
С коллегами спор зашёл. Благо ли zfs, или ж... и почему-то они уперто отстаивают позицию, что мол иные ФС проще восстановить, это раз. Два, то что если какая-то ошибка закроется, то все, данные потеряны и ничего не сделать. Отсюда вопрос, кто-то пытался как-то экспериментировать, какие-то кейсы, примеры восстановления итд есть?
Если речь про фичи - благо
Если речь про скорость работы - сильно (ОЧЕНЬ сильно) зависит
Если речь про надёжность... Скраб и на современных аппаратных рейдах есть. ZFS не избавляет от необходимости актуального бэкапа, он лишь может помочь в большинстве ситуациях не восстанавливать ВСЮ фс
sexst
Весь вопрос в том, даст ли вам профит корова с её особенностями, околобесплатные снэпшоты и сжатие данных
sexst
(дедупликация всё ещё для тех, чьи вкусы весьма специфичны)
 Arseniy
Arseniy
С коллегами спор зашёл. Благо ли zfs, или ж... и почему-то они уперто отстаивают позицию, что мол иные ФС проще восстановить, это раз. Два, то что если какая-то ошибка закроется, то все, данные потеряны и ничего не сделать. Отсюда вопрос, кто-то пытался как-то экспериментировать, какие-то кейсы, примеры восстановления итд есть?
Тут корректнее было бы проводить сравнение более аргументировано. О какой конкретно фс говорили коллеги? С чем сравнивали zfs? С btrfs, как самым близким аналогом?
Привязка в отношении ЕСС тут некорректна, нет у фс требований по применению памяти с коррекцией ошибок. Единственное, где такое встречается (по крайней мере я видел), в требования к ОС TrueNas. Там настоятельно рекомендуют есс. И дело тут не в саой фс, а в том, что эта ОС ориентирована на организацию хранилища данных. А что нам нужно от хранилища? Достоверность и отказоустойчивость.
Условно, можно все сделать на аппаратном raid, обеспечить должный уровень отказоустойчивости. Будет ли обеспечена этим достоверность данных? Нет.
Что же по zfs, то тут всегда вопрос конкретных задач, которые необходимо решать, и доступности инструментов.
Vladislav
Стоп. Гипер без ecc?
Vladislav
Хотя бы ddr5?
Станислав
Да про есс мне так накидали думаю, до кучи
просто на форумах столетней давности начитались глупостей, теперь умничают
 Free
Free
UFS Explorer
Мне не помог.
Как я понял - он показал бы файлы, которые были, например, удалены.
В моем случае испортился (не читался средствами zfs - и соответственно UFS Explorer тоже) сам файл папки.
И ничего под ней восстановить не удалось
 Pavel
Pavel
Мол если память не ecc, и произойдёт сбой, то будто бы целый датасет ляжет, но это будто бы не так. Но не уверен
Как я понимаю и ECC ни от чего не гарантирует, все эти механизмы только снижают вероятность ошибок в данных, но ни от чего не гарантируют.
Даже контрольные суммы блоков не гарантируют, нужно грубо говоря умножить вероятность ошибки на число блоков в пуле и можно понять сколько блоков будет с ошибкой.
Georg🎞️🎥
Как я понимаю и ECC ни от чего не гарантирует, все эти механизмы только снижают вероятность ошибок в данных, но ни от чего не гарантируют.
Даже контрольные суммы блоков не гарантируют, нужно грубо говоря умножить вероятность ошибки на число блоков в пуле и можно понять сколько блоков будет с ошибкой.
А где вообще что то гарантируется ?
Vladislav
Как я понимаю и ECC ни от чего не гарантирует, все эти механизмы только снижают вероятность ошибок в данных, но ни от чего не гарантируют.
Даже контрольные суммы блоков не гарантируют, нужно грубо говоря умножить вероятность ошибки на число блоков в пуле и можно понять сколько блоков будет с ошибкой.
Гарантирует исправление 1 и обнаружение 2
Vladislav
Как я понимаю и ECC ни от чего не гарантирует, все эти механизмы только снижают вероятность ошибок в данных, но ни от чего не гарантируют.
Даже контрольные суммы блоков не гарантируют, нужно грубо говоря умножить вероятность ошибки на число блоков в пуле и можно понять сколько блоков будет с ошибкой.
Скажем так. Вероятность, что у тебя
Случится 3 ошибки ECC памяти, которая приведёт к изменению файла таким образом, что его контрольная сумма не изменится... Ну... Сомнительно реализуемая
Vladislav
Пока речь не идёт про объёмы в 12-18 петабайт и объёма оперативной памяти в 2-3 петабайта
Vladislav
на один сервер
Pavel
Пока речь не идёт про объёмы в 12-18 петабайт и объёма оперативной памяти в 2-3 петабайта
1000 серверов с терабайтом уже петабайт :)
Vladislav
Потому что мы говорим про ECC ошибки в рамках одной планки
Ivan
хотите надежней - можно ram mirroring в биосе включить
Pavel
Потому что мы говорим про ECC ошибки в рамках одной планки
Мы же все равно говорим о вероятности, а не о гарантиях.
Можно посчитать на досуге, сколько нужно блоков памяти, чтобы с вероятностью 50% хотя бы в одном блоке памяти была не обнаруживаемая ошибка :)
Vladislav
Мы же все равно говорим о вероятности, а не о гарантиях.
Можно посчитать на досуге, сколько нужно блоков памяти, чтобы с вероятностью 50% хотя бы в одном блоке памяти была не обнаруживаемая ошибка :)
?
Нужно что одновременно 3 бита в одном запросе получили bitflip
Vladislav
В одной ячейке*
Pavel
?
Нужно что одновременно 3 бита в одном запросе получили bitflip
Ну и что? Это все равно вероятность
Vladislav
Ну и что? Это все равно вероятность
Плюс вероятность того, что они изменят файл именно так, что его контрольная сумма не поменяется
Vladislav
И это одновременные события, т.е. их надо перемножить
Vladislav
А теперь давай посмотрим на куда более вероятные ошибки - отказ одновременно 3 HDD дисков в raidz2
Pavel
Это зависит от того, в какой момент произошел флип. Если до расчета суммы, то просто данные будут кривые записаны
Vladislav
Это зависит от того, в какой момент произошел флип. Если до расчета суммы, то просто данные будут кривые записаны
Это универсальная ситуация для любой системы
Vladislav
у тебя пакет Ethernet может побиться так, что FCS сойдётся, а данные внутри уже нет
Vladislav
Мы сейчас именно в контексте ZFS и риска, что приносит скраб без ECC памяти
Vladislav
Мы сейчас именно в контексте ZFS и риска, что приносит скраб без ECC памяти
или в ситуации когда у тебя 3 bitflip в одной ячейке
Pavel
А теперь давай посмотрим на куда более вероятные ошибки - отказ одновременно 3 HDD дисков в raidz2
Это вообще высокая вероятность.
Тут мне статья попадалась, что вероятность восстановления RAID-5 с 16tb дисками после отказа одного близка к тому, что он не восстановится.
Vladislav
Это вообще высокая вероятность.
Тут мне статья попадалась, что вероятность восстановления RAID-5 с 16tb дисками после отказа одного близка к тому, что он не восстановится.
нуу. Реальность показывает обратное, я так скажу
 Khajiit
Pavel
Khajiit
Pavel
нуу. Реальность показывает обратное, я так скажу
Вот нашел ту статейку
https://habr.com/en/articles/820551/
Vladislav
Пиздёж чистой воды
Vladislav
По этой статье 82% raid5 массивов не могут восстановиться
Pavel
По этой статье 82% raid5 массивов не могут восстановиться
В той же статье ссылка, в общем можно конечно поспорить с расчетами, но зачем?
https://superuser.com/questions/1334674/raid-5-array-probability-of-failing-to-rebuild-array
Vladislav
В той же статье ссылка, в общем можно конечно поспорить с расчетами, но зачем?
https://superuser.com/questions/1334674/raid-5-array-probability-of-failing-to-rebuild-array
Потому что это игры в цифры, которые не соответствуют реальность
Vladislav
Когда реальность показывает что расчёты некорректны - значит где-то кто-то играет цифрами
 Denver
Denver
по моему мнению, избыточность должна в массиве составлять 2 диска. А насколько мне известно, у рейд 5 большие проблемы с надежностью. По крайней мере должен быть бэкап. Даже обязателен для всех уровней массивов. Тут вопрос больше о скорости восстановления при определенных условиях
Fedor
По этой статье 82% raid5 массивов не могут восстановиться
Встречал на практике с большими дисками один раз