 Alexey
Alexey


Так все-таки, постгрес какими блоками пишет в фс?
 Pavel
Pavel
Так все-таки, постгрес какими блоками пишет в фс?
8K таблицы, раньше было, если специально не пересобирать.
Alexey
Если выставить recordsize больше, чем 8к, то будут писаться блоки по 8к в любом случае.
Pavel
Если выставить recordsize больше, чем 8к, то будут писаться блоки по 8к в любом случае.
Хорошй вопрос, в студию 🙂
Мне кажется, что будет писать по размеру сжатой записи, кратной размеру блока устройства.
Alexey
Вы имеете в виду размер ashift?
Pavel
Вы имеете в виду размер ashift?
Расскажу как я это понимаю.
ashift это размер блока устройства, весь ввод вывод идет этими блоками, далее есть recordsize это логический размер блока на которые разбивается большой файл, допустим 128К если вы модифицируете кусок файла в середине, перезапишется весь блок соответствующий recordsize. Однако есть еще и сжатие, записываемый блок сжимается и занимает определенное число физических блоков которые ashift размером.
Pavel
Вы имеете в виду размер ashift?
Если типа без учета сжатия Postgres пишет страницами в таблицы по 8к. Если у Вас размер записи 128К то на диск будет писаться 128К
Большой размер блока сокращает размер метаданных и фрагментацию, маленький экономит на рамере записи но требует больше метаданных и способствует фрагментации.
 Vladislav
Vladislav
Если типа без учета сжатия Postgres пишет страницами в таблицы по 8к. Если у Вас размер записи 128К то на диск будет писаться 128К
Большой размер блока сокращает размер метаданных и фрагментацию, маленький экономит на рамере записи но требует больше метаданных и способствует фрагментации.
Just in case Фрагментация в zfs бессмысленное понятие
Vladislav
Для всех RoW систем это там
Alexey
Если типа без учета сжатия Postgres пишет страницами в таблицы по 8к. Если у Вас размер записи 128К то на диск будет писаться 128К
Большой размер блока сокращает размер метаданных и фрагментацию, маленький экономит на рамере записи но требует больше метаданных и способствует фрагментации.
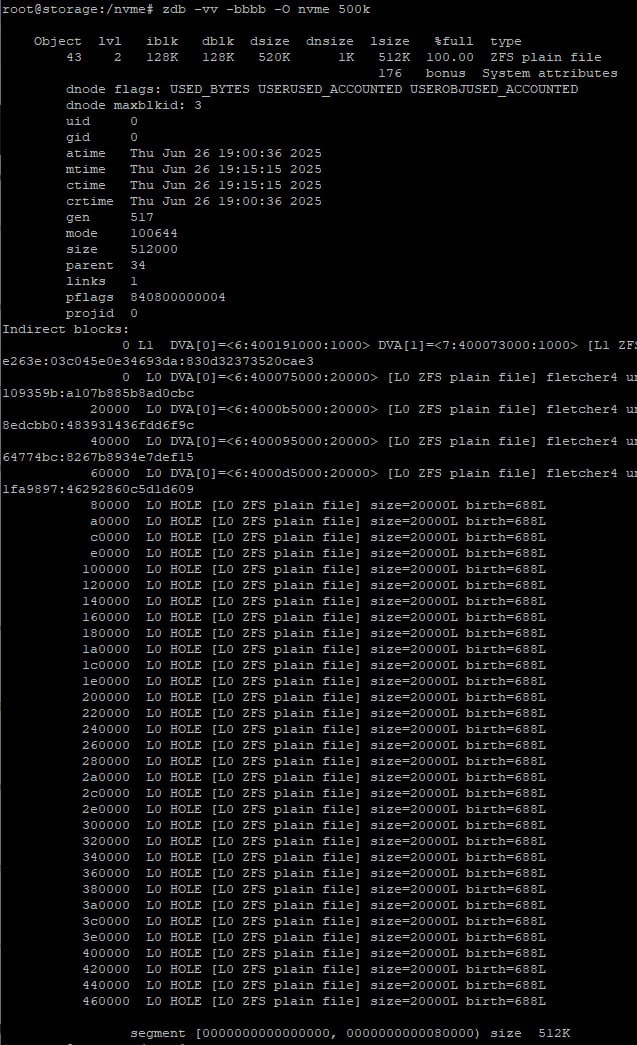
В документации написано, что блок меньшего размера, чем рекордсайз будет записан как есть, те не будет занимать в пуле 128кб. А так, вроде верно.
Alexey
при поверхностном поиске, вот что выдала алиса:
Как работает
Размер блока зависит от размера файла:
Если файл меньше или равен recordsize, он хранится как один логический блок его размера, округлённый до ближайшего кратного 512 байтам.
Если файл больше recordsize, он делится на несколько логических блоков по recordsize каждый, при этом последний блок дополняется нулями до recordsize.
Alexey
https://docs.oracle.com/cd/E26505_01/html/E37386/chapterzfs-db1.html
Alexey
видимо ashift=9
Vladislav
Оно округляется до ближайшей степени 2
Vladislav
60кб округлятся до 64кб
Vladislav
К примеру, 66048 как бэ кратно 512, но никак не соотносится с реальностью
 Fedor
Fedor
при поверхностном поиске, вот что выдала алиса:
Как работает
Размер блока зависит от размера файла:
Если файл меньше или равен recordsize, он хранится как один логический блок его размера, округлённый до ближайшего кратного 512 байтам.
Если файл больше recordsize, он делится на несколько логических блоков по recordsize каждый, при этом последний блок дополняется нулями до recordsize.
Любые ответы от ИИ, включая Алису, включая любую суммаризацию запрещены - нейронки часто додумывают того, чего нет.
Vladislav
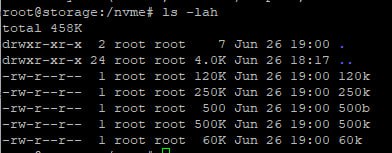 Vladislav
Vladislav
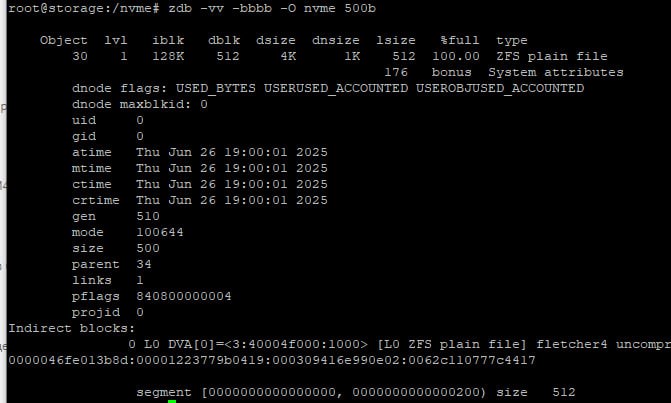 Vladislav
Vladislav
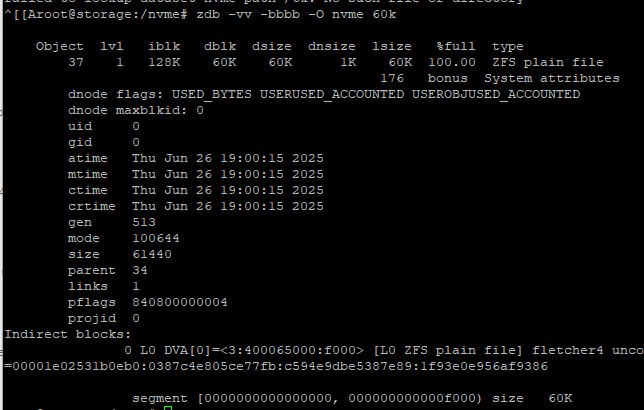 Vladislav
Vladislav
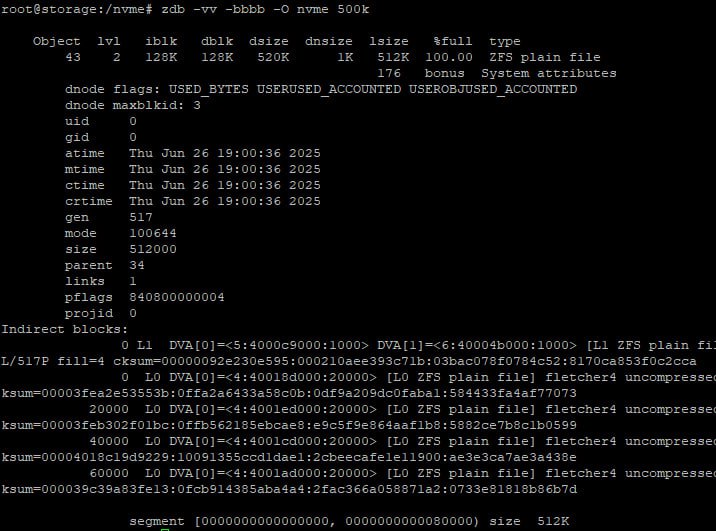 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
при поверхностном поиске, вот что выдала алиса:
Как работает
Размер блока зависит от размера файла:
Если файл меньше или равен recordsize, он хранится как один логический блок его размера, округлённый до ближайшего кратного 512 байтам.
Если файл больше recordsize, он делится на несколько логических блоков по recordsize каждый, при этом последний блок дополняется нулями до recordsize.
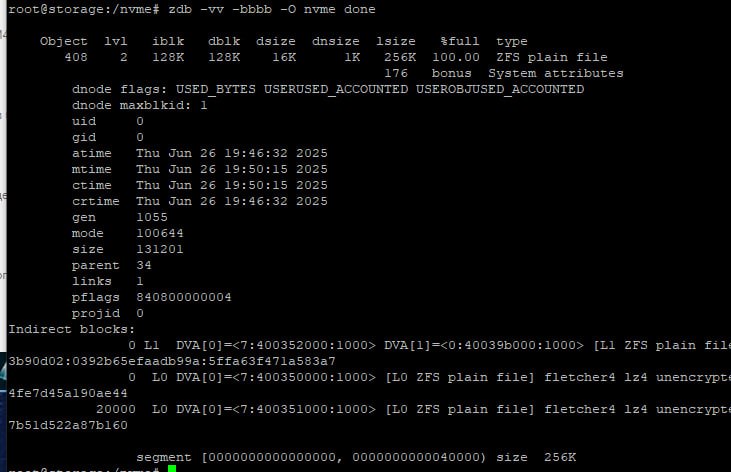
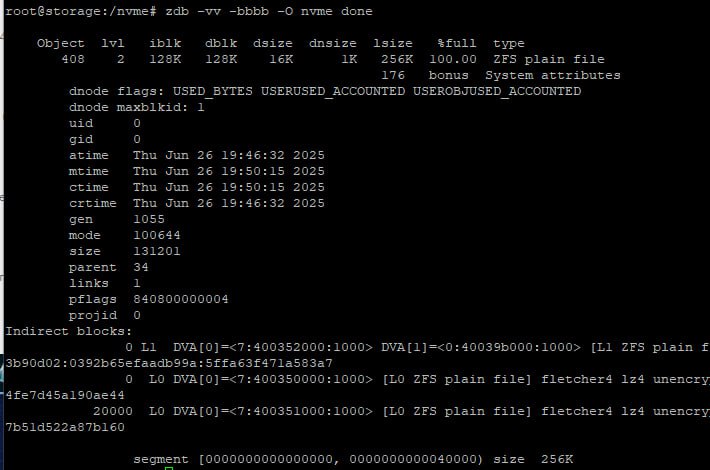
tl;dr
нейронка корректно сказала вот эту часть, но это влияет на итоговый размер файла примерно никак
Vladislav
Vladislav
Потому что если используется рейд, то dsize (собственно размер, который занимает файл) уже зависит от паддинга и насколько красиво он ложится на количество дисков, а dblk особо не имеет значения судя по подсчётам свободного места
Vladislav
Больше можно тут почитать:
https://utcc.utoronto.ca/~cks/space/blog/solaris/ZFSFilePartialAndHoleStorage
Alexey
Спасибо
Pavel
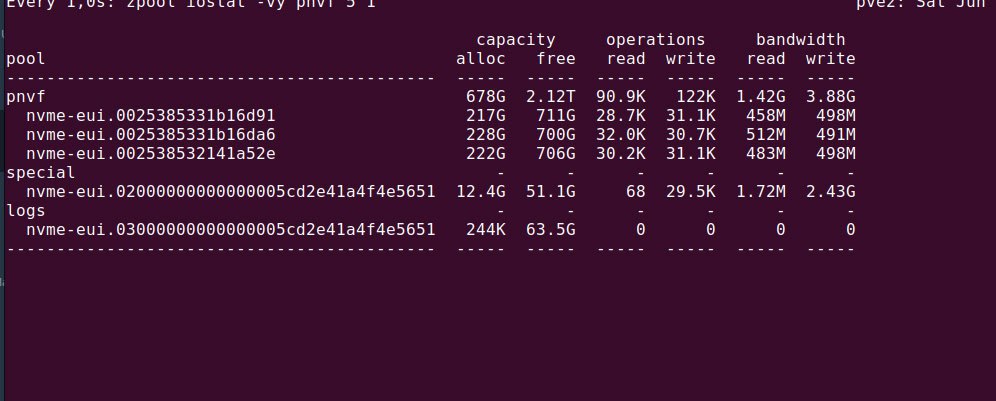
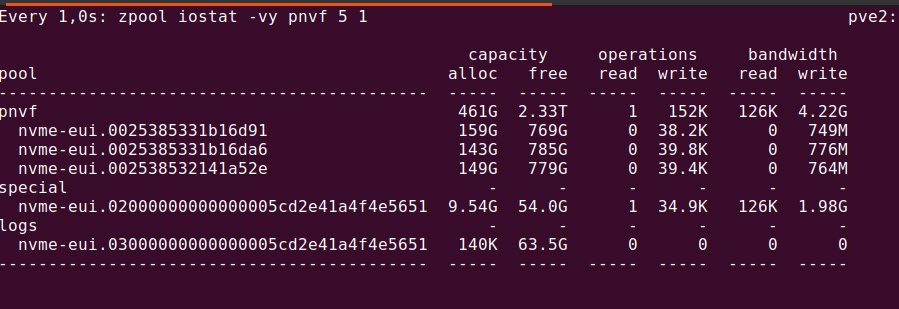
Более интересная картина, если добавить special устройство
Pavel
 Pavel
Pavel
Видно, что bandwidth предположительно метаданных превышает bandwith данных и съедает всю возможную полосу по записи моего nvme.
Pavel
Скорость записи fio с блоком 4К при этом около 380 MB/S при 80kiops, что примерно бьется с размером блока 16КБ на volume
Pavel
Скорость записи fio блоком 16k тоесть равным размеру блока диска составил 1200MB/S при тех же 80kiops, то есть понятно, что полезных данных пишется в 4 раза больше, что тоже ожидаемо.
Pavel
Ну а при записи блоками 64к объем записываемых метаданных начинает снижаться, в то время как объем записи данных повышается.
Pavel
 Artem
Artem
Продолжайте вести наблюдение
Pavel
Продолжайте вести наблюдение
Ну мне было интересно, почему так все плохо с моим пулом, ответ я получил, ну и вопрос про количество записываемых данных, я вроде тоже примерно понял.
К сожалению в сети не нашел данных по потреблению CPU и объему ввода-вывода.
На этом наблюдение заканчиваю :)
 Free
Free
Я понимаю, что zpool может не найти файлы, в которых были ошибки (например, если ошибки в метаданных) - но пул то СУЩЕСТВУЕТ (и реально работает)
root@PC121 ~# zpool status w18.1
pool: w18.1
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: resilvered 1.84M in 00:00:03 with 0 errors on Sun Jun 1 22:03:34 2025
config:
NAME STATE READ WRITE CKSUM
w18.1 ONLINE 0 0 0
ata-WDC_WUH721818ALE6L4_3GG55YSE ONLINE 0 0 0
errors: 1977 data errors, use '-v' for a list
НО:
root@PC121 ~# zpool status -v w18.1
pool: w18.1
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: resilvered 1.84M in 00:00:03 with 0 errors on Sun Jun 1 22:03:34 2025
config:
NAME STATE READ WRITE CKSUM
w18.1 ONLINE 0 0 0
ata-WDC_WUH721818ALE6L4_3GG55YSE ONLINE 0 0 0
errors: List of errors unavailable: no such pool or dataset
 Ю
Ю
 Ю
Ю
ну или задам так вопрос:
Если создам ручной снимок для этого действия. Перенесу данные по этому ручному снимку. Снимки которые созданы были по заданиям перенесуться или нет ?
Станислав
ну или задам так вопрос:
Если создам ручной снимок для этого действия. Перенесу данные по этому ручному снимку. Снимки которые созданы были по заданиям перенесуться или нет ?
Добрый день. Лучше напишите, что хотите получить
Ю
Дома стоит трунас core. Второй такой же стоит в гараже. Гаражный на мобильной сети живет.
У меня работал бэкап. Данные из дома реплицировались по заданию снимков (снимки создавались каждые три часа) в гараж.
В заданиях снимков было указано время жизни "две недели". Но жизнь показала что это было моей ошибкой 😁 Короче вспышку профукал, когда чухнулся, прошел месяц, репликация не ожила.
Т.к. данных 500 гигов и пересылать через мобильную сеть это извращение, хочу сделать как в прошлый раз.
реплицирую на HDD, приезжаю в гараж, реплицирую в пул с диска и потом уже запускаю репликацию из дома в гараж напрямую.
В прошлый раз не было снимков созданных ранее. Реплицировал первый снимок задания создания снимков.
А сейчас есть куча снимков из трех заданий создания.
Надеюсь меня поняли )
Ю
Через вэб морду это всё сделать элементрано, но мне надо чрез терминал это всё запустить.
Ю
Так тоже можно.
Ключевое в этом всём для меня, определить какую команду выполняет вэб морда и забить ее руками в терминале.
 George
George
bcachefs может стать похожей на zfs:) правда не в том свете в котором вы подумали https://t.me/yetanotherit/47
George
Alexey
Коллеги, у кого-то осталась копия статьи по использованию raidz массивов и табличка, как используется дисковое пространство: при каком кол-ве дисков, какой raidz, recordsize...
Статья на английском, называлась как-то "Как перестать бояться zfs..." что-то типа такого.
George
Коллеги, у кого-то осталась копия статьи по использованию raidz массивов и табличка, как используется дисковое пространство: при каком кол-ве дисков, какой raidz, recordsize...
Статья на английском, называлась как-то "Как перестать бояться zfs..." что-то типа такого.
оригинальную в вебархиве можно поискать, вот более короткая статья и та самая табличка (копия) https://openzfs.github.io/openzfs-docs/Basic%20Concepts/RAIDZ.html
Vladislav
Коллеги, у кого-то осталась копия статьи по использованию raidz массивов и табличка, как используется дисковое пространство: при каком кол-ве дисков, какой raidz, recordsize...
Статья на английском, называлась как-то "Как перестать бояться zfs..." что-то типа такого.
https://www.delphix.com/blog/zfs-raidz-stripe-width-or-how-i-learned-stop-worrying-and-love-raidz
https://web.archive.org/web/20250000000000*/https://www.delphix.com/blog/zfs-raidz-stripe-width-or-how-i-learned-stop-worrying-and-love-raidz
Alexey
Станислав
И расширение для браузера socks5 proxy
 Denver
Denver
Можно просто Тор браузер запустить
Alexey
спасибо за советы
жюн
Вопрос по механике:
Если нвме поделить на несколько неймспейсов и в рейд0 соединить потом - будет больше иопсов?)
Vladislav
Вопрос по механике:
Если нвме поделить на несколько неймспейсов и в рейд0 соединить потом - будет больше иопсов?)
Хм, в теории, учитывая, что zfs наплодит доп процессов на запись - да
Vladislav
Но немного
Vladislav
Может 5%
жюн
Может 5%
Не меряли, случаем, на нескольких отдельных дисках рейд0 сколько даёт по иопсам прибавки?
жюн
@DanteAvalon а как побенчить zvol корректно?
Vladislav
@DanteAvalon а как побенчить zvol корректно?
Делаешь nvme на два ns, делаешь из них zpool create nvme1 /dev/nvme0n1 /dev/nvme0n2
Ну а дальше что тебе больше надо, файлы/zvol
жюн
Делаешь nvme на два ns, делаешь из них zpool create nvme1 /dev/nvme0n1 /dev/nvme0n2
Ну а дальше что тебе больше надо, файлы/zvol
Да мне больше параметры fio интересны
Vladislav
Да мне больше параметры fio интересны
Ну так, какие тебе нужны значения
Как вариант можно в лоб взять бенч Виталия
Denver
Только недавно прочитал, что не все модели nvme поддерживают разделение на namespace
Pavel
Только недавно прочитал, что не все модели nvme поддерживают разделение на namespace
А мне наоборот казалось, что очень мало кто поддерживает :)
Ещё реже SR-IOV
Denver
А мне наоборот казалось, что очень мало кто поддерживает :)
Ещё реже SR-IOV
Всё верно. Могут не только лишь все, не каждый может это делать. (с)
Vladislav
А мне наоборот казалось, что очень мало кто поддерживает :)
Ещё реже SR-IOV
Все Enterprise grade поддерживают