Для теста выруби mitigations + C states
Вот эти слова мне не знакомы
 Pavel
Pavel


 Vladislav
Vladislav
 Pavel
Pavel
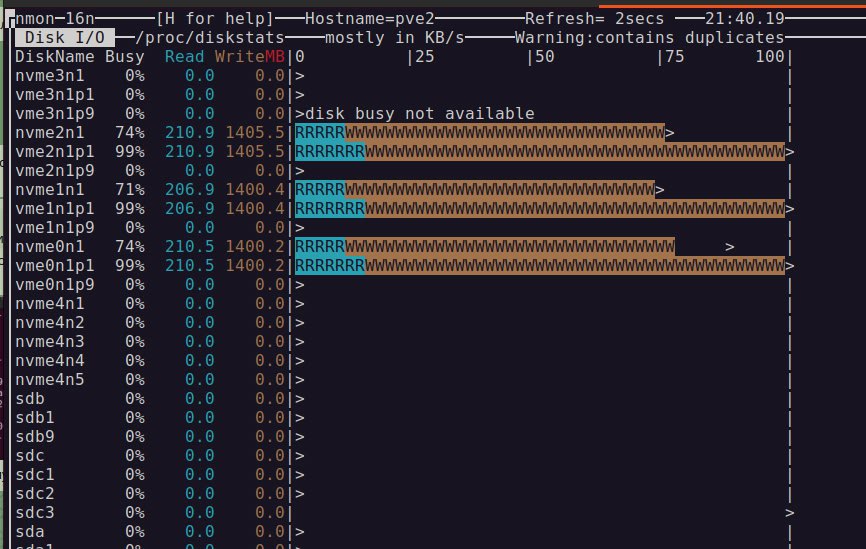
Итого, какие цифры тебе fio показал?
fio в тесте 100к
fio диска одного напрямую 34k, но CPU при 5% максимум
Vladislav
Цифры показывают что упёрся в скорость nvme
Vladislav
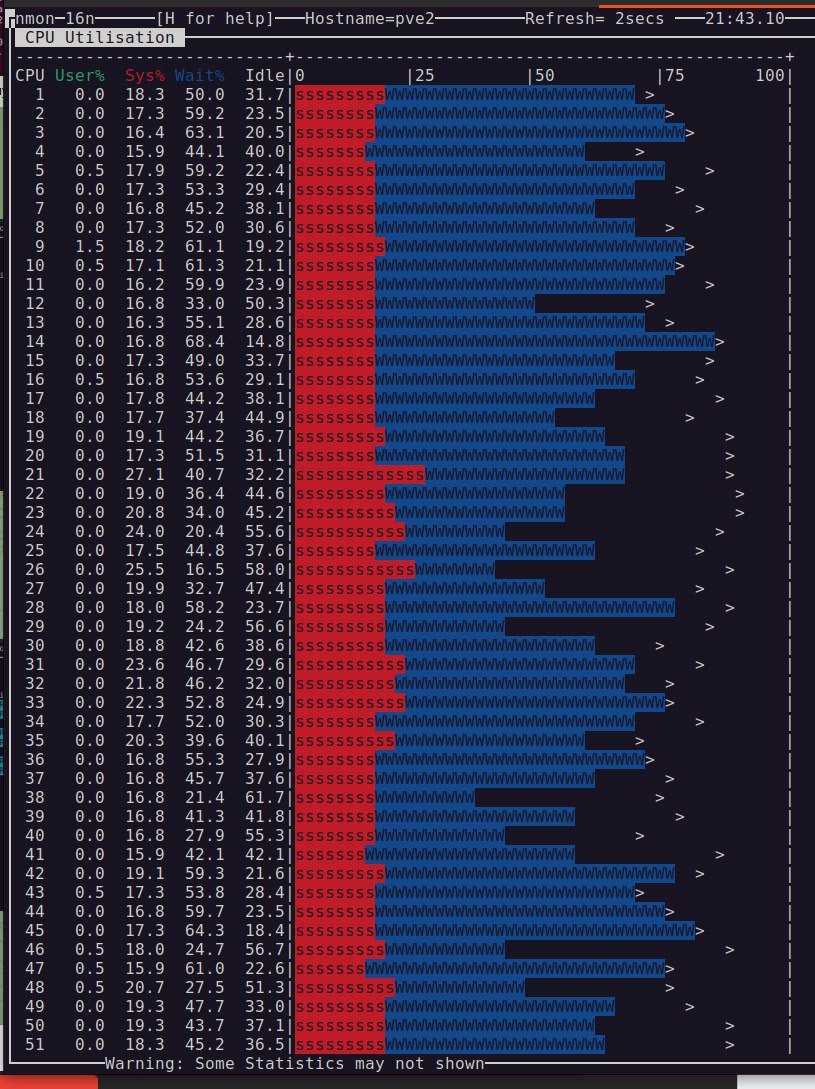
Это я примерно понимаю, меня пугает CPU
Создай из 3-х nvme mdadm raid0 и попробуй пописать на них
И сравни картину
Vladislav
 Vladislav
Vladislav
Можешь ещё mitigations вырубить, и проверить
Vladislav
Делаешь эти 4 проверки, приходишь с показателям
Pavel
Создай из 3-х nvme mdadm raid0 и попробуй пописать на них
И сравни картину
Я пробовал LVM c чередованием там 10% на тонком томе
И пробовал ZFS на одной nvme результат по CPU похожий.
 Nik
Nik
 Vladislav
Vladislav
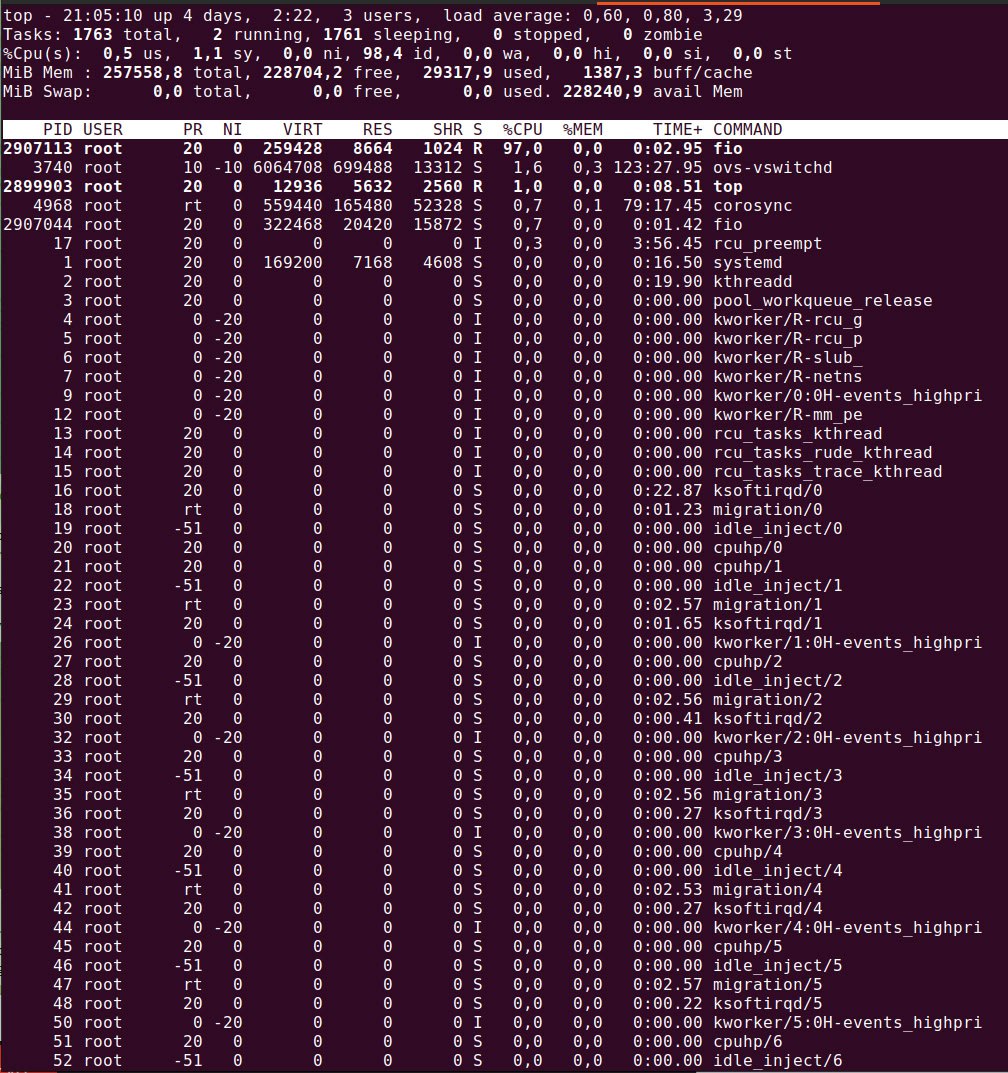
Вижу у вас высокий wa и sy, у меня именно в cpu нагрузка была, а не sy, тут в дисках проблема то похоже.
Диски там в лимит работают, 1400-1500 это скорость 860 Evo когда кэш заканчивается
Vladislav
А кэш там 10 или 30 Гб
Vladislav
Pavel
Меня больше интересует, насколько сильно mitigations влияют на memcopy, что CPU wait% на 30-45% на всех ядра
У меня ещё два optane по 32 gb два по 64gb, они более стабильны в смысле iops
Могу на них тоже протестить, но по-моему картина была похожей.
Vladislav
жюн
Так, мужики, проконсультируйте, пожалуйста:
Я сделал пул без thin provisioning, смигрил туда кучу волюмов ВМок
Сейчас включил thin provisioning на сторадже
Собс-на вопрос: можно наживую как-то трим сделать, чтобы волюмы вернули неиспользуемое место?
Vladislav
Только перезаписать их заново
Ivan
zfs set refreservation none имяzvol
Ivan
придется пройтись по всем дискам вм. если внутри вм трим настроен, то через некоторое время будет занято столько сколько занято внутри вм или даже меньше за счет сжатия.
 George
George
Не зря на конфу съездил :) принесу вам интересного https://t.me/yetanotherit/46
Vladislav
George
Даже на 100Г rdma?
Такое сложновато между геораспределёнными цодами кинуть, но, как ни странно, да - 100гбит полоса это всего несколько хороших нвме на запись 12.5гбайт/сек
Pavel
Не зря на конфу съездил :) принесу вам интересного https://t.me/yetanotherit/46
А можете объяснить как размер 32К связан с параметрами сети?
Ну в смысле что я понимаю размер кратный MTU, а откуда цифры 32 и 128?
George
А можете объяснить как размер 32К связан с параметрами сети?
Ну в смысле что я понимаю размер кратный MTU, а откуда цифры 32 и 128?
Имеется в виду средний размер операции логической на уровне бд, что итого за такую операцию может в среднем передаться по сети/записаться на диск Х кбайт
Pavel
Имеется в виду средний размер операции логической на уровне бд, что итого за такую операцию может в среднем передаться по сети/записаться на диск Х кбайт
Я может не до конца понял. Вы пишете «размер записи надо выставлять равный среднему размеру IO по сети»
Так все таки, что нужно тюнить и как?
Как я понимаю, если речь о репликации между ДЦ, то в силу высокой задержки данные лучше отдавать большим пакетом, чем много маленьких, так мы экономим на латенси.
Если речь идет о Postgres и передаче WAL, то вопрос а как это связано с размером записи FS? Или речь именно о папке WAL, там наверное да, лучше если размер записи будет совпадать со средним размером транзакции.
Vladislav
Такое сложновато между геораспределёнными цодами кинуть, но, как ни странно, да - 100гбит полоса это всего несколько хороших нвме на запись 12.5гбайт/сек
Это как бы нифига себе, учитывая, что их надо в массив, а даже самые лучшие диски сейчас это что-то около 4Г(?)
George
Это как бы нифига себе, учитывая, что их надо в массив, а даже самые лучшие диски сейчас это что-то около 4Г(?)
А вот тут и та самая (не)очевидность про сторадж) бд то в кластере геораспределённом, там уже есть избыточность
Vladislav
А вот тут и та самая (не)очевидность про сторадж) бд то в кластере геораспределённом, там уже есть избыточность
Избыточность избыточностью, но использовать страйп под БД идея будто "от зумеров" no offense
George
Избыточность избыточностью, но использовать страйп под БД идея будто "от зумеров" no offense
суть в том, что даже этот вырожденный случай со 100гбит между дальними цодами реально сделать узким местом. Обычно между геораспределёнными цодами будет меньше полосы в разрезе на один кластер БД
George
Избыточность избыточностью, но использовать страйп под БД идея будто "от зумеров" no offense
это ты ещё тарантуловцев не слышал :) где "синхронная запись на диск не нужна"
Vladislav
суть в том, что даже этот вырожденный случай со 100гбит между дальними цодами реально сделать узким местом. Обычно между геораспределёнными цодами будет меньше полосы в разрезе на один кластер БД
Даже если брать 25Г, это ~2.3Г на запись, что полностью равносильно pm9a3
Если кидать линк 1Г, то тогда да, сторадж не становится узким местом уже лет 10
Vladislav
это ты ещё тарантуловцев не слышал :) где "синхронная запись на диск не нужна"
.....к счастью не слышал
George
.....к счастью не слышал
но вообще в распределёнках это всё чаще, тот же клик по дефолту без фсинка
 sexst
sexst
это ты ещё тарантуловцев не слышал :) где "синхронная запись на диск не нужна"
Учитывая, что оно всё-таки больше in-memory, а vinyl там по остаточному принципу - ну да, не нужна
 Artem
Artem
Artem
Artem
?
Нет?
D7-PS1010 - 4100 МБ/с в идеальных условиях, когда он чистый
Да вот же например
https://servernews.ru/1124686
 Vladislav
Vladislav
Я про то, что сейчас есть на рынке
Vladislav
С тем же успехом можно говорить
А через 10 лет будет 400Г и PCIe 8.0
Vladislav
Ближайшее что я вижу из доступного в продаже это Micron 9550
Artem
Да ищещь любой PCIe 5 диск и смотришь спеки. А 400Г хорошо, но между дц такое
 Vladislav
Vladislav
Да ищещь любой PCIe 5 диск и смотришь спеки. А 400Г хорошо, но между дц такое
Сейчас да
10 лет назад 25Г между цодами было *но между ДЦ такое*
Artem
Но вообще ситуация скорее, что сетевушки норовят упереться в х16, а диски в х4. Ну и дальше перебираем поколения PCIe
Vladislav
Но вообще ситуация скорее, что сетевушки норовят упереться в х16, а диски в х4. Ну и дальше перебираем поколения PCIe
Ещё раз, все диски о которых ты говоришь - в статусе *анонсировали, ждите*
Artem
Ещё раз, все диски о которых ты говоришь - в статусе *анонсировали, ждите*
То есть пока ни одного серверного харда на PCIe 5 не сделали и обкатывают только на десктопах?
Vladislav
И не стоит забывать, что это мы берём за основу, что БД умеет в шардирование независимых дисков (я надеюсь я правильный термин использовал, поправьте если что), если на это заложить ещё программный Raid, то тут дискам до 100Г довольно долгий маршрут идти (исключение это VSAN, но тут кейс не про него)
Если же снизу Dorado 8000, то тогда да, ситуация меняется
Vladislav
То есть пока ни одного серверного харда на PCIe 5 не сделали и обкатывают только на десктопах?
Сделали, я выше кинул
Только там скорость 4.1Г
Artem
The D7-PS1030 is rated for sequential read speeds of up to 14,500 MB/s and 9,300 MB/s write; random IO reaches 2750K IOPS for read and 380K for writes.
Vladislav
The D7-PS1030 is rated for sequential read speeds of up to 14,500 MB/s and 9,300 MB/s write; random IO reaches 2750K IOPS for read and 380K for writes.
Это который mixed usage? (1.6\3.2\6.4\12.8)
Vladislav
Да, это он
Vladislav
Окей
Vladislav
The D7-PS1030 is rated for sequential read speeds of up to 14,500 MB/s and 9,300 MB/s write; random IO reaches 2750K IOPS for read and 380K for writes.
Тогда вот он диск, который нужен, чтобы покрыть 100Г канала
Vladislav
The D7-PS1030 is rated for sequential read speeds of up to 14,500 MB/s and 9,300 MB/s write; random IO reaches 2750K IOPS for read and 380K for writes.
 Artem
Artem
Главный момент - бд вроде как не всегда страдают линейно
Vladislav
Главный момент - бд вроде как не всегда страдают линейно
Это нюанс
Как и рейд
Как и то, что диск не всегда идеально чистый
Как и синки
Vladislav
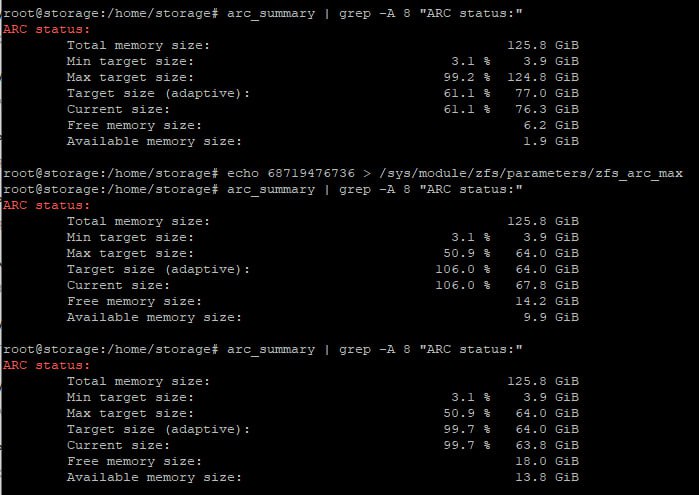
Кстати, в 2.3 поменяли zfs_arc_max
Теперь значение 0 это вся доступная память, а не 1/2
https://github.com/openzfs/zfs/issues/17052#issuecomment-2669075152
Vladislav
https://github.com/openzfs/zfs/pull/15437
 Andrey
Andrey
Убивать бы за такое
Andrey
Профит только в узкоспециализированном сегменте
Vladislav
 Pavel
Pavel
Так, что по тестам?
Надо почитать что такое mitigations + C states и как их вырубить.
Думаю на выходных сделаю.
Я там ещё тесты подергал и в целом выяснил из-за чего все не очень. Просто в ZFS при рандом записи 4k под высокой нагрузкой объем записываемых метаданных превышает объем самих данных. Я добавил в пул отдельный special девайс на более менее нормальном nvme и все более менее зашевелилось.
Айтуар
А почему все пишут про полосу, но никто не упомянул про задержки. Какой смысл в канале на 100Гб если задержки будут секунды?
 Roman
Roman
Кстати, в 2.3 поменяли zfs_arc_max
Теперь значение 0 это вся доступная память, а не 1/2
https://github.com/openzfs/zfs/issues/17052#issuecomment-2669075152
и по умолчанию так же 0 ставит, не считает сам?
Станислав
Не зря на конфу съездил :) принесу вам интересного https://t.me/yetanotherit/46
А я уже год как стал использовать 32кб что для mysql, что для postgres😃 Правда не по причине подстройки под сеть