Что?
Модель ST22000NM002E-3HL113.
опечатка, ST16000NM003G-2K - это с другого сервера диски.
 Hennadii
Hennadii

 Hennadii
Hennadii
Я так понимаю это hetzner? Учитывая, что про восстановление или какие сетевые адаптеры (и смогут ли они прокачать этот трафик) пока что нет ни слова
Я так понимаю это hetzner?
Да, это Hetzner, модель сервера SX135.
SX295 примерно в два раза дороже и пока что для этой задачи должно хватить и возможностей сервера SX135.
- и надеюсь это хотя бы Asrock \ Supermicro материнска с IPMI?
ASUS Pro WS 565-ACE, но без IPMI.
IPMI там есть только в брендовых DELL-серверах с iDRAC9 Enterprise на борту.
во всех остальных серверах - поубирали и поотключали из соображений безопасности.
hxxps : // docs . hetzner . com / robot/dedicated-server/maintainance/ipmi/
Hetzner IPMI information
In 2019, we at Hetzner decided to no longer provide customers with additional IPMI or KVM modules to install on their dedicated root servers. There are two exceptions: DELL servers and DELL servers from the Server Auction. Just in case there is a fault, we have kept a few of these IPMI modules.
We decided to make this decision because of many security issues in the past. These vulnerabilities were the result of issues in the manufacturers' firmware, and unfortunately, it took the manufacturers a long time to fix the issues.
Учитывая, что про восстановление или какие сетевые адаптеры
(и смогут ли они прокачать этот трафик) пока что нет ни слова
I210 Gigabit Network Connection
Connection: 1 GBit/s-Port
Bandwidth guaranteed: 1 GBit/s
При необходимости - можно заапгрейдить до 10 GBit/s, но пока что такой необходимости нет, потому что данные приходят через incremental zfs send и сетевой трафик там не очень большой, сети в 1 гигабит вполне достаточно для текущих задач.
Hennadii
Есть только одна проблема. Время ребилда.
это не проблема, - диски выходят их строя не так часто и временная деградация производительности на время ребилда вполне допустима.
Hennadii
Ну и конечно же отсутствие hotspare и я не вижу ничего про мониторинг дисков
hotspare мне здесь не нужен, сбойный диск на новый в датацентре меняют достаточно быстро по заявке.
тем более, что здесь же RAIDZ2 vdev, так что этот сервер может пережить без потери данных даже одновременный выход из строя двух жестких дисков, поэтому я не вижу смысла здесь использовать hotspare.
мониторинг дисков стандартный, через zed и smartd.
man zed
man smartd
и zed и smartd присылают уведомление емейлом в случае проблем с каким-то из дисков.
 George
George
Здравствуйте, All!
Подскажите пожалуйста, как оптимальнее всего настроить сервер с ZFS, чтобы была прежде всего максимальная надежность хранения данных и вторым по приоритетности - максимальная скорость работы, но не в ущерб надежности и стабильности.
Технические параметры сервера
Процессор AMD Ryzen 9 3900 12-Core Processor
Память 128 GiB DDR4 ECC
Подсистема хранения 2 x 1.92 TB (Gen 3) NVMe + 8 x 22 TB SATA 6Gb/s 7200 rpm
Операционная система Rocky Linux 9.5 + zfs-2.1.16
Планирую сделать один RAIDZ2 vdev из всех этих 8 HDD каждый из которых имеет размер 20 TiB (или 22 TB, другими словами).
zpool create -o ashift=12 -O compression=lz4 -O atime=off -O xattr=sa -O acltype=posix tank raid2 ...
Это выделенный сервер у которого только одна роль - backup server, куда будут писаться через ssh zfs send ...| zfs recv ... в постоянном режиме все датасеты со всех серверов (постоянная репликация с паузой между повторными попытками в 10 минут). Датасеты с удаленных серверов - это в основном sparse zvol размером 64 TiB с volblocksize=16K и данными на XFS внутри zvol.
ARC займет своих 50% оперативной памяти или даже 80%.
L2ARC не вижу смысла вообще делать, потому что на этот сервер будут в основном только писать, а читать будут очень редко - когда надо будет что-то восстановить из резервных копий.
special device на NVMe тоже не вижу смысла делать, потому что это значительно уменьшит надежность файловой системы и увеличит ее хрупкость, даже если бы это и дало какой-то небольшой прирост производительности при записи на диски.
При такой конфигруации - если делать из 8 HDD на 20 TiB один RAIDZ2 vdev - два HDD уйдут на контрольные суммы и примерно 120 TiB будет доступного места на диске.
Если в такой конфигурации сервер не будет справляться с нагрузкой на запись - тогда наверное единственным вариантом будет сделать два RAIDZ2 vdev каждый по 4 диска, тогда на контрольные суммы уйдет 4 диска и полезный объем пула будет 80 TiB, но при этом - будет в два раза выше производительность дисковой подсистемы, потому что будет два RAIDZ2 vdev вместо одного.
RAIDZ3 vdev из 8 HDD наверное нет смысла делать, потому что это еще сильнее уменьшит производительность дисковой подсистемы по сравнению с RAIDZ2 vdev. А надежность у RAIDZ2 vdev вполне достаточная для выполнения этой задачи.
Что не могу пока что понять:
Если поставить logbias=throughput то в man странице написано, что в таком случае SLOG вообще не будет использоваться.
А если поставить logbias=latency (по умолчанию) тогда будет использоваться SLOG для записи synchronous requests.
Но не понятно, когда 100% операций записи на zfs pool производит команда zfs receive - есть ли тогда synchronous requests и какой именно размер SLOG будет самым оптимальным для такого zpool ?
Или имеет смысл просто поставить logbias=throughput и забыть про эту проблему с SLOG (он же ZIL) и L2ARC вообще?
Возможно есть еще какие-то варианты и способы как выжать максимум производительности из файловой системы ZFS на этом сервере, обладающего таким hardware, возможно про какие-то еще настройки zpool для оптимизации производительности я забыл ?
tuned profile на этом сервере установлен в network-latency - Optimize for deterministic performance at the cost of increased power consumption, focused on low latency network performance.
- для сервера бекапов вам релиз 2.2 точно ок уже, это же копии. Там была оптимизация перфа
- для канала в 1гбит/с вам много перфа и не надо, raidz2 не самый быстрый но чуть более надёжный, как вы и хотите
- т.к. вы будете пересылать снапшоты, то другой тюнинг и не нужен (он по бОльшей части игнорится и переопределяется для снапов присланных), лучше изучите как эффективнее zfs send-recv делать, посмотрите на ключи -Lec и тд, гляньте на какой-нибудь zrepl и его доку
 Vladislav
Vladislav
hotspare мне здесь не нужен, сбойный диск на новый в датацентре меняют достаточно быстро по заявке.
тем более, что здесь же RAIDZ2 vdev, так что этот сервер может пережить без потери данных даже одновременный выход из строя двух жестких дисков, поэтому я не вижу смысла здесь использовать hotspare.
мониторинг дисков стандартный, через zed и smartd.
man zed
man smartd
и zed и smartd присылают уведомление емейлом в случае проблем с каким-то из дисков.
Не стоит доверять смарту
Лучше доверяйте уровню задержки отклика от диска
George
- для сервера бекапов вам релиз 2.2 точно ок уже, это же копии. Там была оптимизация перфа
- для канала в 1гбит/с вам много перфа и не надо, raidz2 не самый быстрый но чуть более надёжный, как вы и хотите
- т.к. вы будете пересылать снапшоты, то другой тюнинг и не нужен (он по бОльшей части игнорится и переопределяется для снапов присланных), лучше изучите как эффективнее zfs send-recv делать, посмотрите на ключи -Lec и тд, гляньте на какой-нибудь zrepl и его доку
у zfs send -L как раз важен, если вы используете сжатие на источнике, чтобы данные как есть летели по сети а не разжимались.
Я видел у одного знакомого хостера кейс, когда коэффициент сжатия был 1800, 2Гбайта сжатых лились на сервер бекапа как несколько ТБ))
 Δαρθ
Δαρθ
у zfs send -L как раз важен, если вы используете сжатие на источнике, чтобы данные как есть летели по сети а не разжимались.
Я видел у одного знакомого хостера кейс, когда коэффициент сжатия был 1800, 2Гбайта сжатых лились на сервер бекапа как несколько ТБ))
Дык для разжатых данных по сети всегда есть ssh c компрессией или даже zstd в пайпе
Hennadii
- для сервера бекапов вам релиз 2.2 точно ок уже, это же копии. Там была оптимизация перфа
- для канала в 1гбит/с вам много перфа и не надо, raidz2 не самый быстрый но чуть более надёжный, как вы и хотите
- т.к. вы будете пересылать снапшоты, то другой тюнинг и не нужен (он по бОльшей части игнорится и переопределяется для снапов присланных), лучше изучите как эффективнее zfs send-recv делать, посмотрите на ключи -Lec и тд, гляньте на какой-нибудь zrepl и его доку
- для сервера бекапов вам релиз 2.2 точно ок уже, это же копии. Там была оптимизация перфа
Насколько большим может быть прирост производительности работы файловой системы после перехода с 2.1.16 на 2.2.7 ?
"оптимизации перфа" - да, но в плане стабильности и надежности работы - лучше когда и на продовых серверах и на бекапном сервере используется одинаковая версия zfs - тогда меньше будет возможных сюрпризов и возможных проблем.
Т.е. переход на 2.2 на бекапном сервере я понимаю как trade-off, когда увеличивается производительность путем уменьшения надежности.
Идти по такому пути не очень хочется, тем более, что я и так уже нарушаю правило бекапов 3-2-1, используя только zfs send | zfs recv для бекапов и два идентичных сервера в разных датацентрах для резервных копий, поэтому еще большее уменьшение надежности резервных копий - крайне нежелательно.
Я бы и рад не нарушать правило 3-2-1, но чем и куда кроме zfs send | zfs recv бекапить десятки и сотни sparse zvol размером по 64 TiB каждый? На каждом zvol - файловая система XFS и количество данных на каждом zvol примерно от 0 до 5 терабайт.
- т.к. вы будете пересылать снапшоты, то другой тюнинг и не нужен (он по бОльшей части игнорится и переопределяется для снапов присланных), лучше изучите как эффективнее zfs send-recv делать, посмотрите на ключи -Lec и тд, гляньте на какой-нибудь zrepl и его доку
видел, что
hxxps : // github . com / jimsalterjrs/sanoid
использует mbuffer для увеличения производительности.
Наверное использование mbuffer (низкий риск проблем) и использование ключей -Lec (средний/высокий риск проблем(?)) будет достаточными способами для повышения производительности, и мощности этого сервера после таких оптимизаций должно хватить для текущей нагрузки.
Сначала использовать mbuffer, но если этого будет не достаточно - тогда уже и -Lec придется включать.
у zfs send -L как раз важен, если вы используете сжатие на источнике, чтобы данные как есть летели по сети а не разжимались.
Так у меня де в основном используются zvol и там volblocksize=16К, так что откуда там могут появиться large blocks, которые больше чем 128К в размере?
тем более, что в документации предупреждается о возможных проблемах и data corruption, если с одной стороны указать ключ --large-block а с другой стороны - не указать:
https : // openzfs . github . io /openzfs-docs/Project%20and%20Community/FAQ.html#sending-large-blocks
Компрессию то включить можно, но основная статика - это картинки .jpg и тому подобные форматы - эти данные не сжимаемые вообще, так что включение компрессии при пересылке snapshot`ов особо какого-то выиграша в производительности не даст. Тем более, что они (снапшоты) создаются раз в час и объем данных для передачи, что накапливается за один час - сравнительно небольшой, тем более что там происходит incremental zfs send, то есть - передается только небольшой diff между двумя соседними снапшотами - так что весь траффик между основным и бекапным сервером равномерно размазан по времени и такая репликация происходит постоянно, 24 часа в сутки.
Сеть не является узким местом, потому что 1 гигабит - это примерно 100 мегабайт в секунду, такой пропускной способности должно хватить для нормальной работы. Меня больше интересует вопрос максимальной производительности дисковой подсистемы - чтобы выжать из RAIDZ2 vdev максимум возможной производительности, но не ценой снижения надежности.
Некоторые diff`ы между соседними снапшотами передаются буквально за несколько секунд или десятков секунд.
Просто дисковая под система бекапного сервера уже начинает не справляться с нагрузкой, когда на один бекапный сервер приходят данные с большого количества (несколько десятков) продовых серверов.
то есть - просто не хватает пропускной способности дисковой подсистемы в плане IOPS и дисковая подсистема тормозит:
Hennadii
- для сервера бекапов вам релиз 2.2 точно ок уже, это же копии. Там была оптимизация перфа
- для канала в 1гбит/с вам много перфа и не надо, raidz2 не самый быстрый но чуть более надёжный, как вы и хотите
- т.к. вы будете пересылать снапшоты, то другой тюнинг и не нужен (он по бОльшей части игнорится и переопределяется для снапов присланных), лучше изучите как эффективнее zfs send-recv делать, посмотрите на ключи -Lec и тд, гляньте на какой-нибудь zrepl и его доку
# zpool iostat 1
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
tank 135T 10.2T 1.55K 2.79K 19.0M 38.9M
tank 135T 10.2T 10 11.8K 148K 142M
tank 135T 10.2T 148 5.93K 962K 55.0M
tank 135T 10.2T 1014 8.82K 9.68M 68.5M
tank 135T 10.2T 95 12.2K 898K 114M
tank 135T 10.2T 69 7.54K 515K 86.6M
tank 135T 10.2T 194 11.6K 1.12M 75.6M
tank 135T 10.2T 50 6.80K 403K 40.0M
tank 135T 10.2T 198 10.7K 1.67M 107M
tank 135T 10.2T 360 8.24K 1.66M 53.5M
tank 135T 10.2T 222 17.4K 1.61M 174M
tank 135T 10.2T 93 9.92K 655K 82.7M
tank 135T 10.2T 94 12.3K 667K 124M
tank 135T 10.2T 133 10.1K 695K 86.5M
tank 135T 10.2T 78 5.83K 459K 63.1M
tank 135T 10.2T 228 8.58K 1.03M 67.3M
tank 135T 10.2T 161 8.44K 918K 81.4M
tank 135T 10.2T 92 11.7K 731K 102M
tank 135T 10.2T 372 6.38K 1.53M 66.6M
tank 135T 10.2T 407 10.5K 3.00M 90.9M
tank 135T 10.2T 614 7.13K 4.61M 65.4M
tank 135T 10.2T 301 3.60K 2.17M 25.7M
tank 135T 10.2T 58 4.21K 240K 44.0M
tank 135T 10.2T 194 8.09K 779K 77.4M
tank 135T 10.2T 365 7.10K 1.59M 64.6M
tank 135T 10.2T 617 8.90K 6.95M 63.9M
tank 135T 10.2T 196 6.01K 1.82M 62.2M
tank 135T 10.2T 329 2.71K 3.15M 32.4M
tank 135T 10.2T 166 3.53K 934K 40.1M
а загрузка по сети при этом не достигает 100%:
Disk IO: 261.6% read: 456K write: 68.3M
Network: rx: 23.2MiB/s tx: 167KiB/s (24355/3668 packets)
Disk IO: 415.2% read: 1.99M write: 99.4M
Network: rx: 91.3MiB/s tx: 515KiB/s (97014/11392 packets)
Hennadii
Не стоит доверять смарту
Лучше доверяйте уровню задержки отклика от диска
Вы предлагаете самостоятельно мониторить состояние
zpool iostat -pw
или каким способом Вы предлагаете "доверять уровню задержек отклика от диска" ?
так вроде бы подобные проверки уже встроены в файловую систему и это работает автоматически, и если какой-то диск из zfs pool будет очень медленно работать - ZED это должен увидеть и сообщить об этом, разве нет?
Hennadii
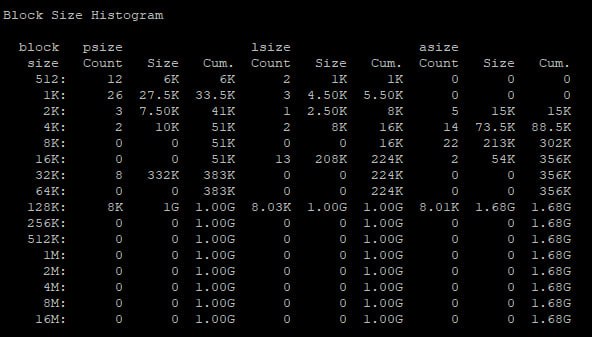
А Вы гляньте какие блоки у Вас сейчас записаны
16K размер блока.
# zfs get all tank/mirror/server-name/volume-name | grep vol
tank/mirror/server-name/volume-name type volume -
tank/mirror/server-name/volume-name volsize 64.0T local
tank/mirror/server-name/volume-name volblocksize 16K -
tank/mirror/server-name/volume-name volmode default default
 Станислав
Станислав
Так насколько я помню zfs не даёт создание degrade pool из одного диска. Или сейчас он уже это умеет?
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами? Вы пишите полную ересь, сами не читали доку, зато другого отправляете.
@serg78ant так, как вы хотели сделать изначально, можно сделать, не слушайте недоучек) Хотя Алексей уже дал инструкцию, как сделать
Vladislav
Вы предлагаете самостоятельно мониторить состояние
zpool iostat -pw
или каким способом Вы предлагаете "доверять уровню задержек отклика от диска" ?
так вроде бы подобные проверки уже встроены в файловую систему и это работает автоматически, и если какой-то диск из zfs pool будет очень медленно работать - ZED это должен увидеть и сообщить об этом, разве нет?
У Заббикса есть прекрасные готовые темплейты для этого если я не ошибаюсь
Vladislav
Вы предлагаете самостоятельно мониторить состояние
zpool iostat -pw
или каким способом Вы предлагаете "доверять уровню задержек отклика от диска" ?
так вроде бы подобные проверки уже встроены в файловую систему и это работает автоматически, и если какой-то диск из zfs pool будет очень медленно работать - ZED это должен увидеть и сообщить об этом, разве нет?
Он не должен ничего никому если это не настроено
Vladislav
16K размер блока.
# zfs get all tank/mirror/server-name/volume-name | grep vol
tank/mirror/server-name/volume-name type volume -
tank/mirror/server-name/volume-name volsize 64.0T local
tank/mirror/server-name/volume-name volblocksize 16K -
tank/mirror/server-name/volume-name volmode default default
Я про непосредственно какие блоки уже записаны в систему
Айтуар
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами? Вы пишите полную ересь, сами не читали доку, зато другого отправляете.
@serg78ant так, как вы хотели сделать изначально, можно сделать, не слушайте недоучек) Хотя Алексей уже дал инструкцию, как сделать
Вот так приходит кто-то считающий что знает больше чем ты, пусть даже если это и так, оскорбит и потом вообще не захочешь кому-то помогать в чате.
Можно же просто написать что человек ошибается, кажется так ведь учатся.
 Vladislav
Vladislav
Для примера
Станислав
Вот так приходит кто-то считающий что знает больше чем ты, пусть даже если это и так, оскорбит и потом вообще не захочешь кому-то помогать в чате.
Можно же просто написать что человек ошибается, кажется так ведь учатся.
Я всегда помогаю, так что не надо меня в этом обвинять. И даже предыдущее мое сообщение таковым является - помощью и вам, чтобы глупости не писали и людям, которые их прочитают. Я не просто считаю, что знаю в данном вопросе больше, а точно знаю, что вы ничего не понимаете в этом вопросе. Хотите, обижайтесь, не хотите, не обижайтесь)
George
Дык для разжатых данных по сети всегда есть ssh c компрессией или даже zstd в пайпе
не путайте, zfs send -L не сжимает, он не РАЗЖИМАЕТ если данные были сжаты и передаёт как есть, я про это
Hennadii
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами? Вы пишите полную ересь, сами не читали доку, зато другого отправляете.
@serg78ant так, как вы хотели сделать изначально, можно сделать, не слушайте недоучек) Хотя Алексей уже дал инструкцию, как сделать
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами? Вы пишите полную ересь, сами не читали доку, зато другого отправляете.
Да, действительно в файловой системе OpenZFS можно конвертировать pool состоящий из одного диска в mirror с помощью команды zpool attach - я об этом не знал раньше, потому что никогда не создавал zfs pool состоящий из одного диска, всегда с самого начала только mirror или raidz2 из нескольких дисков.
# man zpool attach
NAME
zpool-attach — attach new device to existing ZFS vdev
SYNOPSIS
zpool attach [-fsw] [-o property=value] pool device new_device
DESCRIPTION
Attaches new_device to the existing device. The existing device cannot be part of a raidz configuration. If device is not currently part of a mirrored configuration, device automatically transforms into a two-way mirror of device and new_device. If device is part of a two-way mirror, attaching new_device creates a three-way mirror, and so on. In either case, new_device begins to resilver immediately and any running scrub is cancelled.
Причем, такая возможность конвертации одиночного диска в mirror была даже в старой версии ZFS от Sun Microsystems, так что все версии OpenZFS это умеют делать - дизайн файловой системы ZFS даже лучше, чем я этого ожидал от нее изначально.
Для обычных файловых систем в Linux такая конвертация single disk в mrdaid RAID-1 mirror невозможна, потому что для mdraid необходимо дополнительное место на диске для metadata.
А в ZFS / OpenZFS такая возможность конвертации "на лету", оказывается предусмотрена уже изначально в дизайне файловой системы, с самого начала. Удобная возможность.
Спасибо, что указали на эту мою ошибку / неточность - я про эту возможность не знал раньше, теперь буду знать.
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами?
Вы пишите полную ересь
Тот способ, про который я написал в своем первом сообщении - он тоже рабочий, просто там есть несколько дополнительных (лишних) шагов, в которых, как теперь выяснилось, нет необходимости. Но способ тоже рабочий.
@makhomed и Александр И. Если не разбираетесь в вопросе, зачем лезть с советами?
А что не так с моим советом использовать Whole Disk для ZFS вместо ручного создания разделов для файловой системы?
Vladislav
Если ты не знаешь плюсов и минусов почему стоит\не стоит выдавать разделы вместо whole disk (хотя бы базовый /dev/disk/by-partuuid) - то не стоит высказывать это.
ИМХО - разницы никакой, но только если человек ПОНИМАЕТ почему он делает так, а не иначе
Hennadii
Пункт 1.
mdadm --create --verbose /dev/md0 --level=mirror --raid-devices=2 /dev/sdb1 missing
Пункт 2.
Raid0 —> Raid5 —> Raid1 допустимо
mdadm --create --verbose /dev/md0 --level=mirror --raid-devices=2 /dev/sdb1 missing
здесь с самого начала создается mdraid и соответственно - резервируется место под метаданные.
я говорил про тот случай когда есть только один диск, на нем - обычный раздел и на этом разделе уже создана файловая система и лежат данные.
в такой ситуации - конвертировать "на лету" single disk в mdraid невозможно.
Hennadii
Потому что это дело вкуса.
Человек не читал документацию, поэтому чем более классическое решение ему будет предложено - тем лучше.
С учётом остальных тейков с твоей стороны - *Плохой совет иногда хуже чем просто промолчать*
Vladislav Losev, [20.12.2024 14:43]
Потому что это дело вкуса.
Человек не читал документацию, поэтому чем более классическое решение ему будет предложено - тем лучше.
С учётом остальных тейков с твоей стороны - *Плохой совет иногда хуже чем просто промолчать*
Vladislav Losev, [20.12.2024 14:45]
Если ты не знаешь плюсов и минусов почему стоит\не стоит выдавать разделы вместо whole disk (хотя бы базовый /dev/disk/by-partuuid) - то не стоит высказывать это.
ИМХО - разницы никакой, но только если человек ПОНИМАЕТ почему он делает так, а не иначе
а в чем преимущества варианта когда вручную создается раздел на весь диск и этот раздел отдается ZFS ?
я у такого варианта вижу одни только недостатки и ни одного преимущества.
Вариант использования Whole Disk для ZFS имеет несколько преимуществ, о которых я уже говорил раньше.
Поэтому - по возможности именно этот вариант - Whole Disk и рекомендуется использовать в документации к ZFS.
Станислав
mdadm --create --verbose /dev/md0 --level=mirror --raid-devices=2 /dev/sdb1 missing
здесь с самого начала создается mdraid и соответственно - резервируется место под метаданные.
я говорил про тот случай когда есть только один диск, на нем - обычный раздел и на этом разделе уже создана файловая система и лежат данные.
в такой ситуации - конвертировать "на лету" single disk в mdraid невозможно.
О конвертации речи и не было, человек создал пул, скопировал данные, а потом хотел зазеркалить освободившимся диском, но запутался какой командой это нужно сделать. И хорошо, что спросил, а то получил бы райд0
Станислав
Хотя сейчас в zfs это совсем не страшно, можно легко отключить диск, вернув состояние одного диска
Δαρθ
не путайте, zfs send -L не сжимает, он не РАЗЖИМАЕТ если данные были сжаты и передаёт как есть, я про это
Ну если проблема только в том сколько надо передать по сети, то пожалуй zstd в пайпе жать будет лучше чем сугубо поблочное zfs
Станислав
Vladislav Losev, [20.12.2024 14:43]
Потому что это дело вкуса.
Человек не читал документацию, поэтому чем более классическое решение ему будет предложено - тем лучше.
С учётом остальных тейков с твоей стороны - *Плохой совет иногда хуже чем просто промолчать*
Vladislav Losev, [20.12.2024 14:45]
Если ты не знаешь плюсов и минусов почему стоит\не стоит выдавать разделы вместо whole disk (хотя бы базовый /dev/disk/by-partuuid) - то не стоит высказывать это.
ИМХО - разницы никакой, но только если человек ПОНИМАЕТ почему он делает так, а не иначе
а в чем преимущества варианта когда вручную создается раздел на весь диск и этот раздел отдается ZFS ?
я у такого варианта вижу одни только недостатки и ни одного преимущества.
Вариант использования Whole Disk для ZFS имеет несколько преимуществ, о которых я уже говорил раньше.
Поэтому - по возможности именно этот вариант - Whole Disk и рекомендуется использовать в документации к ZFS.
При этом в документации ZFS есть инструкция, как разбить диск на части, чтобы один раздел использовать для пула с ограниченными возможностями, чтобы с него grub мог загрузиться, а второй уже для остальных данных
Станислав
Ну если проблема только в том сколько надо передать по сети, то пожалуй zstd в пайпе жать будет лучше чем сугубо поблочное zfs
Разницы почти нет, проверял на разных данных. Правда я в пуле тоже использую zstd
Станислав
Зато большая экономия процессорного времени обоих машин
Δαρθ
Зато большая экономия процессорного времени обоих машин
Если у вас сетка 10гбит -- охотно верю. а если по инету через хз какие медленные каналы, то былоб чего экономить :)
Vladislav
mdadm --create --verbose /dev/md0 --level=mirror --raid-devices=2 /dev/sdb1 missing
здесь с самого начала создается mdraid и соответственно - резервируется место под метаданные.
я говорил про тот случай когда есть только один диск, на нем - обычный раздел и на этом разделе уже создана файловая система и лежат данные.
в такой ситуации - конвертировать "на лету" single disk в mdraid невозможно.
Но у нас же два диска ))))
Поэтому да, сперва создаётся failed raid-1, а потом он восстанавливается на два диска. Surprise
Vladislav
Vladislav Losev, [20.12.2024 14:43]
Потому что это дело вкуса.
Человек не читал документацию, поэтому чем более классическое решение ему будет предложено - тем лучше.
С учётом остальных тейков с твоей стороны - *Плохой совет иногда хуже чем просто промолчать*
Vladislav Losev, [20.12.2024 14:45]
Если ты не знаешь плюсов и минусов почему стоит\не стоит выдавать разделы вместо whole disk (хотя бы базовый /dev/disk/by-partuuid) - то не стоит высказывать это.
ИМХО - разницы никакой, но только если человек ПОНИМАЕТ почему он делает так, а не иначе
а в чем преимущества варианта когда вручную создается раздел на весь диск и этот раздел отдается ZFS ?
я у такого варианта вижу одни только недостатки и ни одного преимущества.
Вариант использования Whole Disk для ZFS имеет несколько преимуществ, о которых я уже говорил раньше.
Поэтому - по возможности именно этот вариант - Whole Disk и рекомендуется использовать в документации к ZFS.
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
Hennadii
Всех приветствую. Не могу ни как разобраться с zvol... С ZFS познакомился недавно, в свете организации семейного файлового хранилища чисто для дома. Есть ПК, который выделил под, скажем так, сервер. Хотел использовать на нем proxmox, но потом передумал, т.к. комп не особо шустрый. Решил ограничиться установкой Ubuntu 24.04 и несколькими виртуальными машинами в virtualbox и организацией mirror на zfs. Для этого у меня есть 2 жёстких по 1ТБ.
На одном из них (sdс) есть накопленная годами информация около 350Гб. Перенести мне её, на время создания зеркала , некуда.
И вот в чем у меня затык:
Начитавшись, что лучше создавать пулы из блочных устройств, удалил с пустого sdb все разделы (вместе с таблицей разделов) и создал из него zpool. Назовем его, как в различной документации, "tank". Ни какие датасеты и файловые системы я на нем не делал. Затем перенес данные семейного архива с обычного (ext4) sdc на новоиспечённый zfs-ный sdb. Далее мне нужно присоединить sdc к sdb и зазеркалить их, с сохранением данных. Для этого очистил sdc - удалив с него все разделы и таблицу разделов. А вот что дальше сделать мне не понятно. Где-то пишут, что нужно делать attach, где-то пишут, что надо сначала делать add и затем create, а где-то пишут о простом add с параметром mirror. В конец запутался. Может уже плюнуть на хорошести связанные с использованием блочных устройств и переделать все на vdev - создать таблицы разделов gpt, создать по разделу на каждом из дисков и объединять в зеркало уже их? Не понимаю.
Помогите пожалуйста.
При этом в документации ZFS есть инструкция, как разбить диск на части, чтобы один раздел использовать для пула с ограниченными возможностями, чтобы с него grub мог загрузиться, а второй уже для остальных данных
@a_d_m_i_n_S, в исходном вопросе разговор был про сервер с тремя дисками,
sda на котором установлена система, и два диска - sdb и sdc размером по 1 терабайту для файлового хранилища.
поэтому в такой ситуации именно выделение для ZFS дисков в режиме Whole Disk является наиболее целесообразным и наиболее удобным в работе вариантом.
про то, что надо использовать полные имена дисков из /dev/disk/by-id а не короткие имена /dev/sdb и /dev/sdc - про это в документации к ZFS написано, в ZFS FAQ:
hxxps : // openzfs . github . io / openzfs-docs/Project%20and%20Community/FAQ.html#selecting-dev-names-when-creating-a-pool-linux
Vladislav
При этом в документации ZFS есть инструкция, как разбить диск на части, чтобы один раздел использовать для пула с ограниченными возможностями, чтобы с него grub мог загрузиться, а второй уже для остальных данных
@a_d_m_i_n_S, в исходном вопросе разговор был про сервер с тремя дисками,
sda на котором установлена система, и два диска - sdb и sdc размером по 1 терабайту для файлового хранилища.
поэтому в такой ситуации именно выделение для ZFS дисков в режиме Whole Disk является наиболее целесообразным и наиболее удобным в работе вариантом.
про то, что надо использовать полные имена дисков из /dev/disk/by-id а не короткие имена /dev/sdb и /dev/sdc - про это в документации к ZFS написано, в ZFS FAQ:
hxxps : // openzfs . github . io / openzfs-docs/Project%20and%20Community/FAQ.html#selecting-dev-names-when-creating-a-pool-linux
На твой взгляд, если бы человек читал документацию - он бы задавал вопрос, который он задал? Вот ты говоришь, что by-id рекомендуется, не учитывая, что это это рекомендуется в определённых условиях
Δαρθ
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
Если это zfs mirror или любой raidz -- запросто. zfs потом всё отресилверит :)
Hennadii
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
мне удобнее благодаря использованию Whole Disk иметь возможность менять сбойный диск одной командой и удобнее иметь более высокую производительность дисковой подсистемы из-за автоматического переключения /sys/block/sdX/queue/scheduler из режима [mq-deadline] в режим [none].
отдельный раздел, размером 8 мегабайт, кстати, ZFS создает при использовании диска в режиме Whole Disk.
возможно что именно для этих целей - чтобы была возможность проводить тесты скорости чтения и записи.
Δαρθ
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
мне удобнее благодаря использованию Whole Disk иметь возможность менять сбойный диск одной командой и удобнее иметь более высокую производительность дисковой подсистемы из-за автоматического переключения /sys/block/sdX/queue/scheduler из режима [mq-deadline] в режим [none].
отдельный раздел, размером 8 мегабайт, кстати, ZFS создает при использовании диска в режиме Whole Disk.
возможно что именно для этих целей - чтобы была возможность проводить тесты скорости чтения и записи.
После чего сразу возникает вопрос, а не будет ли шедулер зфсы тормозить. Или его там нет вообще?
 Denver
Denver
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
мне удобнее благодаря использованию Whole Disk иметь возможность менять сбойный диск одной командой и удобнее иметь более высокую производительность дисковой подсистемы из-за автоматического переключения /sys/block/sdX/queue/scheduler из режима [mq-deadline] в режим [none].
отдельный раздел, размером 8 мегабайт, кстати, ZFS создает при использовании диска в режиме Whole Disk.
возможно что именно для этих целей - чтобы была возможность проводить тесты скорости чтения и записи.
Не понимаю, как whole диск связан с тем что ранее вы писали? Что gpt таблицу ZFS сам создает для диска? Для меня whole значит без gpt таблицы
Δαρθ
Я посмотрю как ты будешь тестировать диск на чтение\запись для проверки его деградации когда у тебя нет отдельного раздела для этого
мне удобнее благодаря использованию Whole Disk иметь возможность менять сбойный диск одной командой и удобнее иметь более высокую производительность дисковой подсистемы из-за автоматического переключения /sys/block/sdX/queue/scheduler из режима [mq-deadline] в режим [none].
отдельный раздел, размером 8 мегабайт, кстати, ZFS создает при использовании диска в режиме Whole Disk.
возможно что именно для этих целей - чтобы была возможность проводить тесты скорости чтения и записи.
zfs создаёт раздел чтобы (может быть если повезет) при замене диска на другой с такими же маркетинговыми терабайтами на нём (если очень повезет) можноо было бы сектор-в-сектор по размеру такой же основной раздел получить.
Δαρθ
а 8 мб для тестировия непригодны никак ваще, на порядки меньше размеров кешей в дисках
Vladislav
Hennadii
После чего сразу возникает вопрос, а не будет ли шедулер зфсы тормозить. Или его там нет вообще?
по идее - у ZFS должен быть свой планировщик ввода/вывода, судя по тому что написано в документации:
On Linux, the Linux IO elevator is largely redundant given that ZFS has its own IO elevator.
hxxps : // openzfs . github . io / openzfs-docs/Performance%20and%20Tuning/Workload%20Tuning.html#whole-disks-versus-partitions
Δαρθ
В целом же -- эти пляски с "отдавайте весь диск, у нас крутой шедулер" как мне кажется в 2024 имеют мало смысла уже
Δαρθ
просто легаси кушающее моск лишней сущностью
Vladislav
А конкретнее? Что за заморочки были у санок?
Вопрос на миллион, но я выше в чате тестировал, ZFS способен зацепить диск который меньше вплоть до 10 или 20МБ
Δαρθ
Вопрос на миллион, но я выше в чате тестировал, ZFS способен зацепить диск который меньше вплоть до 10 или 20МБ
В смысле новым куском к миррору или раидзу?
Denver
ZFS will also create a GPT partition table own partitions when given a whole disk under illumos on x86/amd64 and on Linux.
Vladislav
 Vladislav
Vladislav
Нашёл
Hennadii
В целом же -- эти пляски с "отдавайте весь диск, у нас крутой шедулер" как мне кажется в 2024 имеют мало смысла уже
почему не имеют смысла?
если есть два шедулера - тот который встроен в ZFS и тот который встроен в Linux - не будут ли они друг другу мешать?
когда ZFS построит по его мнению наиболее оптимальную последовательность операций, а Linux начнет переупорядочивать по своему?
имеют мало смысла для NVMe/SSD, а для обычных HDD - смысл наверное все-таки еще есть.
Hennadii
Не понимаю, как whole диск связан с тем что ранее вы писали? Что gpt таблицу ZFS сам создает для диска? Для меня whole значит без gpt таблицы
Если выделить Whole Disk для ZFS, то в таком случае ZFS самостоятельно создает на диске gpt и разделы.
Станислав
а можно свои 5 копеек спрошу?) у меня при выводе шедулера идет вот такой вывод для дисков:
root@pve:~# cat /sys/block/sdc/queue/scheduler
none [mq-deadline]
в итоге он какой шедулер пользует, none или дедлайн?)
диски zfs отданы именно дисками
Станислав
почему не имеют смысла?
если есть два шедулера - тот который встроен в ZFS и тот который встроен в Linux - не будут ли они друг другу мешать?
когда ZFS построит по его мнению наиболее оптимальную последовательность операций, а Linux начнет переупорядочивать по своему?
имеют мало смысла для NVMe/SSD, а для обычных HDD - смысл наверное все-таки еще есть.
Как раз для SSD это и может иметь место, чтобы максимально быстро на него писать, т.к. HDD будет узким горлышком, а не планировщик.
Станислав
а можно свои 5 копеек спрошу?) у меня при выводе шедулера идет вот такой вывод для дисков:
root@pve:~# cat /sys/block/sdc/queue/scheduler
none [mq-deadline]
в итоге он какой шедулер пользует, none или дедлайн?)
диски zfs отданы именно дисками
Дедлайн. Когда-то, где-то в доках видел, что нужно заменить на none вручную
Станислав
Дедлайн. Когда-то, где-то в доках видел, что нужно заменить на none вручную
вот блин🙈 16 дисков править)
Станислав
да ничего)
Denver
Если выделить Whole Disk для ZFS, то в таком случае ZFS самостоятельно создает на диске gpt и разделы.
если не ошибаюсь, то изначально в solaris диски не имели разделов и отдавались без разделов в zfs. Если я правильно понял, то в Linux без разделов не получится работать zfs?
Vladislav
Vladislav
@SmartBit7
Hennadii
а 8 мб для тестировия непригодны никак ваще, на порядки меньше размеров кешей в дисках
а сколько имеет смысл создавать раздел для тестирования?
если в диске встроенный cache, например, размером 512 мегабайт.
и зачем этот раздел для тестирования создавать, неужели файловая система ZFS сама не сможет обнаружить сбойный и глючный диск, который [очень] медленно работает?
часто ли встречаются такие ситуации, что операции чтения работают максимально быстро, а операции записи очень сильно тормозят?
насколько я понимаю, если тормозит запись, то будет тормозить тогда и чтение, а чтобы протестировать скорость чтения с диска - для этого наличие какого-то отдельного раздела не нужно, потому что операция чтения не является деструктивной.
я еще не встречал ситуаций, когда чтение работает быстро, а операция записи очень сильно тормозит.
обычно бывает наоборот - что именно чтение с какой-то обрасти диска тормозит очень сильно, а запись в другую область диска может работать и нормально при этом.
Станислав
Видел свежее инфу про mq-deadline, что он почти равен none