А почему? Это низкая нагрузка или наоборот высокая. Дело в том, что с этого хранилища постоянно будут работать пользователи, и переход на такой вариант сподвиг меня именно опыт работы на обычном нашем хранилище из 12ти обычных hdd, но там правда 6 vdev в mirror. Так вот пользователи ощущают периодически фризы программ временами. И наблюдение показало, что судя по всему дисковая подсистема не справляется с потоком запросов.
они точно не в сеть упираются ?
 Ivan
Ivan


 Vladislav
Vladislav
А почему? Это низкая нагрузка или наоборот высокая. Дело в том, что с этого хранилища постоянно будут работать пользователи, и переход на такой вариант сподвиг меня именно опыт работы на обычном нашем хранилище из 12ти обычных hdd, но там правда 6 vdev в mirror. Так вот пользователи ощущают периодически фризы программ временами. И наблюдение показало, что судя по всему дисковая подсистема не справляется с потоком запросов.
В заббиксе есть вполне однозначные метрики на эту тему
- IO latency
- Disk busy rate
- Network queue
Ещё в iostat zfs можно проверить
 Georg🎞️🎥
Georg🎞️🎥
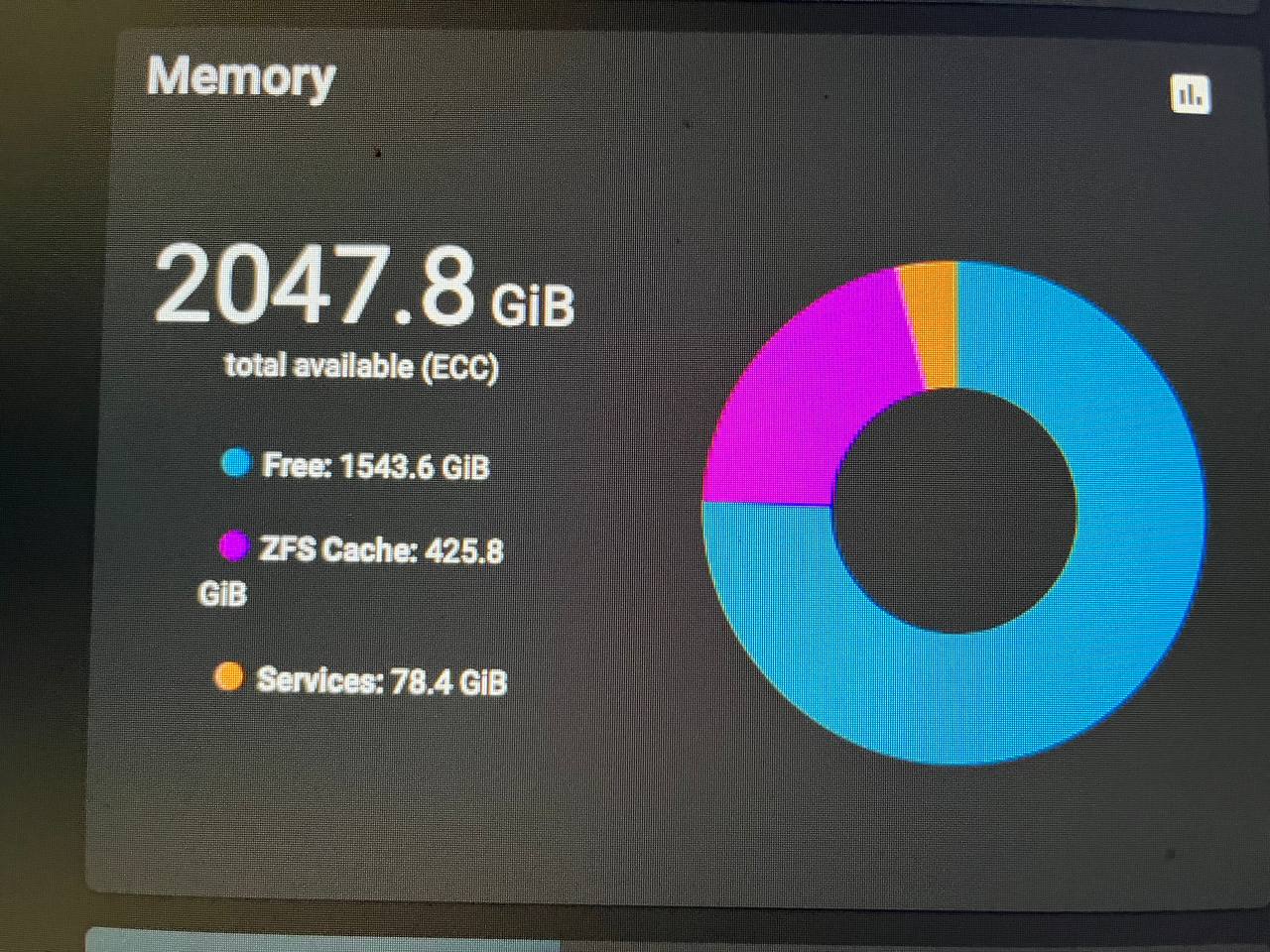
а чего так мало в arc ушло ?
Он тока создан… перебрасываю потихоньку … эта мандула умеет 6 тер дешевых ddr3 скинуть модельку ?
Ivan
Он тока создан… перебрасываю потихоньку … эта мандула умеет 6 тер дешевых ddr3 скинуть модельку ?
ну может кому пригодится.
 Vladislav
Vladislav
Он тока создан… перебрасываю потихоньку … эта мандула умеет 6 тер дешевых ddr3 скинуть модельку ?
Это сколько там слотов под память и какой размер модулей?
Georg🎞️🎥
Это сколько там слотов под память и какой размер модулей?
96
64 гиговые
Пока стоит 32 модуля
Vladislav
Там в шину точно не упирается?
Georg🎞️🎥
Сервер CSE-848X Supermicro X10QBI
Georg🎞️🎥
Нума и разделение на домены....
Это сложный для меня язык )) пока все хорошо по скорости записи на него )) предыдущий с 762 тоже не подводил , так что для моих 5-7 компов точно хватает
 Ivan
Ivan
Это сложный для меня язык )) пока все хорошо по скорости записи на него )) предыдущий с 762 тоже не подводил , так что для моих 5-7 компов точно хватает
Да, мы это обсуждали. Это как по мне хороший варик, но у тебя пользователей одновременных значительно меньше.
Georg🎞️🎥
Да, мы это обсуждали. Это как по мне хороший варик, но у тебя пользователей одновременных значительно меньше.
Это правда … но блин … 6тер неужели не хватит закэшировать (((
Ivan
Это правда … но блин … 6тер неужели не хватит закэшировать (((
Вопрос не только в скорости чтения, но и записи. Плюс, я когда начал считать, во сколько мне встанет система даже на 4 тб памяти, то понял, что это будет не дешевле варианта с nvme
Georg🎞️🎥
Вопрос не только в скорости чтения, но и записи. Плюс, я когда начал считать, во сколько мне встанет система даже на 4 тб памяти, то понял, что это будет не дешевле варианта с nvme
Да не , оч бюджетно относительно дисков ((
6 тер памяти и сервак выходя что то до 500к
Станислав
Это сложный для меня язык )) пока все хорошо по скорости записи на него )) предыдущий с 762 тоже не подводил , так что для моих 5-7 компов точно хватает
Между процессорами есть шина, по которой они общаются друг с другом и обращаются к оперативке, которая подсоединена к другому ЦП. Она не только имеет ниже скорость, чем прямой доступ к памяти, но и увеличенные задержки. В итоге производительность чтения вашей системы, скорее всего, будет уступать современной системе даже с парой vdev mirror на NVME. Про запись я вообще молчу, особенно, если там HDD.
 Artem
Georg🎞️🎥
Artem
Georg🎞️🎥
Между процессорами есть шина, по которой они общаются друг с другом и обращаются к оперативке, которая подсоединена к другому ЦП. Она не только имеет ниже скорость, чем прямой доступ к памяти, но и увеличенные задержки. В итоге производительность чтения вашей системы, скорее всего, будет уступать современной системе даже с парой vdev mirror на NVME. Про запись я вообще молчу, особенно, если там HDD.
Хорошо , что это не так ))) да, там hdd, великолепно пишет и читает 👌для моих нужд …
Наверное на 100 клиентов может уже и не хватит , но такой задачи не стояло 👋
А в случайном доступе самый ближайший ssd у нас это оптан, максимально на полтора терабайта и за космический прайс , которым большое объема пула не набрать 👋 пока лишь бодрен работает)) даже с учетом того, что вы написали
Artem
Авито в помощь )) и конторы , продающие сервера )
Да я уже глянул ) чот не ожидал, что 64Г нынче стоят ~4к, я правильно нагуглил?
Georg🎞️🎥
Да я уже глянул ) чот не ожидал, что 64Г нынче стоят ~4к, я правильно нагуглил?
Доброе , верно 👍 потому и выбрал - нужно было куча дешевой памяти ddr3 👌
Georg🎞️🎥
Да я уже глянул ) чот не ожидал, что 64Г нынче стоят ~4к, я правильно нагуглил?
По 3,6к даже есть :)))
 inqfen
inqfen
Да я уже глянул ) чот не ожидал, что 64Г нынче стоят ~4к, я правильно нагуглил?
Серверная нормальная, не б/у и не нонейм Китай около 80-100 баксов
Artem
Серверная нормальная, не б/у и не нонейм Китай около 80-100 баксов
Чем б/у оператива плоха? Ну и новая ddr3 - это как-то немножко смешно
inqfen
Чем б/у оператива плоха? Ну и новая ddr3 - это как-то немножко смешно
Вроде у тебя речи не шло про ддр3, а плохо отсутствием гарантии и непонятно кто и как юзал, может у китайцев грелась и помирать скоро будет
Georg🎞️🎥
Серверная нормальная, не б/у и не нонейм Китай около 80-100 баксов
 inqfen
inqfen
На пост где я отвечал про ддр3 ничего не было)
Artem
Вроде у тебя речи не шло про ддр3, а плохо отсутствием гарантии и непонятно кто и как юзал, может у китайцев грелась и помирать скоро будет
Если ты решил ворваться в ветку обсуждения не прочитав ее, то жаль.
Georg🎞️🎥
Вроде у тебя речи не шло про ддр3, а плохо отсутствием гарантии и непонятно кто и как юзал, может у китайцев грелась и помирать скоро будет
Может у бабушки был бы … :))
Вы себе лично можете брать новое по параллельному импорту и на amd эпик ) я вот к сожалению столько не зарабатываю и все на свои )) и у нас на таких системах все работает не первый год , тока диски менять :))
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
inqfen
Если ты решил ворваться в ветку обсуждения не прочитав ее, то жаль.
А, я как раз начал вечером читать с момента 4тб оперативки, а ддр3 было буквально несколькими постами выше
Сергей
Всех приветствую. Не могу ни как разобраться с zvol... С ZFS познакомился недавно, в свете организации семейного файлового хранилища чисто для дома. Есть ПК, который выделил под, скажем так, сервер. Хотел использовать на нем proxmox, но потом передумал, т.к. комп не особо шустрый. Решил ограничиться установкой Ubuntu 24.04 и несколькими виртуальными машинами в virtualbox и организацией mirror на zfs. Для этого у меня есть 2 жёстких по 1ТБ.
На одном из них (sdс) есть накопленная годами информация около 350Гб. Перенести мне её, на время создания зеркала , некуда.
И вот в чем у меня затык:
Начитавшись, что лучше создавать пулы из блочных устройств, удалил с пустого sdb все разделы (вместе с таблицей разделов) и создал из него zpool. Назовем его, как в различной документации, "tank". Ни какие датасеты и файловые системы я на нем не делал. Затем перенес данные семейного архива с обычного (ext4) sdc на новоиспечённый zfs-ный sdb. Далее мне нужно присоединить sdc к sdb и зазеркалить их, с сохранением данных. Для этого очистил sdc - удалив с него все разделы и таблицу разделов. А вот что дальше сделать мне не понятно. Где-то пишут, что нужно делать attach, где-то пишут, что надо сначала делать add и затем create, а где-то пишут о простом add с параметром mirror. В конец запутался. Может уже плюнуть на хорошести связанные с использованием блочных устройств и переделать все на vdev - создать таблицы разделов gpt, создать по разделу на каждом из дисков и объединять в зеркало уже их? Не понимаю.
Помогите пожалуйста.
Alexander
Для чего эти танцы с бубнами?)) если еще и с зфс никогда не сталкивались?🤔вопросов больше , чем ответов. Пересмотрите свое решение
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Как будто да, проще ext4 и просто чем-то копии с одного диска на другой для резервирования делать периодически.
Айтуар
Всех приветствую. Не могу ни как разобраться с zvol... С ZFS познакомился недавно, в свете организации семейного файлового хранилища чисто для дома. Есть ПК, который выделил под, скажем так, сервер. Хотел использовать на нем proxmox, но потом передумал, т.к. комп не особо шустрый. Решил ограничиться установкой Ubuntu 24.04 и несколькими виртуальными машинами в virtualbox и организацией mirror на zfs. Для этого у меня есть 2 жёстких по 1ТБ.
На одном из них (sdс) есть накопленная годами информация около 350Гб. Перенести мне её, на время создания зеркала , некуда.
И вот в чем у меня затык:
Начитавшись, что лучше создавать пулы из блочных устройств, удалил с пустого sdb все разделы (вместе с таблицей разделов) и создал из него zpool. Назовем его, как в различной документации, "tank". Ни какие датасеты и файловые системы я на нем не делал. Затем перенес данные семейного архива с обычного (ext4) sdc на новоиспечённый zfs-ный sdb. Далее мне нужно присоединить sdc к sdb и зазеркалить их, с сохранением данных. Для этого очистил sdc - удалив с него все разделы и таблицу разделов. А вот что дальше сделать мне не понятно. Где-то пишут, что нужно делать attach, где-то пишут, что надо сначала делать add и затем create, а где-то пишут о простом add с параметром mirror. В конец запутался. Может уже плюнуть на хорошести связанные с использованием блочных устройств и переделать все на vdev - создать таблицы разделов gpt, создать по разделу на каждом из дисков и объединять в зеркало уже их? Не понимаю.
Помогите пожалуйста.
Всего лишь 350Г, да это можно в яндекс облако запихнуть. Ну или купить диск б/у на авито. Или лучше SSD диск на 500г, потом из него сделать флешку. В хозяйстве пригодится.
Сергей
Всего лишь 350Г, да это можно в яндекс облако запихнуть. Ну или купить диск б/у на авито. Или лучше SSD диск на 500г, потом из него сделать флешку. В хозяйстве пригодится.
Это сейчас 350 - потому что не было места для хранения. Раньше был диск на 500мб и часто приходилось вычищать ненужные данные. Но удалось разжиться двумя террабайтниками и чтобы увеличить вероятность сохранности данных решил не использовать их как есть, а создать из них рейд в зеркало. Так узнал о существовании софтового рейда mirror в ZFS.
Сергей
Как будто да, проще ext4 и просто чем-то копии с одного диска на другой для резервирования делать периодически.
Копировать сейчас данные с одного на другой приходится потому что нет уже того диска на 500, иначе бы я сначала создал зеркало из двух террабайтников и затем перекинул данные с пятисотки. Сейчас приходится вот так делать, да.
Айтуар
Это сейчас 350 - потому что не было места для хранения. Раньше был диск на 500мб и часто приходилось вычищать ненужные данные. Но удалось разжиться двумя террабайтниками и чтобы увеличить вероятность сохранности данных решил не использовать их как есть, а создать из них рейд в зеркало. Так узнал о существовании софтового рейда mirror в ZFS.
Аппетит растёт быстро. Рекомендую сразу минимум три диска и raidz2. И полезной ёмкости больше и потом не будет геморроя с конвертированием из зеркала, так как конвертации нет.
Айтуар
Диски бу с авито для домашнего использования годятся
Сергей
Для чего эти танцы с бубнами?)) если еще и с зфс никогда не сталкивались?🤔вопросов больше , чем ответов. Пересмотрите свое решение
Ну а как бы вы сделали дома фаловое хранилище на софтовом рейде? Мне ZFS показалось лучше чем обычный рейд который также доступен в убунту.
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
Диски бу с авито для домашнего использования годятся
Можно конкретнее? Что за диски, какие гарантии?
Alexander
Ну а как бы вы сделали дома фаловое хранилище на софтовом рейде? Мне ZFS показалось лучше чем обычный рейд который также доступен в убунту.
Вы не поверите но софтовых рейды еще существуют, не только зфс)) я бы сделал 2 диска в зеркало и ехт4, почему у вас выбор пал на зфс?
Сергей
Аппетит растёт быстро. Рекомендую сразу минимум три диска и raidz2. И полезной ёмкости больше и потом не будет геморроя с конвертированием из зеркала, так как конвертации нет.
Все в бюджет упирается. У кого-то больше, у кого-то меньше. Пока мне будет достаточно зеркала из этих террабайтников - важнее сохранность данных, чем из количество. А с масштабированием буду разбираться потом, если будет в этом потребность.
Айтуар
Можно конкретнее? Что за диски, какие гарантии?
Гарантии - честнослово. А так многие продают диски от систем видео наблюдения. Тут либо купить новый за 10тыс либо 2 бу по 5 тыс и надеяться что один из них прожить сможет достаточно долго.
Айтуар
Все в бюджет упирается. У кого-то больше, у кого-то меньше. Пока мне будет достаточно зеркала из этих террабайтников - важнее сохранность данных, чем из количество. А с масштабированием буду разбираться потом, если будет в этом потребность.
В вашем случае тогда проще сделать mdraid и не парится. Он позволяет сделать зеркало без одного диска.
Сергей
Извините, а зачем вам вообще зфс ? Зачем виртуалки на отдельном пека - сервере?если он выделен только под хранение? Может просто убунту и р1 из 2 дисков?
Про виртуалки это так, лишнее наверное - к ним мой вопрос не относится. Мне нужно с добавлением диска и организацией зеркала разобраться.
Alexander
А без запасных дисков , вообще не рекомендую вам собирать р1, делайте лучше копии с одного на другой. Так будет надежнее
Сергей
А без запасных дисков , вообще не рекомендую вам собирать р1, делайте лучше копии с одного на другой. Так будет надежнее
В зеркале хорошо, в том числе, производительность при чтении - за счет распараллеливания запросов к разным устройствам, а так же балансировка нагрузки. Ну и lz4 хорошо, процессорного времени берет немного, а ужимает данные хорошо.
При обычных бекапах этого всего не будет...
Alexander
В зеркале хорошо, в том числе, производительность при чтении - за счет распараллеливания запросов к разным устройствам, а так же балансировка нагрузки. Ну и lz4 хорошо, процессорного времени берет немного, а ужимает данные хорошо.
При обычных бекапах этого всего не будет...
Так вы определитесь что вам нужно)) надежно хранить или вот это все))
Сергей
А без запасных дисков , вообще не рекомендую вам собирать р1, делайте лучше копии с одного на другой. Так будет надежнее
При выходе одно из двух дисков из строя я могу ведь пойти в магазин или кладовку, взять диск с размером не меньше прежнего, воткнуть его вместо сдохшего, заменить его применив, не помню сейчас какую именно, команду и данные с рабочего диска зазеркалятся на новый диск и все будет работать. Разве не так?
Alexander
При выходе одно из двух дисков из строя я могу ведь пойти в магазин или кладовку, взять диск с размером не меньше прежнего, воткнуть его вместо сдохшего, заменить его применив, не помню сейчас какую именно, команду и данные с рабочего диска зазеркалятся на новый диск и все будет работать. Разве не так?
Можно, но для начала поиграйтесь с зфс на файликах, изучите команды как это сделать, а то потом так же будете судорожно их искать, и молится , чтобы второй диск не отвалился.
Alexander
При выходе одно из двух дисков из строя я могу ведь пойти в магазин или кладовку, взять диск с размером не меньше прежнего, воткнуть его вместо сдохшего, заменить его применив, не помню сейчас какую именно, команду и данные с рабочего диска зазеркалятся на новый диск и все будет работать. Разве не так?
В моем варианте, что я вам предложил, в случае , если один диск сдохнет, вы сможете временно живой подключить к оси линуха, без зфс и скинуть данные, в вашем случае - нужно будет бежать срочно в магазин
 Denver
Denver
Denver
Denver
Преимущества zfs по сравнению с другими рейдами это чексумы, которые избавляют от bitrot
Сергей
В моем варианте, что я вам предложил, в случае , если один диск сдохнет, вы сможете временно живой подключить к оси линуха, без зфс и скинуть данные, в вашем случае - нужно будет бежать срочно в магазин
Ну там не база 1С, а семейный архив. Ни чего страшного если 2-3 дня он будет не доступен - не критично.
Alexander
Ну там не база 1С, а семейный архив. Ни чего страшного если 2-3 дня он будет не доступен - не критично.
Ну значит и не так важны)) играйтесь))
Denver
Если вам важна сохранность данных в течении времени, то я бы рекомендовал остаться на zfs. Mdraid считаю прошлым веком и не защищает от bitrot
Сергей
Ну значит и не так важны)) играйтесь))
Ну так за этим я и здесь)
Чтобы получить помощь в продвижении дальше, а вы мне "разворачивайся"))
Denver
И ещё лучше zfs делать на резделах gpt
Сергей
Если вам важна сохранность данных в течении времени, то я бы рекомендовал остаться на zfs. Mdraid считаю прошлым веком и не защищает от bitrot
Я такого же мнения. Но понимания что и как делать дальше нет.
Denver
У меня zfs хранилище на freebsd.
Denver
Думаю надо использовать man zfs для понимания команд
Alexander
Ну так за этим я и здесь)
Чтобы получить помощь в продвижении дальше, а вы мне "разворачивайся"))
Так я думал, данные очень важны)) и человек пытается прикрутить сразу зфс👌но я понял)
Сергей
И ещё лучше zfs делать на резделах gpt
Т.е. не использовать блочные устройства (sdb, sdc), а создавать на них таблицу разделов gpt, там создавать раздел размером на весь диск. И их (sdb1 и sdc1) организовывать в зеркало?
Denver
Нигде не видел рекомендации создавать zfs без gpt разделов Линукс и freebsd.
𝚜𝚎𝚗𝚜𝚎𝚖𝚊𝚍
В proxmox так и создаются, вроде как
Сергей
Да
Но в моем случае мне всё равно не обойти момент с последовательным включением в пул одного диска, а затем после перемещения данных на него, уже включением в пул второго диска и зеркалированием...
Как с этим быть? Какие команды мне нужно использовать для этого?
Сначала делаю add, а после этого create?
Denver
Проксмокс может и создаёт. Но если вам потребуется посмотреть что это за диск и с чем, то вы не сможете понять
Denver
Но в моем случае мне всё равно не обойти момент с последовательным включением в пул одного диска, а затем после перемещения данных на него, уже включением в пул второго диска и зеркалированием...
Как с этим быть? Какие команды мне нужно использовать для этого?
Сначала делаю add, а после этого create?
Почему последовательно сначала один а потом второй? Мне не совсем понятна логика. Можно же сразу зеркало из двух создать, а потом туда скопировать. Ааа, возможно хотите перенести данные с диска, а потом использовать как часть зфс.
Просто создаёте пул как один диск. Потом когда потребуется второй применяет команду attach
Сергей
Нигде не видел рекомендации создавать zfs без gpt разделов Линукс и freebsd.
В нескольких источниках читал об этом. Выгода в построении пула из блочных устройств в том что требуется меньше операций ввода-вывода для записи и чтения, т.к. отпадает необходимость взаимодействия с таблицей разделов и чего-то там ещё...
Айтуар
Почему последовательно сначала один а потом второй? Мне не совсем понятна логика. Можно же сразу зеркало из двух создать, а потом туда скопировать. Ааа, возможно хотите перенести данные с диска, а потом использовать как часть зфс.
Просто создаёте пул как один диск. Потом когда потребуется второй применяет команду attach
Так насколько я помню zfs не даёт создание degrade pool из одного диска. Или сейчас он уже это умеет?
Denver
В нескольких источниках читал об этом. Выгода в построении пула из блочных устройств в том что требуется меньше операций ввода-вывода для записи и чтения, т.к. отпадает необходимость взаимодействия с таблицей разделов и чего-то там ещё...
Нет. Это какая-то ересь. Никак на производительность не влияет с разделом диск или без. Просто возможно потребуется определить на другом компьютере с какой информацией этот диск. С разделом это будет видно, а без раздела покажет как пустой диск
Айтуар
И ещё лучше zfs делать на резделах gpt
А можете сказать какие от этого плюсы? Всегда считал создание разделов лишним.
Сергей
Почему последовательно сначала один а потом второй? Мне не совсем понятна логика. Можно же сразу зеркало из двух создать, а потом туда скопировать. Ааа, возможно хотите перенести данные с диска, а потом использовать как часть зфс.
Просто создаёте пул как один диск. Потом когда потребуется второй применяет команду attach
У меня 2 диска, объемом по 1ТБ. На одном из них есть информация, которую некуда перенести - нет, условно, третьего диска на который эти данные можно было бы временно перенести. Поэтому создаю пул из одного диска, на котором нет данных, затем копирую данные на него и после этого могу использовать второй диск для включения в пул и последующего зеркалирования.