 Vladislav
Vladislav


По ссылке есть пример
 riv
riv
Надеюсь достаточно наглядно получилось
собрать так тольо на zfs не прибегая к zfs over zfs не получится
Vladislav
Vladislav
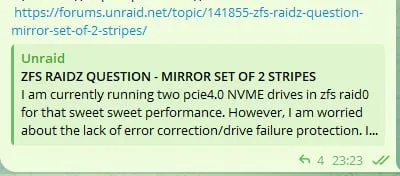
Там пониже есть постик как собирается это счастье
 riv
riv
вы просто тролите. со смартфона не удобно набирать
Vladislav
Ща, это надо проверить, по идее
https://forums.unraid.net/topic/141855-zfs-raidz-question-mirror-set-of-2-stripes/
Откройте ссылку в этом сообщении
Y
не ожинаковы, именно для не одинаковой вероятнгсти делают зеро на рулетке
riv
 riv
riv
Хм... нда.
riv
Не думал, что такое возможно.
Vladislav
не ожинаковы, именно для не одинаковой вероятнгсти делают зеро на рулетке
У Вас 4 диска, надёжность всего массив определяется вероятностью отказа 1 диска и это независимые события
riv
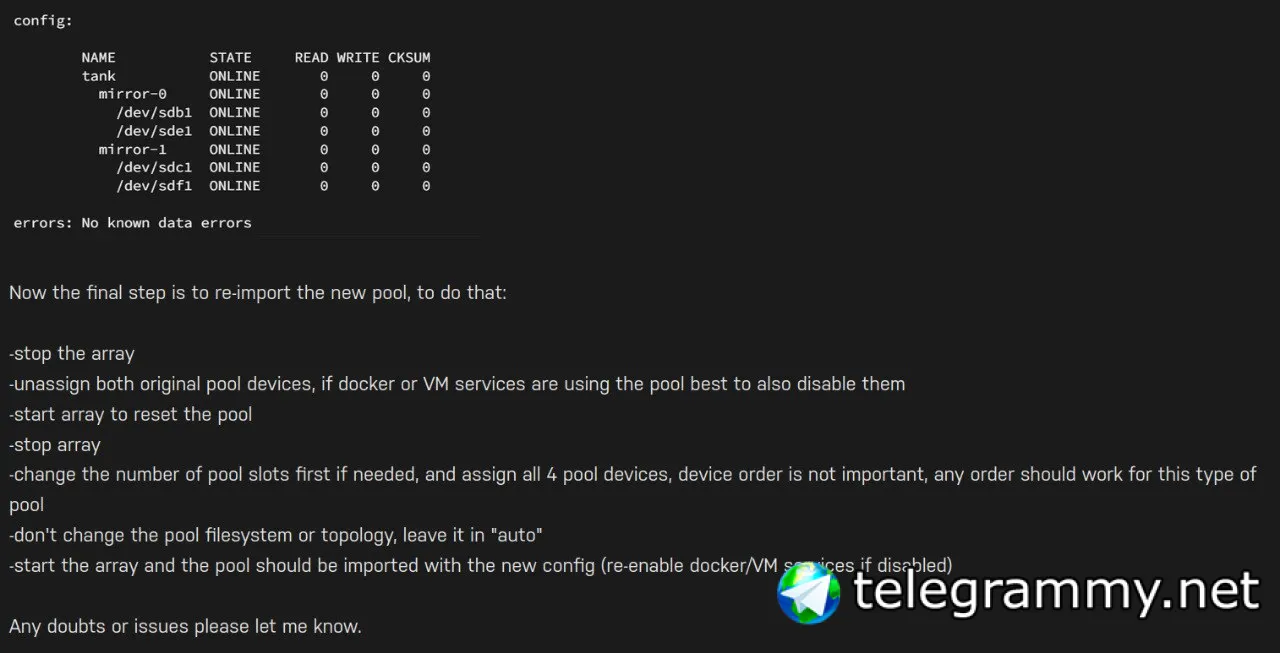
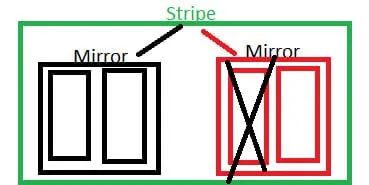
на картинке raid10
Vladislav
Vladislav
Stipe over mirrors
Y
У Вас 4 диска, надёжность всего массив определяется вероятностью отказа 1 диска и это независимые события
у нас 2 зеркала в страйпе после вылета первого диска, вылет следующего либо рушит масив если в том же зеркале либо нет.
Vladislav
не ожинаковы, именно для не одинаковой вероятнгсти делают зеро на рулетке
Да, логически в зеркале рядом которое из двух страйпов вероятность отказа одного из двух дисков выше, чем отказа одного в том же зеркале откуда идёт копирование
Y
Vladislav
из глубин универа
Y
даже логически не сходится
riv
Да, логически в зеркале рядом которое из двух страйпов вероятность отказа одного из двух дисков выше, чем отказа одного в том же зеркале откуда идёт копирование
да вопрос не в этом. А втом что если диск выдаст ошибку чтения сектора 4К, zfs забракует 8K данных. По этому, этот гипотетические сетап хуже
Vladislav
В частности мат ожидание на два независимых события vs 1
Vladislav
Vladislav
В частности мат ожидание на два независимых события vs 1
Чисто с точки зрения вероятности -
Raid10 = % отказа ещё одного диска в массиве, если один уже вылетел. Ака Raid5.
Я уже выше говорил, что есть люди, которые любят играть в рулетку, и мол добавлять к этому *не, ну диск может вылететь в соседнем зеркале, а не в том же*
Но это так работает только на больших 10-ах и я считаю это игрой в русскую рулетку
riv
Чисто с точки зрения вероятности -
Raid10 = % отказа ещё одного диска в массиве, если один уже вылетел. Ака Raid5.
Я уже выше говорил, что есть люди, которые любят играть в рулетку, и мол добавлять к этому *не, ну диск может вылететь в соседнем зеркале, а не в том же*
Но это так работает только на больших 10-ах и я считаю это игрой в русскую рулетку
в zfs есть add и attach, как ими сделать raid01, а не 10 в рамках одного пула?
riv
у вас не получится в одном пуле создать raid01
Станислав
у вас не получится в одном пуле создать raid01
Вас же уже несколько раз послали по ссылке выше. Похоже не вас тут троллят
riv
Вас же уже несколько раз послали по ссылке выше. Похоже не вас тут троллят
Да это не сработает. Там какая-то магия с переименование дисков. Я не понял. Я на практике знаю как ведет себя zfs и скажу вам что будет, если вы дадите команду сборки этого чуда 01
Станислав
Да, логически в зеркале рядом которое из двух страйпов вероятность отказа одного из двух дисков выше, чем отказа одного в том же зеркале откуда идёт копирование
Это если не учитывать тот факт, что для ресилвера идёт нагрузка на оставшийся диск. Но от него никуда не денешься
 Fedor
Fedor
Да это не сработает. Там какая-то магия с переименование дисков. Я не понял. Я на практике знаю как ведет себя zfs и скажу вам что будет, если вы дадите команду сборки этого чуда 01
судя по всему, тут уже теоретический разговор про 10 и 01, а не про зфс
riv
гипотетически, у вас должен быть промежуточный уровень не на zfs, И вот этот уровень может вести себя по разному. Если это raid0 в виде половинки zvol, скорее всего, при выходе из строя диска целиком, всё устройство станет недоступным и вы потеряете 50% надежности вместо 25%
Станислав
Fedor
с таким нетиповым намерением использования зфс лучше, наверное, в @sds_flood
Станислав
с таким нетиповым намерением использования зфс лучше, наверное, в @sds_flood
Я бы не сказал, отличная тема)
riv
с таким нетиповым намерением использования зфс лучше, наверное, в @sds_flood
да вопрос чисто теоритический. От таких вопросов не надо отмахиваться, они помогают всем понять лучше что происходит. Но в данном случае, по моему, люди не понимаю, что в zfs это не возможная конфигурация.
riv
в zfs неальзя "переименовть диск" при импорте, zfs опирется на метаданные в диске. Как вы их не прерименуйте, соберется так-же.
Fedor
да вопрос чисто теоритический. От таких вопросов не надо отмахиваться, они помогают всем понять лучше что происходит. Но в данном случае, по моему, люди не понимаю, что в zfs это не возможная конфигурация.
на ум сходу способов тоже пока не приходит, так как нужен дополнительный какой-то околонативный слой абстракции, чтобы вдев представить как отдельный блочник, из которого снова делать вдев.
Fedor
и мне кажется, что, даже если получится, зфс к такому может быть не готова, так что пока-пока надежность и стабильность.
Vladislav
в zfs есть add и attach, как ими сделать raid01, а не 10 в рамках одного пула?
Хм, надо будет глянуть тогда на тестовом стенде
Fedor
Хм, надо будет глянуть тогда на тестовом стенде
По ссылке выше классический миррор, у меня иначе и не получалось никогда.
Fedor
Стпайп из мирроров, вернее
riv
на ум сходу способов тоже пока не приходит, так как нужен дополнительный какой-то околонативный слой абстракции, чтобы вдев представить как отдельный блочник, из которого снова делать вдев.
Все вероятности надо расчитывать исходя из реальных ситуация выхода из строя. А в реальности, слой raid0 не известно как себя поведет, т.к. мы на знаем что это за слой. Например mdraid при выходи одного устройства, переведет весь raid0 в Fail, и у zfs исчезнет половинка mirror целиком, в тов ремя как без этих извращений, один vdev был бы DEGRAIDED, а второе в норме. Так что надёжность понизится.
Кроме того, как я писал выше, слой RAID0 отдаст устройство с 8K-секторами, что даст не большое пенальти к производительности на мелких операциях и не даст выигрыша на больших
Fedor
Все вероятности надо расчитывать исходя из реальных ситуация выхода из строя. А в реальности, слой raid0 не известно как себя поведет, т.к. мы на знаем что это за слой. Например mdraid при выходи одного устройства, переведет весь raid0 в Fail, и у zfs исчезнет половинка mirror целиком, в тов ремя как без этих извращений, один vdev был бы DEGRAIDED, а второе в норме. Так что надёжность понизится.
Кроме того, как я писал выше, слой RAID0 отдаст устройство с 8K-секторами, что даст не большое пенальти к производительности на мелких операциях и не даст выигрыша на больших
при отказе компонента в райд0 потеряются только копии части набора данных, и надежность только этого набора данных будет снижена.
надежность хранилища в 01 можно смоделировать как процент надежности всех дисков, перемноженной друг на друга. один диск вылетел - весь набор данных потерял резервирование.
Fedor
формулу набросал навскидку, но примерно так оно и выглядит. upd чуть обновил
riv
Я всё ещё не понимаю почему
По тому что это не jbod, два yстройства с секторами 4К обхеденяются в устройство с секторами 8К
Fedor
Fedor
извините за формулировку, конечно))
Vladislav
По тому что это не jbod, два yстройства с секторами 4К обхеденяются в устройство с секторами 8К
Если бы про прослойку mdadm, то он выдаст блоки 512k
riv
извините за формулировку, конечно))
Хм... надо попробовать собрать. Вдруг на самом деле 4К будет
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
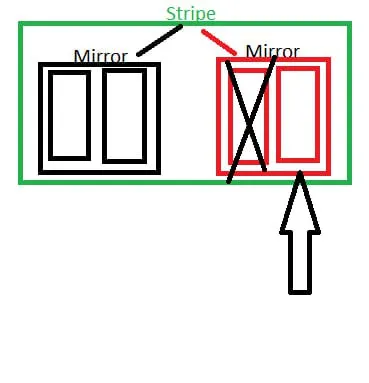
Мы теряем весь пул
Vladislav
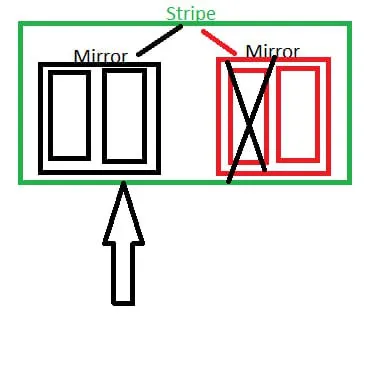 Vladislav
Vladislav
И соответственно крайне левый аналогично
Vladislav
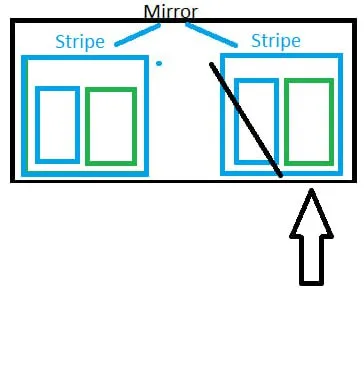 Vladislav
Vladislav
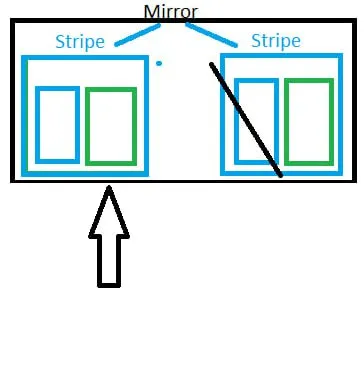 Vladislav
Vladislav
С точки зрения русской рулетки - 01 опаснее
Fedor
Тут, кажется, лучше на трех показывать, нагляднее будет)
Vladislav
С точки зрения русской рулетки - 01 опаснее
С точки зрения здравого смысла - у тебя надёжность в ОДИН диск, всё остальное русская рулетка, по крайней мере в реальном мире (при ограничении в 4 диска)
Fedor
И аффект будет на все данные, а не на часть
Станислав
С точки зрения здравого смысла - у тебя надёжность в ОДИН диск, всё остальное русская рулетка, по крайней мере в реальном мире (при ограничении в 4 диска)
Я бы сказал, что надежность в 0.1 диск, так как вероятность выхода из строя увеличивается
Станислав
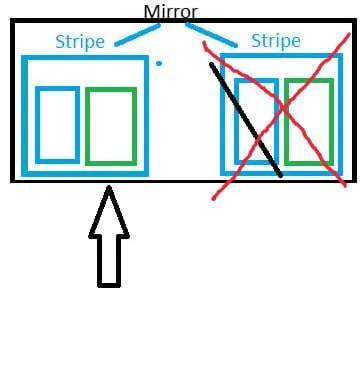 Vladislav
Станислав
Vladislav
Станислав
Фактически, для сохранения данных на диске в страйпе, ФС должна запомнить в каком состоянии она была на момент потери диска в страйпе, потом отсинхать с зеркального диска нужные данные на новое устройство, а потом догнать все данные для пересобранного страйпа до текущего состояния ФС
Станислав
В здравом уме никто такой функционал делать не будет)
Vladislav
В здравом уме никто такой функционал делать не будет)
Да, потому что 01 рейд очень странная затея сама по себе
 Александр
Александр
Всем привет! версия зфс 2.1.12, ядро 6,1,44. Скорее всего этот вопрос больше на гитхаб, но может быть тут быстрее ответят если я что то упустил, создаю пул и добавляю к нему диск l2cache, делаю экспорт этого пула, создаю второй пул и пытаюсь добавить тот же диск в l2cache, он успешно добавляется и если после этого импортировать первый пул, то он импортируется и у l2cache диска будет статус FAULTED.
я пробовал использовать апи зфс и вызвал функцию zpool_in_use() на этот диск в тот момент когда он привязан к первому пулу и пул экспортирован, и он пишет что диск не занят, хотя в это же время если вызвать zpool_read_label(), то он вернёт 4 метки, то есть видит их. судя по коду, зфс не может достать из l2cache свойство vdev_tree и считает что диск свободен. такая же история и с запасными. это баг или так и задумано? разве не должно быть безусловного возврата занятости диска если zpool_read_label() вернул какие то метки зфс?