а сколько надо?
терабайты 10 тыщ лет тестить будет
 Vladislav
Vladislav

 Vladislav
Vladislav
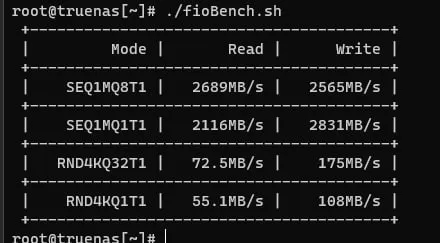
Что. Вы. Тестили.
Vladislav
Arc кэш?
Буфер HDD?
Vladislav
ХОТЯ бы, 30% от объёма пула в тестах прогоните
Vladislav
А лучше 80%
 жюн
жюн
многа...
жюн
а чем тестить?
Alex
на поточке raidz может быть быстрее и это ожидаемо, на рандоме - у меня сразу вопрос какой у вас recordsize
если бы тесты были корректные, то я бы скорей ожидал, что скрины перепутали местами. Сиквенс скорость растет с кол-вом устройств в одном vdev. В схеме 2x z2 там получается 4 диска, в схеме зеркала - 6. Теоретически, зеркало должно быть быстрее на seq нагрузке
Vladislav
жюн
А чем нагружать пул будете?
бэкапы там пылиться будут по большей части, да мб по iscsi пара дисков уедет в вм'ки
Alex
я про теоретически
жюн
30-80% этим скриптом недельку гонять буду
Vladislav
бэкапы там пылиться будут по большей части, да мб по iscsi пара дисков уедет в вм'ки
Я правильно понял, бэкап у Вас будет объёмом в 1ГБ?
жюн
ну чутка больше, там как получится, пара тб может быть
жюн
:)
Alex
бэкапы там пылиться будут по большей части, да мб по iscsi пара дисков уедет в вм'ки
А как вы планируете "уйти на ВМки" пару дисков ? o-0
жюн
А как вы планируете "уйти на ВМки" пару дисков ? o-0
я не имел ввиду отдельно взятый физический хард ж
жюн
zvol по iscsi отдам
Alex
я не имел ввиду отдельно взятый физический хард ж
вы пишете - "диски". Я откуда знаю, что вы имели в виду ? :) В моей вселенной диск - это физический диск
жюн
и то верно
Alex
a бэкап и вм - кардинально разные нагрузки..
Alex
под бэкап я бы делал z2/z3 одним куском и всё. Там обычно один seq, а ему чем больше дисков в вдев - тем быстрее
 George
George
 жюн
жюн
root@truenas[/]# cat /sys/module/zfs/version
2.2.2-1
Alex
recordsize можно выставлять свой каждому датасету. БОльший rs даст лучшую компрессию (при прочих равных), что хорошо для бэкап датасета. Опять же - обычно
Alex
я на холодных массивах выставляю rs побольше. Даже 5% прибавки компрессии на 300ТБ даёт вполне осязаемый профит $ :)
жюн
холодные - это как?
 Artem
Artem
Прохлаждаются...
жюн
а что про l2arc скажете? когда надо, а когда не надо
Станислав
а что про l2arc скажете? когда надо, а когда не надо
Когда опертивы уже по максимуму в матери, но её сильно не хватает для кеширования данных в пуле
жюн
а как понять, что не хватает оперативы?
Василий
Оперативы всегда не хватает. А если вам под холодные бэкапы то l2arc вам вероятно не особо нужен. И мета с слогом, тоже вряд-ли нужна. Ставьте сжатие позабористее, блок пошире и синхронную запись отрубайте, глядишь что-то выиграйте. Хотите многа многа скорости не смотря ни на что, вопреки всему - это вам в соседнюю ветку про bcachefs или btrfs... если бэкапы екнуться ведь ничего страшного ...
ᅠ
подскажите плз, кто как хранит netflow?
есть идея использовать софтовый raidz1 на zfs
как там со скоростью чтения/записи, скоростью восстановления данных? действительно ли все очень медленно копируется на другие диски? (находил инфу что 4тб данных будут копироватся дня 3)
стоит ли оно того или лучше и быстрее будет на аппаратном RAID все поднимать, без zfs?
для анализа предварительно будет использоватся ELK Stack
у кого есть опыт, поделитесь пожалуйста
Vladislav
подскажите плз, кто как хранит netflow?
есть идея использовать софтовый raidz1 на zfs
как там со скоростью чтения/записи, скоростью восстановления данных? действительно ли все очень медленно копируется на другие диски? (находил инфу что 4тб данных будут копироватся дня 3)
стоит ли оно того или лучше и быстрее будет на аппаратном RAID все поднимать, без zfs?
для анализа предварительно будет использоватся ELK Stack
у кого есть опыт, поделитесь пожалуйста
А можно поток сознания переписать в человеческую задачу? Какой объем, куда копировать, какой трафик надо прокачать в единицу времени? Какие диски доступны? Какие сетевухи?
ᅠ
А можно поток сознания переписать в человеческую задачу? Какой объем, куда копировать, какой трафик надо прокачать в единицу времени? Какие диски доступны? Какие сетевухи?
можно. нужно )
есть задача сбора и хранения метатрафика
под это дело выделяем сервачек, с hdd общим обьемом примерно под 100тб
к примеру такой DELL R720XD (12x3.5) LFF
над количеством и размером каждого из дисков ещё думаем
стоит вопрос по софтовой части, какую файловую систему использовать, и какой в итоге лучше использовать raid массив для повышения отказоустойчивости.
смотрим в сторону zfs, но в тоже время, некоторые пишут что при отвале диска, копирование данный на другой будет очень медленное по времени (если речь о терабайтах данных). хотелось бы понимать так ли это действительно.
и в тоже время, хотелось бы понять, будет ли это влиять одномоментно на общую производительность пула в целом
с zfs знаком базово, вникаю, сильно не критикуйте
Vladislav
можно. нужно )
есть задача сбора и хранения метатрафика
под это дело выделяем сервачек, с hdd общим обьемом примерно под 100тб
к примеру такой DELL R720XD (12x3.5) LFF
над количеством и размером каждого из дисков ещё думаем
стоит вопрос по софтовой части, какую файловую систему использовать, и какой в итоге лучше использовать raid массив для повышения отказоустойчивости.
смотрим в сторону zfs, но в тоже время, некоторые пишут что при отвале диска, копирование данный на другой будет очень медленное по времени (если речь о терабайтах данных). хотелось бы понимать так ли это действительно.
и в тоже время, хотелось бы понять, будет ли это влиять одномоментно на общую производительность пула в целом
с zfs знаком базово, вникаю, сильно не критикуйте
На таких объемах во всех системах будет долгий ребилд, классический рейд может быть побыстрее за счёт кэша, но зависит от того нужно ли Вам сжатие к примеру
ᅠ
можно. нужно )
есть задача сбора и хранения метатрафика
под это дело выделяем сервачек, с hdd общим обьемом примерно под 100тб
к примеру такой DELL R720XD (12x3.5) LFF
над количеством и размером каждого из дисков ещё думаем
стоит вопрос по софтовой части, какую файловую систему использовать, и какой в итоге лучше использовать raid массив для повышения отказоустойчивости.
смотрим в сторону zfs, но в тоже время, некоторые пишут что при отвале диска, копирование данный на другой будет очень медленное по времени (если речь о терабайтах данных). хотелось бы понимать так ли это действительно.
и в тоже время, хотелось бы понять, будет ли это влиять одномоментно на общую производительность пула в целом
с zfs знаком базово, вникаю, сильно не критикуйте
трафика едет примерно 60гиг. даже чуть больше
по подсчетам, за год будет писать примерно 25 тб. но нужно хранить за несколько.
поэтому выделяем около 100тб пд это дело
ᅠ
На таких объемах во всех системах будет долгий ребилд, классический рейд может быть побыстрее за счёт кэша, но зависит от того нужно ли Вам сжатие к примеру
понял, спасибо.
почитаю дальше об этом
Vladislav
понял, спасибо.
почитаю дальше об этом
Только R6/R60 (z2) кстати, если не хотите потом развлечения
жюн
мужчины, а такой вопрос вот есть:
на матери 2 слота под mini sas - 8 дисков, и в контроллере 2 mini sas -> все 12 дисков в одно место не втыкаются, окажет ли влияние какое факт того, что диски в разные железки подключены?
Y
 f1gar0
f1gar0
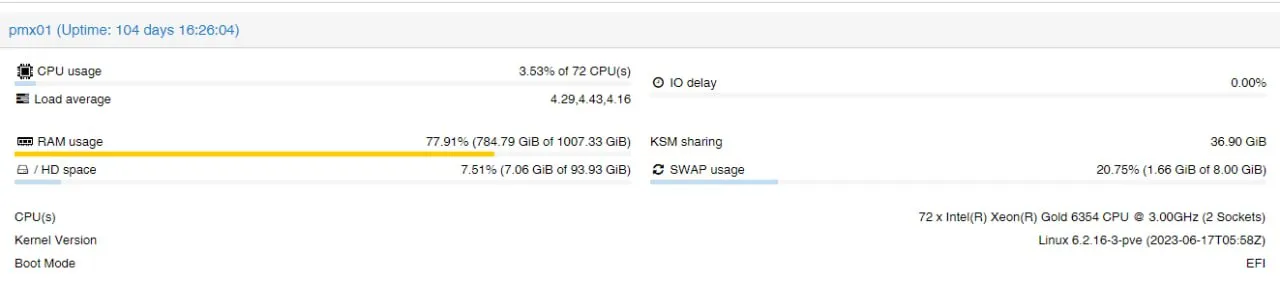
#Вопрос доброе утро есть 3 ноды с zfs по 1tb RAM на каждой и ZFS из U2 Nmve SSD gj 24 tb какой адекватный параметр arc max поставить 50gb&
 Fedor
Fedor
Зависит от обьема горячих данных и требований к производительности. Можно начать с настроек по умолчанию - 50 процентов рам, насколько помню, а там покрутить по необходимости
f1gar0
f1gar0
 f1gar0
f1gar0
виртуалки кушают 300 все остально уже zfs
Fedor
Смотреть по объёму горячих данных и требований к производительности
f1gar0
Смотреть по объёму горячих данных и требований к производительности
задам глуппый вопрос как посмотреть объем горячих данных?
 Mikhail
Ivan
Mikhail
Ivan
лучше zfs_arc_sys_free настроить
 Llun Ved
Llun Ved
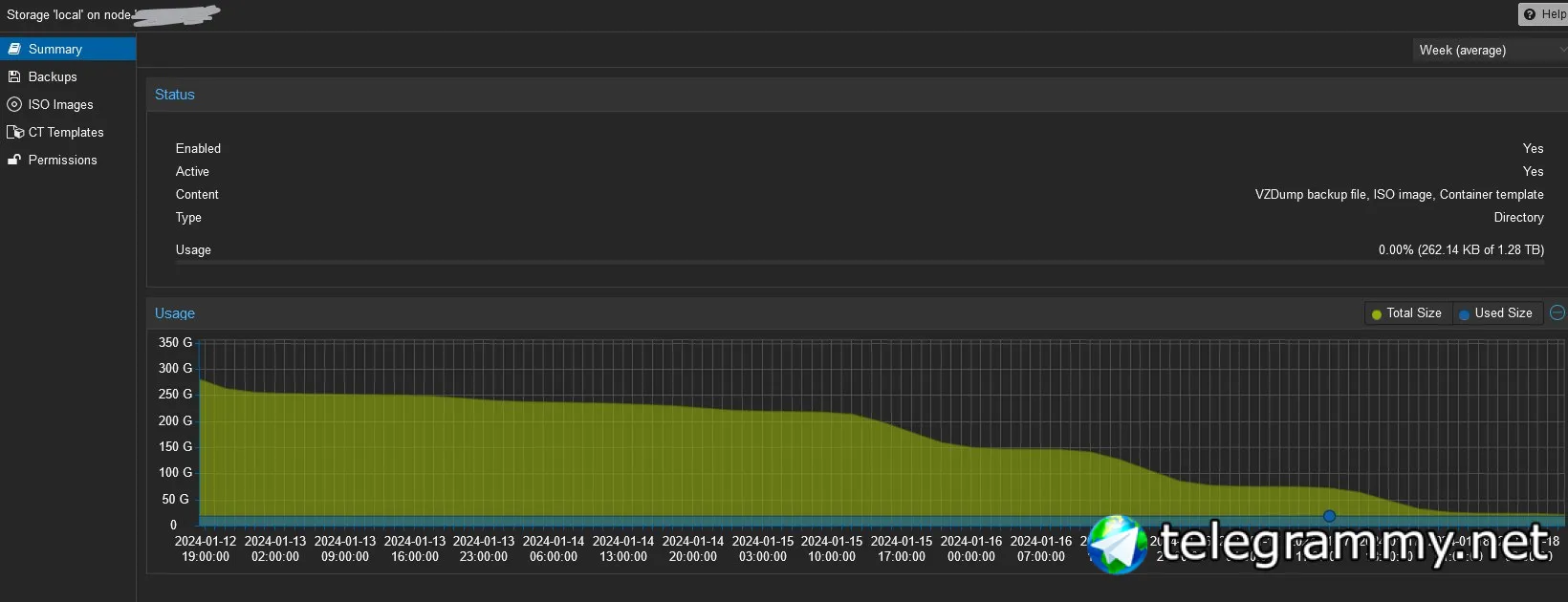 Llun Ved
Llun Ved
Может, кто-то с подобным сталкивался?
Llun Ved
Проблему наблюдал как на pve 8.1.3, так и на 7.3
 Алексей
Алексей
рекомендую присмотреться к параметру zpool replace -s
Алексей
Ivan
похоже в пуле есть кто-то кто кладёт туда данные помимо проксмокса, а он не в курсе
ставлю на qcow виртуалки
Y
я так понимаю там всё забэкаплено или не очень нужно ? на время реплейса останется голый страйп по сути (если диск сбойный будет вынут)
Y
рекомендую присмотреться к параметру zpool replace -s
Sequential reconstruction is not supported for raidz configurations.
 CARA
Y
CARA
Y
при вылете одного диска остается 23 в страйпе !!! 🤪
Алексей
У меня получилось
Y
Отсутствием важных данных может?
выше он сказал что нужно что бы всё сохранилось, так что видимо тот кто делал просто не знал что он делает
CARA
Отсутствием важных данных может?
Неа)нужно было много места…просто человеку чем больше тем лучше
Y
есть много эникей-одминов, которые знают как, но не знают почему, а потому работают тупо по инструкции не включая голову
Vladislav
Неа)нужно было много места…просто человеку чем больше тем лучше
R50 на 4 страйпа тогда бы...
 Aleks
Aleks
а если данные пропадут, то свободного места станет еще больше 😁