Непонятны условия выполнения тестов. Сколько памяти отдано под arc? запись синхронная? Meta вынесена как? запись/чтение потоком/случайным блоком? Ну и как бы странно тестировать сабж на одном диске. Понятно, что ext4 и другие ос в таких условиях будет быстрее. Если что - я не адепт зфс.
Кстати да, описание стенда отсутствует как понятие
 Vladislav
Vladislav


 Алексей
Алексей
Непонятны условия выполнения тестов. Сколько памяти отдано под arc? запись синхронная? Meta вынесена как? запись/чтение потоком/случайным блоком? Ну и как бы странно тестировать сабж на одном диске. Понятно, что ext4 и другие ос в таких условиях будет быстрее. Если что - я не адепт зфс.
условия и вообще задачу тестирования я описывал в первой заметке
 Василий
Алексей
Василий
Алексей
3. Ну судя по описанию, я могу ошибаться, вы нарезали на ssd и hdd разделы, слипили зеркало ssd+hdd и залили туда special, а оставшееся место на hdd использовали под основной раздел.
хдд нарезал, ссд отдал полностью, хдд только для зфс
Василий
хдд нарезал, ссд отдал полностью, хдд только для зфс
Я правильно понимаю, что мета на зеркале из ssd и hdd? Это ключевой вопрос.
Алексей
Я правильно понимаю, что мета на зеркале из ssd и hdd? Это ключевой вопрос.
если мы говорим про бртфс - да,
если про зфс - то там порознь
Василий
ну к слову, да. поправлю.
спасибо
И еще, просьба, укажите размерность. Что это мегабайты в секунду, оипсы, киловаты в час? Так будет более информативно.
Алексей
И еще, просьба, укажите размерность. Что это мегабайты в секунду, оипсы, киловаты в час? Так будет более информативно.
мне кажется там всё подписано?
Vladislav
И еще, просьба, укажите размерность. Что это мегабайты в секунду, оипсы, киловаты в час? Так будет более информативно.
Эрм, там подписано же, в тексте, но написано
Алексей
а я графики делаю и для английского языка, и делать две картинки меня заломало)
Василий
А да, увидел. А время листинга в секундах, я полагаю.
 George
George
io_direct кстати на zfs стоит явно отключать сейчас, там не оч производительная прослойка-заглушка
 Nick
Nick
io_direct кстати на zfs стоит явно отключать сейчас, там не оч производительная прослойка-заглушка
Хуже, чем без него?
а как опция для отключения называется?
George
Хуже, чем без него?
а как опция для отключения называется?
ну приложение чтобы не юзало direct
Nick
а, т.е. со стороны zfs или опций монтирования не поменять?
И какой вариант тогда рекомендуется для мускля?
George
Василий
похоже на то
Интересные условия для теста zfs.А можно вас попросить протестировать то же самое, только вместо specal использовать ssd под slog и время сброса увеличить в несколько раз.
George
а, т.е. со стороны zfs или опций монтирования не поменять?
И какой вариант тогда рекомендуется для мускля?
тут базово описывалось когда-то, правда за актуальность не скажу точно https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Workload%20Tuning.html#innodb
Vladislav
Василий
Ммм, libaio вполне себе дефолтный вариант теста, не уверен в чем проблема?
да нет проблем, просто пытаюсь для себя понять физический смысл тестов и причины полученных показателей.
Nick
тут базово описывалось когда-то, правда за актуальность не скажу точно https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Workload%20Tuning.html#innodb
Стабильно получаю ухудшение в любом сценарии при включении primarycache=metadata , но текст видимо обновился, про aio раньше не видел, спасибо
George
Стабильно получаю ухудшение в любом сценарии при включении primarycache=metadata , но текст видимо обновился, про aio раньше не видел, спасибо
primarycache=metadata соглашусь что если есть память есть смысл использовать all всё же, а так тут речь про "отдать вообще всю память что есть базе"
George
но не на 100% универсальный совет
Василий
Можно
Я правильно понимаю, что вы проводите тесты для выбора фс под условную БД на 128 гб с преобладающей записью, или под условную VM?
Алексей
Я правильно понимаю, что вы проводите тесты для выбора фс под условную БД на 128 гб с преобладающей записью, или под условную VM?
Нет. Я выбираю фс под 10-15 терабайтное количество мелких файлов. Чтение всегда рандомное, запись как получится, в основном асинхронная. Использование виртуальных машин не планируется. Соотношение чтение-запись примерно такое, да. Иногда происходит прогулка по всем файлам дабы убедиться что они есть. Ну и иногда приходит рипер который удаляет запойно по несколько часов так что всё может просто лечь
Василий
Видеоархив какой-то с камер ?
Василий
*Мелких файлов*
Могут как раз писать мелкими файликами до мегабайта вклбчительно, был свидетелем подобного решения. Какие ваши предположения?
Vladislav
Могут как раз писать мелкими файликами до мегабайта вклбчительно, был свидетелем подобного решения. Какие ваши предположения?
Хотя да какой-нибудь zoneminder
Alex
io_direct кстати на zfs стоит явно отключать сейчас, там не оч производительная прослойка-заглушка
А как? Если я не ошибаюсь, в линухе direct_io для zfs пока невключаем(точнее)
George
А как? Если я не ошибаюсь, в линухе direct_io для zfs пока невключаем(точнее)
там мулька-прослойка есть, для поддержки интерфейса
Alex
https://github.com/openzfs/zfs/pull/10018
Alex
Нет. Я выбираю фс под 10-15 терабайтное количество мелких файлов. Чтение всегда рандомное, запись как получится, в основном асинхронная. Использование виртуальных машин не планируется. Соотношение чтение-запись примерно такое, да. Иногда происходит прогулка по всем файлам дабы убедиться что они есть. Ну и иногда приходит рипер который удаляет запойно по несколько часов так что всё может просто лечь
а можно ссылку на 1 часть? чот странное. У мну есть один похожий ворклоад, правда, там много дисков и bsd...
Алексей
а можно ссылку на 1 часть? чот странное. У мну есть один похожий ворклоад, правда, там много дисков и bsd...
внутри заметки в самом начале ссылка на часть 1
Василий
 Алексей
Алексей
ааа.... ну тогда zfs тут вряд ли вам нужен, думаю он сильно про другое.
сильно да, но до определенного времени меня устраивало как он работает с метой.
Однако всё равно он не устраивает меня в части скорости записи (я банально получаю больше данных чем оно успевает записать) даже с sync=disabled
а так же меня не устраивает медленный zfs send (казалось бы чего проще лей себе линейно, но нифига, полное рандомное чтение каждый раз)
Станислав
сильно да, но до определенного времени меня устраивало как он работает с метой.
Однако всё равно он не устраивает меня в части скорости записи (я банально получаю больше данных чем оно успевает записать) даже с sync=disabled
а так же меня не устраивает медленный zfs send (казалось бы чего проще лей себе линейно, но нифига, полное рандомное чтение каждый раз)
А как с другими тестируемыми ФС в данном случае обстоят дела? У них есть средства передачи инкрементных данных или другими средства, опережающие zfs send?
Алексей
А как с другими тестируемыми ФС в данном случае обстоят дела? У них есть средства передачи инкрементных данных или другими средства, опережающие zfs send?
Скорее всего я просто буду делать dd раздела
Vladislav
А как с другими тестируемыми ФС в данном случае обстоят дела? У них есть средства передачи инкрементных данных или другими средства, опережающие zfs send?
Мне нравится, что когда заканчиваются аргументы люди переходят к zfs send
Станислав
Мне нравится, что когда заканчиваются аргументы люди переходят к zfs send
Мне тоже нравится, когда сказать нечего, люди начинают цепляться к одному знакомому слову, лишь бы 5 копеек вставить
or
Zfs проигрывает во всем ?
жюн
 жюн
жюн
 жюн
жюн
в случае 10 ещё и компрессия отключена
жюн
человек ливнул с чата от таких вопросов (700>699)
George
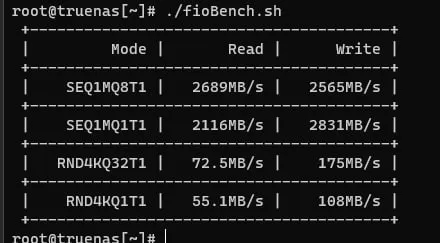
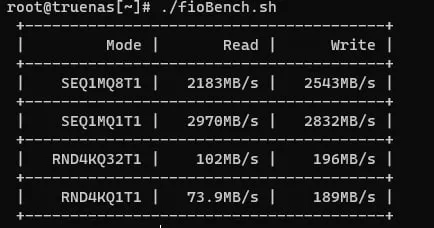
на поточке raidz может быть быстрее и это ожидаемо, на рандоме - у меня сразу вопрос какой у вас recordsize
жюн
если вы про объём тестовых данных - 1гб, 5 проходов
George
жюн
https://pastebin.com/PJcVmer5
жюн
скриптик такой
жюн
recordsize 128k
Vladislav
1гб...
Vladislav
Алексей