 Василий
Василий


Вот, кстати это было бы круто. На хранилише до 100tb можно было бы мету записать в зеркало из optane( с учётом того что их больше не делают и цена у них как крыло от самолета), а мелкие блоки на зеркало из nand с plp. Мета вероятно за придел в 100gb не вылезет, а мелкоблочке (до 64кб) лучше отдать пару террабайт. Но это все теоретические прикидки, может в какомнибудь конкретном случае весь объём быть засран мелкими блоками.
武士
А его в raidz3 какой нить можно собрать , интересно ?
нельзя. тем более, что это не лучшая идея в принципе.
Georg🎞️🎥
Вот, кстати это было бы круто. На хранилише до 100tb можно было бы мету записать в зеркало из optane( с учётом того что их больше не делают и цена у них как крыло от самолета), а мелкие блоки на зеркало из nand с plp. Мета вероятно за придел в 100gb не вылезет, а мелкоблочке (до 64кб) лучше отдать пару террабайт. Но это все теоретические прикидки, может в какомнибудь конкретном случае весь объём быть засран мелкими блоками.
100 тер - это 3 тера меты и оптаны в зеркале .. удачи )))
Василий
Всем доброго времени суток. Ищу помощи специалистов по тюнингу ФС и умению сделать "все хорошо". Из группы Storage Discussions подсказали написать сюда.
Дано сервер - Ubuntu 20.04 LTS, ppc64le 80 x 3.49GHz, 512GB RAM
Диски
2 x 16TB 3.5" HDD SATA WD
1 x 1.6TB AIC SSD NVMe PCIe x8 Samsung
2 x 128GB M.2 SSD NVMe PCI4 x4 Samsung
+ (маленький диск под OS но он не в счет, его не трогаем)
Надо
Собрать дисковую подсистему для 20 контейнеров (это максимум), рабочий объем данных что нужен в горячем пуле не превышает 1TB, скорости All-Flash не ожидаются, по IOPS требования очень низкие. Возможно доустановить несколько NVMe дисков при необходимости. А также полностью затюнить все критические параметры.
Пока в текущем тестовом стенде сделано так, zfs последняя версия из репо. RAID1 из 2 HDD средствами zfs, 1.6TB под L2ARC, 1 диск на 128GB по ZIL SLOG, 1 диск на 128GB под метаданные (special device). Очевидно что нужен глубокий тюнинг всего этого дела.
Возьмите, если есть возможность, пару intel p1600x под slog, если вам критична синхронная запись. Думаю, даже варианта на 58 гб будет достаточно. Ну и special на модели постарше разместить.
Georg🎞️🎥
нельзя. тем более, что это не лучшая идея в принципе.
Отличная идея из 2 или 4 терновых набрать большой ведев …
Василий
100 тер - это 3 тера меты и оптаны в зеркале .. удачи )))
Откуда такие расчёты? ЕМНИП, при стандартном блоке коэффициент 0,3%
武士
Откуда такие расчёты? ЕМНИП, при стандартном блоке коэффициент 0,3%
сильно зависит от количества пулов. если один, то вы не совсем точны, но и не сильно далеки.
Georg🎞️🎥
Откуда такие расчёты? ЕМНИП, при стандартном блоке коэффициент 0,3%
Тут в группе - от 1 до 5 процентов … я был бы ряд 0,3 👋
Василий
1-5 % Это вероятно в совокупности
с мелким блоком
 George
George
Кстати, можно увеличивать размер блочных устройств в оставе vdev прямо на ходу. Я это использую так: когда не могу определиться с размером special vdev, я выделяю необходимый минимум через lvm и поверх lvm создаю zfs, по мере заполнения special увеличиваю размер через lvm потом прошу zfs учесть изменение размера, места на special прибавляется.
лучше просто партицию по меньше создать сначала и оставить после неё свободное место. Потом можно просто партицию увеличить и zfs умеет подхватить новое пространство через autoexpand
riv
а можно ли как-то сказать zfs сколько в special отдавать под metadata, а сколько под мелкие блоки?
Там есть какие-то настройки, я ихтне копал, т.к не переносил мелкие блоки на special
riv
А его в raidz3 какой нить можно собрать , интересно ?
Можно и а triple mirror и raidz2 и raidz3 как угодно. Но zfs будет ругаться если replication level основных vdev и special отличается, но с елюсом -f соберет пул даже с разным replicatio level и это будет работать. Другое дело, что raidzx меньше дает iops на запись чем несколько mirror.
Василий
 sweetiefox
sweetiefox
В общем всем в группе спасибо за помощь и советы, сделала немного по другому - но получилось так как надо, вот что на текущий момент получилось
sweetiefox
root@power2:/data# fio --filename=test --sync=0 --rw=write --bs=16k --numjobs=20 --iodepth=32 --group_reporting --name=test --filesize=64G --runtime=60
test: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=32
...
fio-3.16
Starting 20 processes
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
test: Laying out IO file (1 file / 65536MiB)
Jobs: 1 (f=1): [E(19),W(1)][100.0%][w=4645MiB/s][w=297k IOPS][eta 00m:00s]
test: (groupid=0, jobs=20): err= 0: pid=681714: Mon Jan 8 07:38:49 2024
write: IOPS=327k, BW=5117MiB/s (5365MB/s)(300GiB/60002msec); 0 zone resets
clat (usec): min=14, max=12136, avg=56.52, stdev=33.08
lat (usec): min=14, max=12137, avg=57.59, stdev=33.12
clat percentiles (usec):
| 1.00th=[ 30], 5.00th=[ 36], 10.00th=[ 40], 20.00th=[ 44],
| 30.00th=[ 48], 40.00th=[ 51], 50.00th=[ 55], 60.00th=[ 58],
| 70.00th=[ 62], 80.00th=[ 67], 90.00th=[ 75], 95.00th=[ 85],
| 99.00th=[ 121], 99.50th=[ 139], 99.90th=[ 198], 99.95th=[ 223],
| 99.99th=[ 293]
bw ( MiB/s): min= 3932, max= 6664, per=100.00%, avg=5120.17, stdev=24.55, samples=2381
iops : min=251688, max=426542, avg=327690.50, stdev=1571.27, samples=2381
lat (usec) : 20=0.02%, 50=37.45%, 100=60.42%, 250=2.08%, 500=0.02%
lat (usec) : 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.01%
cpu : usr=9.12%, sys=82.76%, ctx=8869861, majf=0, minf=129
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,19649546,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
WRITE: bw=5117MiB/s (5365MB/s), 5117MiB/s-5117MiB/s (5365MB/s-5365MB/s), io=300GiB (322GB), run=60002-60002msec
sweetiefox
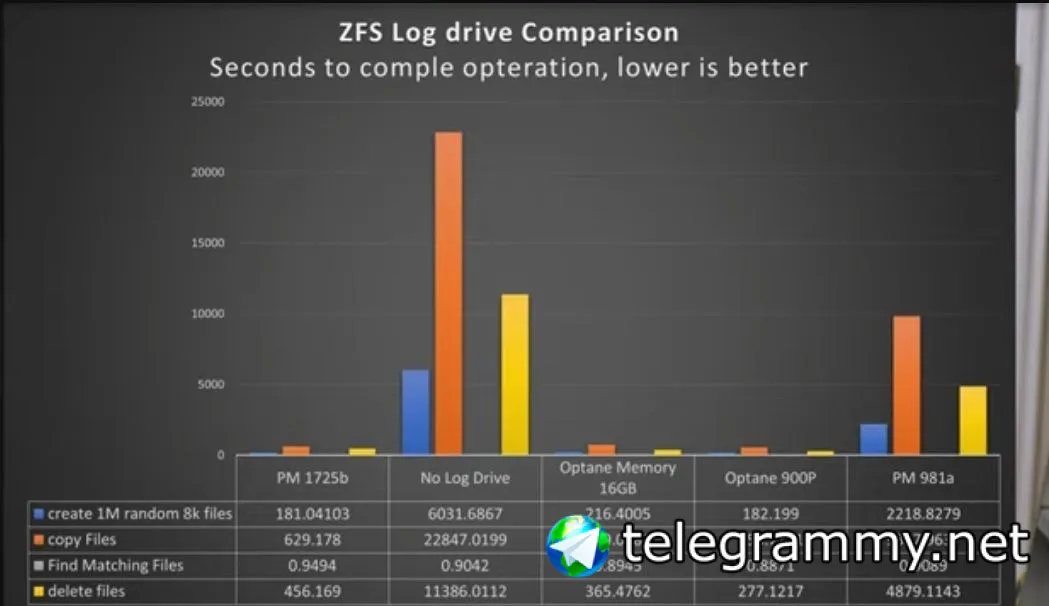
С учетом того что в GP Storage типовой SLA это 3 IOPS/GB, то для дисков в 16ТБ это будет 48kIOPS, а тут получается даже больше :)
P.S. если что - латенси не был критичным показателем, target был GB и IOPS.
sweetiefox
root@power2:/data# fio --filename=test --sync=0 --rw=read --bs=16k --numjobs=20 --iodepth=32 --group_reporting --name=test --filesize=64G --runtime=60
test: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=32
...
fio-3.16
Starting 20 processes
test: Laying out IO file (1 file / 65536MiB)
Jobs: 20 (f=20): [R(20)][100.0%][r=10.7GiB/s][r=699k IOPS][eta 00m:00s]
test: (groupid=0, jobs=20): err= 0: pid=709006: Mon Jan 8 07:42:37 2024
read: IOPS=692k, BW=10.6GiB/s (11.3GB/s)(634GiB/60002msec)
clat (usec): min=7, max=2738, avg=25.05, stdev= 6.10
lat (usec): min=7, max=2739, avg=25.87, stdev= 6.12
clat percentiles (nsec):
| 1.00th=[13760], 5.00th=[16768], 10.00th=[18560], 20.00th=[20608],
| 30.00th=[22144], 40.00th=[23680], 50.00th=[24960], 60.00th=[25984],
| 70.00th=[27264], 80.00th=[28800], 90.00th=[31104], 95.00th=[33536],
| 99.00th=[44288], 99.50th=[48896], 99.90th=[59136], 99.95th=[64256],
| 99.99th=[81408]
bw ( MiB/s): min= 8939, max=11656, per=99.98%, avg=10809.87, stdev=18.19, samples=2383
iops : min=572116, max=746014, avg=691831.27, stdev=1164.18, samples=2383
lat (usec) : 10=0.01%, 20=16.33%, 50=83.23%, 100=0.43%, 250=0.01%
lat (usec) : 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%
cpu : usr=16.00%, sys=83.32%, ctx=800907, majf=0, minf=169
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=41518109,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=10.6GiB/s (11.3GB/s), 10.6GiB/s-10.6GiB/s (11.3GB/s-11.3GB/s), io=634GiB (680GB), run=60002-60002msec
sweetiefox
И вот по линейному чтению результат тоже (если кому-то интересно)
P.S. если кого-то напрягают выкладки - то напишите, все удалю из чата.
 Artem
Artem
В общем всем в группе спасибо за помощь и советы, сделала немного по другому - но получилось так как надо, вот что на текущий момент получилось
Написала-бы, что в итоге было сделано. А то бенчи-то красивые, но...
Илья
sweetiefox
Написала-бы, что в итоге было сделано. А то бенчи-то красивые, но...
В итоге получилось так
md-raid1, сверху на него 1.6TB Samsung PCIe x8 NVMe writeback кэш на базе bcache0 с blocksize=4k и с sequential_cutoff=0, а поверх этого zfs pool с ashift=12, 128GB SSD NVMe SLOG и 1TB special device для блоков < 4k и metadata.
диск Samsung 1.6TB PCIe x8 AIC отформатирован в 4k (low level) + metadata + extra lifetime mode, так что физическая емкость у него не 1.6ТБ, а меньше стала - зато почти бессмертный. такой вот - https://image-us.samsung.com/SamsungUS/PIM/Samsung_1725b_Product.pdf
 Д..Стукалов
Д..Стукалов
 Д..Стукалов
Д..Стукалов

 D E U S
D E U S
Ну да
 Uncel
Uncel
оно пока сырое
Uncel
можно ссылочку? (на конкретные модели если можно)
https://www.raidix.ru/products/era/ https://xinnor.io/what-is-xiraid/
Uncel
он быстрее мд раза в 4
Georg🎞️🎥
можно ссылочку? (на конкретные модели если можно)
О них речь ? За каждый чих денежку … полку надо добавить - тоже плати ))) зато с поддержкой ))
sweetiefox
он быстрее мд раза в 4
там RAID1 поверх 2шт HDD на 16TB - не думаю что там нужны скорости :)
Georg🎞️🎥
там RAID1 поверх 2шт HDD на 16TB - не думаю что там нужны скорости :)
А еще он пипец дорогой )))
sweetiefox
https://www.raidix.ru/products/era/ https://xinnor.io/what-is-xiraid/
 sweetiefox
sweetiefox
Везде где пишут "рекомендовано к импортозамещению" - всегда стоит относиться с осторожностью
Georg🎞️🎥
Везде где пишут "рекомендовано к импортозамещению" - всегда стоит относиться с осторожностью
Хорошие реально , но дорого
 Алексей
D E U S
Алексей
D E U S
https://www.raidix.ru/products/era/ https://xinnor.io/what-is-xiraid/
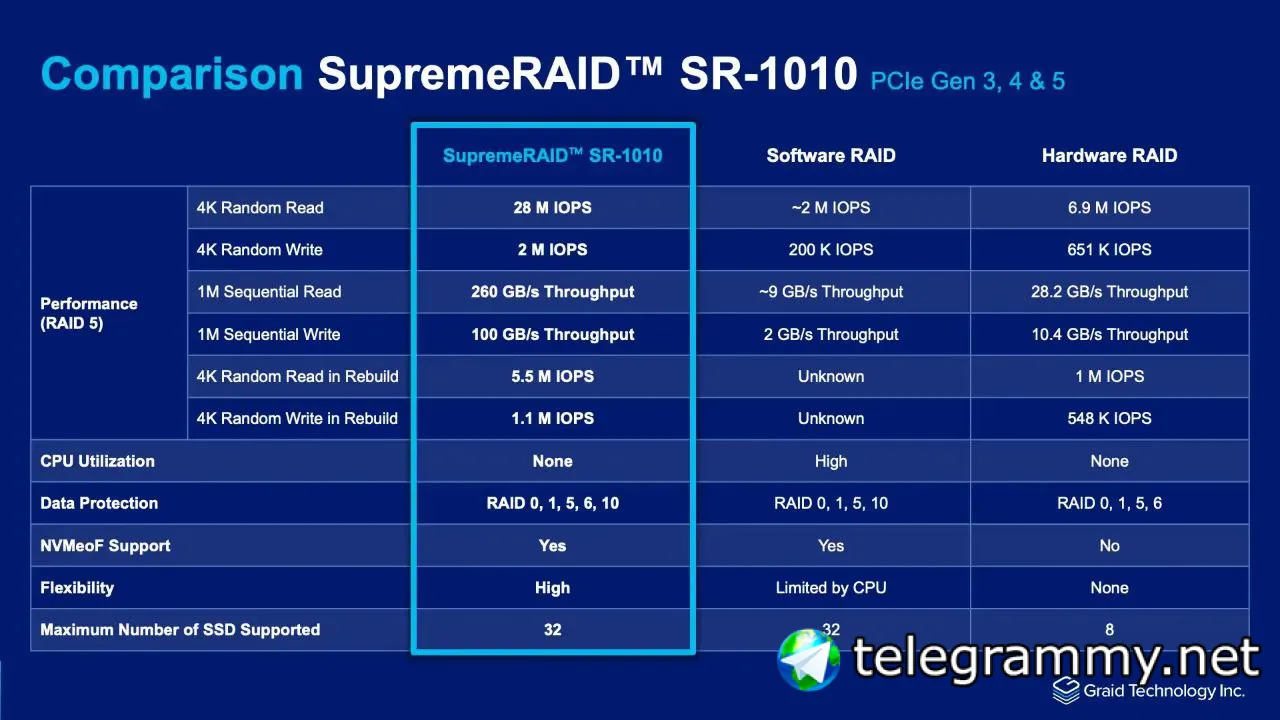
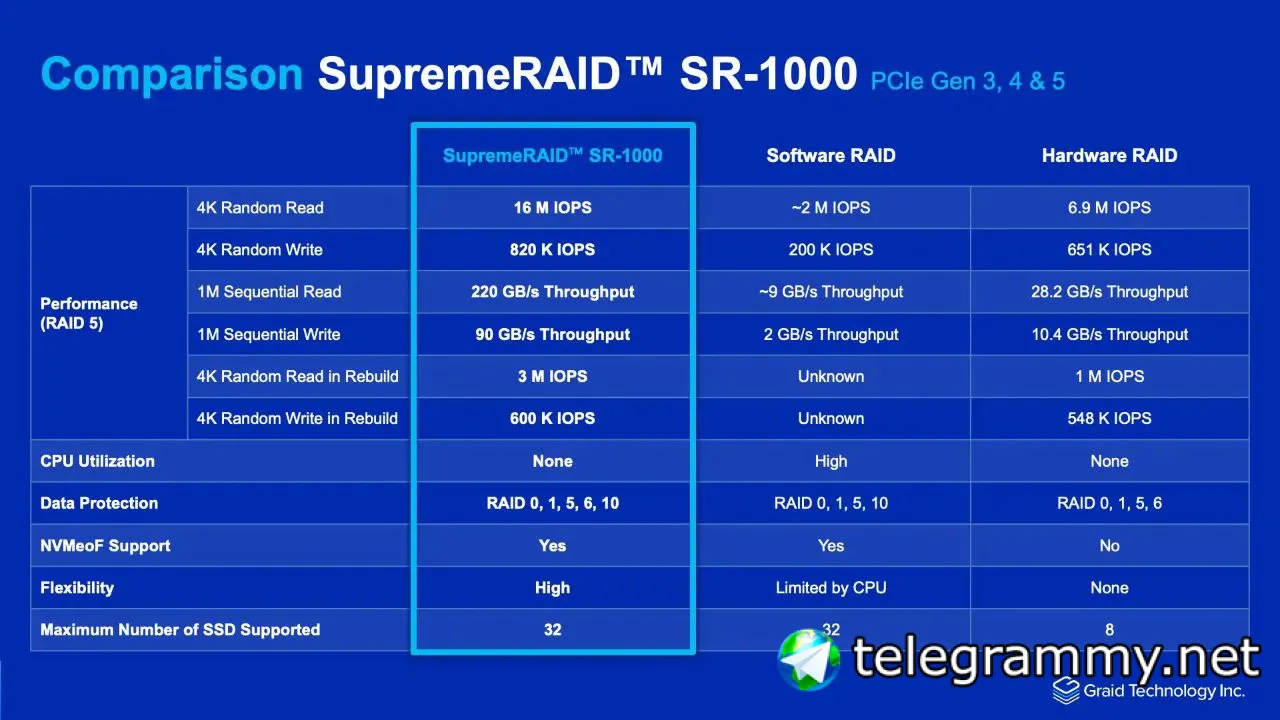
gRAID нраица как идея очень. Тупо использовать жухлую видяху пусть считает parity и в ребилде участвует
Uncel
Uncel
Ты упираешься в полосу карты
D E U S
Она тупо сопроцессор
Uncel
Карта магией хэши считает?
Uncel
Потом вернемся к диалогу
Uncel
Ты не в теме абсолютно
D E U S
Потом вернемся к диалогу
 D E U S
D E U S
Я хуй знает где тут упор в шину карты
Uncel
2млн епсов на запись
Uncel
Здрасте
Uncel
Два оптана
Uncel
Посмотри хотяб на люстру
Uncel
Про vast молчу
D E U S
Ладно покурю на досуге
sweetiefox
И нигде нету цен
sweetiefox
Не люблю таких любителей наводить тень на белый день
 Vladislav
Vladislav
он быстрее мд раза в 4
Спорно, что за херню они там крутили, потому что нет никаких выкладок, просто голое слово, что быстрее, ни какие параметры mdadm, ни какие диски, ничего
Uncel
Uncel
И он не numa aware
Uncel
https://dl.acm.org/doi/abs/10.1145/3538643.3539740
Uncel
https://xinnor.io/blog/the-most-efficient-raid-for-nvme-drives/
Uncel
Про зфс преза аткинсона
Vladislav
https://xinnor.io/blog/the-most-efficient-raid-for-nvme-drives/
*due to the nature of NAND flash, fresh drive write performance differs greatly from sustained performance, once NAND garbage collection is running on the drives*
Сборщик мусора
Enterprise nvme
Они ручками Трим запускали во время работы mdadm что ли?
Uncel
Попробуй дальше дочитать
sweetiefox
sweetiefox
Помню нашей конторе в свое время EMC их втюхать хотела