 sweetiefox
sweetiefox


Там вместо обычных дисков - специальные картриджи где контроллеров типа как нету
 Uncel
Uncel
Как минимум доработали стандарт про ftl
Uncel
В методике snia это описано
Uncel
hpe/cray gridraid делает примерно аналогичное
 武士
武士
Хорошие реально , но дорого
по мне единственный достойный отечественный продукт. имхо. конечно развитие идёт и у других, но этот самый зрелый. дай бог и другие подрастут со временем!!! я за Родину!
 Vladislav
Vladislav
по мне единственный достойный отечественный продукт. имхо. конечно развитие идёт и у других, но этот самый зрелый. дай бог и другие подрастут со временем!!! я за Родину!
Жаль только инженеры что его писали свалили из отечественного продукта
Vladislav
https://xinnor.io/blog/the-most-efficient-raid-for-nvme-drives/
И вместо рейдикса делают
А рейдикс теперь в составе ядра
Vladislav
 Vladislav
Vladislav
Ты упираешься в полосу карты
Совсем старенькой да, но возьмём к примеру 1060 6gb, там скорость памяти 192.2 GB/s,
Даже 24 диска nvme на чтения дают согласно статейке всего 65 ГБ/с (17.3кк iops * 4k /1024/1024)
Uncel
Там немного сложнее чем гигабайты туда-сюда
Vladislav
Чтож, есть хороший способ проверить
https://remontka.pro/gpu-ram-drive/
Даже скорее такой*
https://github.com/Overv/vramfs
Vladislav
Pcie tlp bar
Все ещё не так хорошо проверяется, но если как RAW device затестить, можно проверить насколько это может повлиять на теоретический предел производительности
Vladislav
Там немного сложнее чем гигабайты туда-сюда
Что-то мне подсказывает, что это не тот лимитирующий фактор, учитывая сетевухи на 200/400Г с встроенным gpu
Uncel
Он самый
Uncel
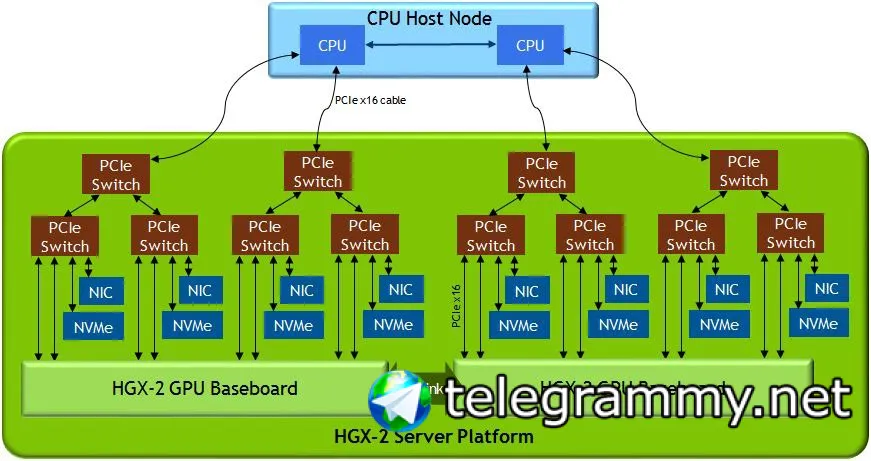
Посмотри на устройство hgx
Georg🎞️🎥

 Uncel
Uncel
Да, можно с него начать
Uncel
У pcie коммутатора есть свои мозги и dma движки
Uncel
У карты вагончик ограничений для быстрого доступа к дискам
Uncel
Оперативка у нее тоже не локальная кстати
Uncel
Собственно пытаясь это обойти, слепили блуфилд
Georg🎞️🎥
Оперативка у нее тоже не локальная кстати
В чем прикол этой штуки - я так понимаю - «протягивать» nvme ?
Uncel
Собственно пытаясь это обойти, слепили блуфилд
Топжир кластерные фс дают примерно 20 млн епсов 4к на запись с узла
Uncel
Под бекапы пойдет
Vladislav
Мне просто интересно, из кластерных ФС (которые доступны для смертных) я знаю цеф, GFS2, гластер, Люстра(?), ну и всё
Не уверен, что что-то из этого жмёт 20кк iops
Uncel
Мне просто интересно, из кластерных ФС (которые доступны для смертных) я знаю цеф, GFS2, гластер, Люстра(?), ну и всё
Не уверен, что что-то из этого жмёт 20кк iops
Люстра сможет, но там переписать кое че надо
Uncel
Даос тоже
Uncel
Века
 George
George
Собственно пытаясь это обойти, слепили блуфилд
мб что новое к блюфилду прилепили, но у него кейс был основной - офлоадить нагрузку с гипервизоров, в первую очередь сеть
Uncel
Uncel
Для EC и прочего PQ
George
Для EC и прочего PQ
О, явно про erasure coding что-то написали в 3ем блюфилде, но не думаю что оно лучше чем рейд контроллер будет отдельный. У него явно всё заточено под проброс в вмку эффективный. Хотя пощупать интересно
Uncel
Uncel
Железный рейд типа броадкома/микрочипа это 4 млн епсов в прыжке
Юрий
Всем привет. Никто не в курсе, можно ли в линуксе каким-то образом получить температуру с sas2308 в режиме it?
Uncel
С рейда или дисков?
Юрий
С самого контроллера
Юрий
Для ir вроде температуру можно снять через storcli, но для it пока ничего не нашёл
Uncel
Если нет, выдернуть ядерную функцию про temp threshold
Юрий
sg нет, есть только mpt2sas и mpt3sas
Юрий
Если нет, выдернуть ядерную функцию про temp threshold
Это читал, но пока не понял как. Буду искать, спасибо
riv
В итоге получилось так
md-raid1, сверху на него 1.6TB Samsung PCIe x8 NVMe writeback кэш на базе bcache0 с blocksize=4k и с sequential_cutoff=0, а поверх этого zfs pool с ashift=12, 128GB SSD NVMe SLOG и 1TB special device для блоков < 4k и metadata.
диск Samsung 1.6TB PCIe x8 AIC отформатирован в 4k (low level) + metadata + extra lifetime mode, так что физическая емкость у него не 1.6ТБ, а меньше стала - зато почти бессмертный. такой вот - https://image-us.samsung.com/SamsungUS/PIM/Samsung_1725b_Product.pdf
Что пооизойдет при silent read error на устройстве под md-raid1? Это когда на устройство было записано одно, а оно вернуло чуточку жруго? Md-raid1 не проверяет корректность данных, если накопитель сам не вернул код ошибке, а думает что он правильные данные отсылает. Ситуация редкая, но рано или поздно возникающая.
Почему вместо raid1 под zfs не сделать mirror в zfs пуле? Это медленнее?
riv
 riv
riv
Мне просто интересно, из кластерных ФС (которые доступны для смертных) я знаю цеф, GFS2, гластер, Люстра(?), ну и всё
Не уверен, что что-то из этого жмёт 20кк iops
Sheepdog может! Но за счет writeback на том или ином уровне. В силу математических причин, не возможно создать быструю и надёжную кластерную систему без writeback. Но в sheepdog это хотя бы настраивается (я только доку по нему читал, сам не запускал).
Vladislav
Vladislav
Что пооизойдет при silent read error на устройстве под md-raid1? Это когда на устройство было записано одно, а оно вернуло чуточку жруго? Md-raid1 не проверяет корректность данных, если накопитель сам не вернул код ошибке, а думает что он правильные данные отсылает. Ситуация редкая, но рано или поздно возникающая.
Почему вместо raid1 под zfs не сделать mirror в zfs пуле? Это медленнее?
Mdadm делает проверки на синхронизацию и silent corruption
Vladislav
Быстрее чем zfs подозреваю что требует серьёзных компромисов: я не изучал, но вангую, что там нет контрольных сумм и чего-то ещё, что замедляет zfs.
https://bcachefs.org/
Full data and metadata checksumming
sweetiefox
Что пооизойдет при silent read error на устройстве под md-raid1? Это когда на устройство было записано одно, а оно вернуло чуточку жруго? Md-raid1 не проверяет корректность данных, если накопитель сам не вернул код ошибке, а думает что он правильные данные отсылает. Ситуация редкая, но рано или поздно возникающая.
Почему вместо raid1 под zfs не сделать mirror в zfs пуле? Это медленнее?
потому что тогда нужно 2 устройства кэширования, а с zfs имеем супер долгую запись на диск
Vladislav
Btrfs-то? Это дааа
sweetiefox
bcache дает лучшую производительность на запись, что сначала пишет в свой жирный 1.6Т кэш, а после с него на диск, из кэша же и вычитывает данные - тем самым получаясь сильно быстрее
Vladislav
Ахахахах, шутку понял, смешно
Vladislav
Что?...
sweetiefox
поможете настроить? готова оплатить если сделаете чтобы также быстро было
riv
потому что тогда нужно 2 устройства кэширования, а с zfs имеем супер долгую запись на диск
Не понял, это почему это два? Zfs cache vdev не требует резервирования. Я вам писал про другое: при выходе из строя cache данные то вы не потеряете и работоспособность сохранится, но производителтность снизится и с точки зрения sla всей системы с предельной нагрузкой этотбудет эквивалентно отказу.
riv
sweetiefox
Не понял, это почему это два? Zfs cache vdev не требует резервирования. Я вам писал про другое: при выходе из строя cache данные то вы не потеряете и работоспособность сохранится, но производителтность снизится и с точки зрения sla всей системы с предельной нагрузкой этотбудет эквивалентно отказу.
смотрите, сейчас ситуация такая
md-raid1 -> md0, к нему подключают диск Samsung PCie x8 и делаем устройство bcache0 в режиме writeback и режиме все данные идут через кэш.
у zfs не удалось сделать так - чтобы было кэширования записей, ибо SLOG это не кэш.
Vladislav
............чтож, ладно, у Вас и btrfs надёжен и с разрабами bcachefs Вы лично знакомы
sweetiefox
на сервере очень мало - только 512GB, и это не чисто СХД, а сервер где контейнеры крутятся. лучше когда используется кэш на 1.6ТБ он явно по лучше будет.