так как строили пул?, на mirror?
Нет там все группами на raidz2
 Shaker
Shaker


 Владимир
Владимир
вы выбрали самый тупой вариант который есть у ZFS
Владимир
а теперь жалуетесь)
 Alex
Alex
Только на уровне нашей задачи сравниваю. Вот к нас шкафы с цеф, работает так. А вот винигрет из zfs, работает так.
Во, у нас тоже большое хранилище тупо тушек файлов. И мы пришли к схеме: берем простой сервак 4U, набиваем его дисками, туда фрю, zfs + наш демон , который файлы раздает по http. И всё, такими юнитами расширяемся =)
Alex
ну перед ним еще предбанник, условный, роутер запросов на эти ноды
Shaker
может ещё и дедупликацию включили?)
Да, на одной хранилке включили, потом долго угорали, как оно тупит )))
Владимир
Да, на одной хранилке включили, потом долго угорали, как оно тупит )))
жесть)), тогда я согласен, сепх быстрее))
Владимир
Вы применили похоже все практики чтобы затормозить zfs))
Alex
Вы применили похоже все практики чтобы затормозить zfs))
Меня смущает описанная схема подключения с полками =) У нас так тоже админы собрали - они сделали ВСЁ, как НЕ рекомендуется. И мы ненавидели zfs :)
Alex
пока не пересобрали по книжке и мудрым советам
Shaker
Ну, если ты сравниваешь zfs mirror и считаешь, что это лучшее, то я бы лучше выбрал ceph с EC 8:3 если у тебя несколько сотен дисков.
Shaker
по иопсам будет сильно хуже, латенси - хуже чем zfs
Shaker
Но когда у тебя сдохнет контроллер, то массив не ляжет.
Alex
Владимир
Да, на одной хранилке включили, потом долго угорали, как оно тупит )))
1. пул собираете на mirror, никаких сложных рейдов
2. Подберите оптимальный размер блока и сжатие под ваш тип данных, предварительно потестируйтесь
3. Чем больше vdev в пуле тем производительнее
4. Ну и конечно нормальные диски, лучше всего если не HDD, а если уж HDD то хорошие + вынести slog устройство отдельно для увеличени производительности записи
5. есть ещё кеш l2arc но тут по обстоятельствам, он далеко не всегда нужен
6. Ну и конечно чем больше ОЗУ тем лучше, но в целом даже с малыми объёмами работает достойно
Shaker
Ребаланс под 500 гбит по кластеру , когда ноду вывели )
Alex
Бохато жить не запретишь =)
Alex
тоды цеф хорошо вам ложится, видимо
Shaker
1. пул собираете на mirror, никаких сложных рейдов
2. Подберите оптимальный размер блока и сжатие под ваш тип данных, предварительно потестируйтесь
3. Чем больше vdev в пуле тем производительнее
4. Ну и конечно нормальные диски, лучше всего если не HDD, а если уж HDD то хорошие + вынести slog устройство отдельно для увеличени производительности записи
5. есть ещё кеш l2arc но тут по обстоятельствам, он далеко не всегда нужен
6. Ну и конечно чем больше ОЗУ тем лучше, но в целом даже с малыми объёмами работает достойно
Полностью согласен, сам такое советую, но это больше для рабочего стораджа.
 George
George
Искал подробности про установку recordsize=4M, нашел эту рекомендацию 👆, но ссылка протухла .
Что там было?
https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Module%20Parameters.html
Alex
>3. Чем больше vdev в пуле тем производительнее
тут завит от нагрузки. больше vdev - больше рандом, больше дисков в одном vdev - больше сиквенс
Shaker
А мне диски с mirror под бэкапы жалко, экономика не сойдется. Если до 500 тер например, то вполне можно как ты пишешь. Дальше, нюансы.
 Roman
Roman
Бохато жить не запретишь =)
Да не так это и дорого. Сейчас 10g по цене мусора, 40g - тоже вполне доступны.
Владимир
>3. Чем больше vdev в пуле тем производительнее
тут завит от нагрузки. больше vdev - больше рандом, больше дисков в одном vdev - больше сиквенс
у меня больше 4рёх вдев не было)), в целом с ростом замечал производительность)
Владимир
А мне диски с mirror под бэкапы жалко, экономика не сойдется. Если до 500 тер например, то вполне можно как ты пишешь. Дальше, нюансы.
сойдётся если будешь бекапить через PBS у которого своя реализация дедупликации которая не тупит))
Alex
у меня больше 4рёх вдев не было)), в целом с ростом замечал производительность)
Ну это математика zfs.
Shaker
Да не так это и дорого. Сейчас 10g по цене мусора, 40g - тоже вполне доступны.
Вот и я про то. mellanox5 100g dual бу уже вполне продаются.
Alex
Да не так это и дорого. Сейчас 10g по цене мусора, 40g - тоже вполне доступны.
Когда покупаешь новое на пару машин да, а перевести весь парк на 40-100г?
Alex
это не считая времени
Alex
время иногда дороже
Shaker
Когда покупаешь новое на пару машин да, а перевести весь парк на 40-100г?
А оптом еще и дешевле купить
Alex
Ободи все хосты и замени там адаптеры еще. И проводочки. И обнови дрова. Ой, а что на фрю 11 этой карточки нет? ой как жаль, вы же переставить систему, да?
Shaker
Ну и еще, в zfs нам очень нравилось переливать с одного стора на другой сотни терабайт, чтобы дефрагментацию произвести, или места там добавить.
Alex
И у вас несколько сотен машин в двух дц. И 4 админа на всё =)
Shaker
Поэтому апгрейд стора длилс месяцами.
Shaker
Но в целом, zfs все равно очень хорошее решение. Но не для больших цельных массивов - меньше 120 дисков.
Shaker
Потому как у нас есть несколько "кэшей" на zfs, с nvme ( raidz ) на 100 tb и все очень хорошо. Но у них срок жизни год-два.
Roman
Shaker
Наша контора - нет, но есть знакомые геодезисты, пробовали его, плевались. Надо будет глянуть.
Shaker
У них zfs в люстре, это то еще решение. Но кстати, отличная ниша для zfs тоже.
 Roman
Roman
У них zfs в люстре, это то еще решение. Но кстати, отличная ниша для zfs тоже.
но ведь люстру пилили под зфс и много чего сделали для хорошей работы.
Roman
Наша контора - нет, но есть знакомые геодезисты, пробовали его, плевались. Надо будет глянуть.
а чего плевались у сивида?
Shaker
а чего плевались у сивида?
Сходу не вспомню точно, могу уточнить. Там важен был быстрый параллельный доступ для рассчетов. Как я понял, вопрос в скорости. Люстра с zfs оказалась самой быстрой, и это на их-то хламожелезе.
Shaker
Смотрели еще BeeGFS, вот она по скорости была в топе с люстрой.
Roman
lizardfs/moosefs - говно без fsync-а и через fuse
beegfs - у квапса разваливался
openafs - оно вообще живо? но признаю, не тестил
lustre - ну понятно что живо, но специфическая вроде вещь всё же и отказоустойчивость в ней встроенная зачаточная
gluster - не слышал положительных отзывов
gfs2, ocfs - для разделяемого блокдевайса
nfs - костыли
juicefs - поделка ещё смешнее чем geesefs
orangefs - тут тоже не тестил
Roman
из сдс чата😁
Shaker
Я в курсе, что там квапс смотрел )) Ну не осилил он beegfs, бывает. Пол года он под нагрузкой проработал, но это было с их платной поддержкой ( запуск и первое сопровождение ).
Shaker
В общем, если ближе к топику zfs. Строить цельные монолитные системы на zfs, с сотнями дисков в пуле, более опасно. Лучше использовать с макс 3 полками, и распихивать между ними данные, может как по аналогии с люстрой. Или своими "скриптами". Такое имхо.
Владимир
/report
Roman
В общем, если ближе к топику zfs. Строить цельные монолитные системы на zfs, с сотнями дисков в пуле, более опасно. Лучше использовать с макс 3 полками, и распихивать между ними данные, может как по аналогии с люстрой. Или своими "скриптами". Такое имхо.
А гибридный подход, когда zfs представляет block management, а поверх уже osd?
Shaker
А гибридный подход, когда zfs представляет block management, а поверх уже osd?
Не пробовали , вроде это устарело как архитектура , нужно почитать.
Юрий
А, утилиту изначально делали под зелёнку… Ну да, у меня красные. Просто у них выставлено 138 (0x8a) или может это нормально
Model Family: Western Digital Red
Device Model: WDC WD40EFZX-68AWUN0
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 12
9 Power_On_Hours 0x0032 088 088 000 Old_age Always - 8948
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1509
В общем, если кому вдруг интересно/полезно, за всё это время LCC дорос до значения 1513. Т.е. парковаться перестали вообще (было некоторое кол-во отключений — тестировал память). Владимир, FYI
 Владимир
Юрий
Владимир
Юрий
В итоге как победили растущий LCC?
idle3ctl -d /dev/sdX
При том в вики арча (п3.6.3) написано, что не рекомендуется. Почему не рекомендуется — не написано. Искал, спрашивал — нигде никто ничего не знает (может быть потому что Москва — порт 5 морей, хз)
Владимир
Юрий
Всё ещё, если честно, не уверен, не зря ли влез в эту историю...
 Free
Free
честно говоря я не тестил лично, по идее только 1 блок будет помечен проблемным, можно сэмитировать и потестить на файликах
 George
George
 Vladislav
Vladislav
Всё верно, а мета по дефолту дублируется так что сбойный сектор не может положить весь пул
Интересно, что при рейде - сбой превышающий redundancy убивает пул
 Fedor
Fedor
В нем сбои другого порядка
Fedor
Либо есть статус ок либо приемлемый, либо нет, и это распространяется на все данные
Vladislav
Пул-рейде, чтобы непоняток по терминологии не было
George
Интересно, что при рейде - сбой превышающий redundancy убивает пул
Если речь про zfs и raidz, то там всё аналогично, при отсутствии избыточности будет недоступен конкретный блок
Vladislav
Если речь про zfs и raidz, то там всё аналогично, при отсутствии избыточности будет недоступен конкретный блок
Интересно, у меня пул фейлится при импорте
Vladislav
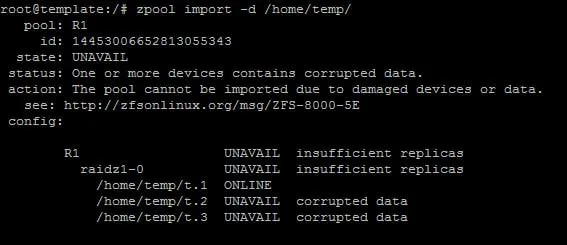 George
George
Вот так если делать
Мету скорее всего побили, протестить надо через поиск конкретных блоков файла через zdb и их обнуление
Vladislav
Владимир
Всем привет, а в zfs работает установка квот юзерам через
quota quotatool
есть такие пакеты, я когда-то давно ими управлял квотами пользователей
Быстрый гуглинг не дал плодов, решил тут спросить)
Vladislav
Владимир
эти пакеты локальными и управляют))
Alex