 Владимир
Владимир


Готово
 Vladislav
Vladislav
Модет быть так, что проще сделать новый пул, потом перелить данные
да, так и планировал.
надо лабу делать и проверять
 Free
Free
Подскажите новичку: можно ли так "починять" пул, или это я обманываю систему и рискую потерять его?
1) Один из дисков перешел в статус FAULTED, устройство (и пул в целом) стало в статусе DEGRADED.
В столбце READ у этого диска 26, но при этом внизу под статусом итогом было прописано
errors: No known data errors
Сделал очистку ошибок этого диска
zpool clear my ata-ST3000VX000-1ES166_Z500K4NV
Статус устройства стал ONLINE.
Можно это списать это на случайный сбой диска и продолжать мониторить, ничего не предпринимая, или же нужно срочно менять диск?
 Vladislav
Vladislav
Когда есть актуальные бэкапы - можно всё
Free
Когда есть актуальные бэкапы - можно всё
На этой системе storj крутится, там бекапы практически бесполезны 🤷♂️
Free
посмотри dmesg на предмет сообщений про этот диск
Много сообщений типа
[89511.136900] blk_update_request: I/O error, dev sdj, sector 2524727320 op 0x0:(READ) flags 0x700 phys_seg 1 prio class 0
Free
рискуешь потерять всё.
Каков порядок замены?
Сразу сейчас выключить, поменять диск и после включения делать zfs replace его?
 Алексей
Алексей
Каков порядок замены?
Сразу сейчас выключить, поменять диск и после включения делать zfs replace его?
последний раз я делал вот так: zpool replace -s poolf wwn-0x5000c500db3a5a67 wwn-0x5000c500c9764682
Алексей
всё еще реплейстися, как зареплейсится я вытащу сбойный
Алексей
Free
последний раз я делал вот так: zpool replace -s poolf wwn-0x5000c500db3a5a67 wwn-0x5000c500c9764682
На время реплейса ноды лучше загасить, чтобы не создавать нагрузку и уменьшить вероятность появления новых ошибок и потери пула?
Алексей
На время реплейса ноды лучше загасить, чтобы не создавать нагрузку и уменьшить вероятность появления новых ошибок и потери пула?
думаю это не будет лишним, да.
по крайней мере я стопанул
Free
А если пул raidz2 и два диска FAULTED - лучше сразу оба реплейсить, или по очереди?
 Animal
Animal
Вопрос к знатокам. Вроде существует рекомендация к ZFS по ОЗУ (вроде в трунас видел) - мин 4Гб + по 1Гб на каждый 1Тб. Ну ОК. А если пул типа RAIDZ1 из 3х одинаковых дисков по 4Тб. Мне дополнительно 16Гб накидывать + 4 = 20 Гб итого. Или взять общую эффективную емкость пула для учета? те 3 диска по 4Тб в raidz1 дадут эффективных ну пусть 12тб. И можно взять 12Гб ОЗУ вместо 16 для расчета?
Алексей
А если пул raidz2 и два диска FAULTED - лучше сразу оба реплейсить, или по очереди?
Я бы по одному делал. И точно всё стопать
Animal
Вы берете raw capacity
ну так я и спрашиваюю как считать? или рекомендация и касается именно raw ? без оглядок на эффективную емкость пула
Animal
те так и брать 4 х 3 = 16Гб и пофиг что эф. емкость будет 12. Так?
Vladislav
 Vladislav
Vladislav
Ну откройте Вы гугл
 Fedor
Fedor
рекомендуется изучить это
https://openzfs.github.io/openzfs-docs/Project%20and%20Community/Admin%20Documentation.html
Fedor
Ну откройте Вы гугл
гугл свиду хоть решает текущую задачу, но потенциально может принести ущерб в будущем, особенно, советы с серверфолт и подобных.
Fedor
те так и брать 4 х 3 = 16Гб и пофиг что эф. емкость будет 12. Так?
зависит, еще от того, будет ли л2арк, какого размера, какого размера блоки в зфс, и так далее.
Fedor
будет ли тот же дедуп
Animal
без дедупа. только компрессия
Animal
l2arc 64Gb
Free
А если пул raidz2 и два диска FAULTED - лучше сразу оба реплейсить, или по очереди?
Заменить сразу сбойный диск, видимо, не получится, поскольку после моей команды clear запустился ресилверинг.
Сейчас дождусь уж его окончания, и тогда буду действовать дальше.
После того, как здесь сразу два диска выдали ошибку в течение короткого времени (неделю назад точно было всё ONLINE) - появилось желание этот пул оптимизировать.
Исторически он мне достался в виде трех виртуальных устройств raidz2, каждый из 10 дисков по 3ТБ. То есть избыточность вроде общая 6 дисков, но вот 2 сбойных попало в одно устройство и уже практически катастрофа.
Есть возможность перенести всё с него временно в другое место, и создать пул с другой конфигурацией.
Итак, задача:
Создать более защищенный от сбоев пул на дисках 30*3ТБ.
Какая конфигурация будет в данном случае оптимальна?
Думал сделать raidz4 на всех 30 дисках, но нагуглил, что raidz4 вообще не бывает.
Делать raidz3, или можно как-то еще сделать - например, зеркало из двух raidz2?
Free
Я бы наверно сделал з3 + мету на ссд зеркале. И еще бы отключил sync прям ща если это сторж
sync отключил после предыдущих рекомендаций, когда от устройств логов и кэша освобождался.
А мета на ссд повышает как-то надежность пула?
Или это для уменьшения нагрузки на hdd?
Алексей
Алексей
Для снижения нагрузки
Алексей
А почему ? Если в тройном зеркале к примеру 😱
Чем больше элементов в системе тем выше выхода из строя всей системы в целом. Это по определению
Алексей
Безотносительно к надежности отдельных элементов в частности
 Александр
Александр
Много сообщений типа
[89511.136900] blk_update_request: I/O error, dev sdj, sector 2524727320 op 0x0:(READ) flags 0x700 phys_seg 1 prio class 0
Что-то дохнет. Возможно, контроллер или кабель
Free
Что-то дохнет. Возможно, контроллер или кабель
Похоже, что, действительно, не диски.
После перезагрузки тот диск, который я сделал clear - остался в статусе ресилвинга, а второй, который был FAULTED - стал сам собой ONLINE без ошибок без всяких действий с моей стороны.
Причем ресилвинг прошел очень быстро. Сначала писал, что сделает его за более 2 суток, но справился за 5 часов, и оба диска теперь ONLINE без единой ошибки.
Вот не знаю - менять ли теперь диски или понаблюдать пока.
Вот только что будет, если это из-за контроллера, и в следующий раз не 2, а сразу 3 диска станут FAULTED?
Пул тут же безвозратно умрет, или, как этот раз, в случае здоровых дисков после перезагрузки все поправится?
 George
George
трансляция OpenZFS Developer Summit 2023 https://www.youtube.com/watch?v=bvTVPwofvLg
Free
smartmontools - смотреть статус
Посмотрел статус одного из дисков, который был FAULTED.
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 119 099 006 Pre-fail Always - 229629512
В переводе с "Сигейтовского" это означает, что НОЛЬ ошибок на 229629512 операций чтения.
То есть, получается, действительно проблема не в дисках, а в контроллере или проводах?
 Александр
Александр
Из того что мне доводилось делать на raid контроллере и на зфс. Замена 2х дисков в 10 массиве накрест приводила к панике. Зфс же отрабатывала, но было долго. Благо диски были живые. Не стоит делать замену сразу двух и более устройств, как бы там схема не была устроена, нагрузка на дисковую подсистему значительна. Да и по нештатной перезагрузке получите меньше проблем.
Александр
В идеале держать spare диск в горячей замене. Тогда проблем будет меньше. Только вот не знаю насчёт диска в резерве, будет ли он крутиться в резерве без нагрузки.
Vladislav
Vladislav
Home - нет
Александр
Александр
Хом часто дёргает диск. Старт стоп. Не известно как лучше. Ровно крутить или часто раскручивать. Старт стоп вроде к добру не приводит
Vladislav
Home = Консумерский сегмент
Vladislav
У них есть spin up\down по таймауту
Vladislav
В Enterprise это делается только командой с контроллер, а так они всегда крутятся
Александр
В Enterprise это делается только командой с контроллер, а так они всегда крутятся
Это когда мы говорим извлечь диск. Он его светит и стопит
Free
Вот похоже. Питалова точно хватает?
Задавался таким вопросом в контексте того - как же при включении питания раскручиваются все эти 30 дисков на ОДНОМ блоке питания?
Проблема в том, что это весьма специфичный корпус, который разобрать очень сложно (чтобы посмотреть на этот БП), а предыдущий хозяин не помнит ни модель, ни характеристики.
Но все-таки он у меня неоднократно выключался при сбоях электричества, и всегда раскручивался.
То есть в уже раскрученном состоянии питания тем более должно хватать
Vladislav
Это когда мы говорим извлечь диск. Он его светит и стопит
*либо когда отдаётся команда spin down или ставится таймер на это
Free
Хом часто дёргает диск. Старт стоп. Не известно как лучше. Ровно крутить или часто раскручивать. Старт стоп вроде к добру не приводит
Мои диски вряд ли останавливаются.
На них Storj работает, который очень серьезно их нагружает постоянно
Free
Задавался таким вопросом в контексте того - как же при включении питания раскручиваются все эти 30 дисков на ОДНОМ блоке питания?
Проблема в том, что это весьма специфичный корпус, который разобрать очень сложно (чтобы посмотреть на этот БП), а предыдущий хозяин не помнит ни модель, ни характеристики.
Но все-таки он у меня неоднократно выключался при сбоях электричества, и всегда раскручивался.
То есть в уже раскрученном состоянии питания тем более должно хватать
Нашел на фото внутренностей этого шкафа его БП - оказался GEX750
http://www.cougar-gaming.ru/index.php?id=203
Vladislav
Нашел на фото внутренностей этого шкафа его БП - оказался GEX750
http://www.cougar-gaming.ru/index.php?id=203
Ставить два блока питания с автосогласованием
Бу...
Задавался таким вопросом в контексте того - как же при включении питания раскручиваются все эти 30 дисков на ОДНОМ блоке питания?
Проблема в том, что это весьма специфичный корпус, который разобрать очень сложно (чтобы посмотреть на этот БП), а предыдущий хозяин не помнит ни модель, ни характеристики.
Но все-таки он у меня неоднократно выключался при сбоях электричества, и всегда раскручивался.
То есть в уже раскрученном состоянии питания тем более должно хватать
Контроллер винтов (тот же RAID-контроллер) подает сигнал старта на винты поочередно, по группам. Все одновременно винты не стартуют - пусковой ток в пределах заложенных разработчиком. Поэтому никаких чудес - уже все продумано за вас.
Vladislav
Контроллер винтов (тот же RAID-контроллер) подает сигнал старта на винты поочередно, по группам. Все одновременно винты не стартуют - пусковой ток в пределах заложенных разработчиком. Поэтому никаких чудес - уже все продумано за вас.
Это смотря что в прошивке этого чудо контроллера написано :)
Бу...
Это смотря что в прошивке этого чудо контроллера написано :)
В смысле? Рядовой контроллер на 4-8 портов уже умеет последовательный запуск. Адаптеки там всякие, например.
Бу...
В смысле? Рядовой контроллер на 4-8 портов уже умеет последовательный запуск. Адаптеки там всякие, например.
 Vladislav
Vladislav
Vladislav
Vladislav
Или просто не обращал на это внимание.
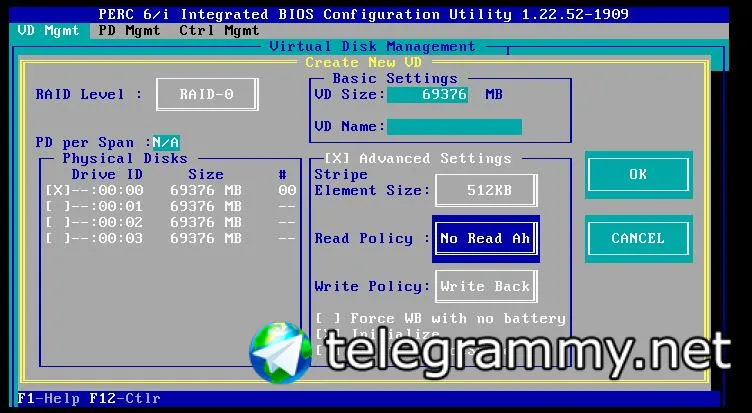
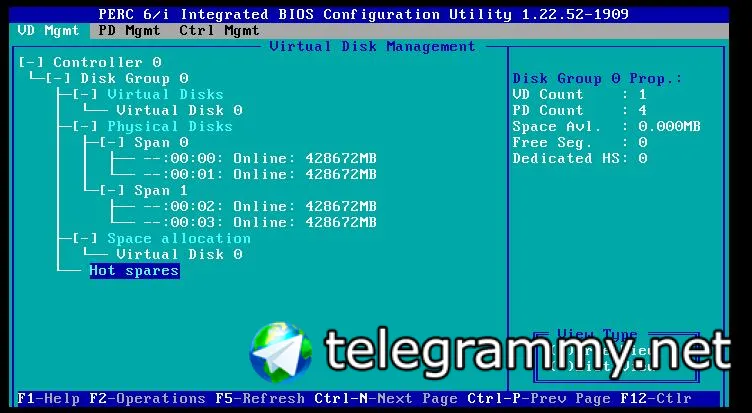
Обращал. Даже скрины всех менюшек делал, чтоб потом иметь инфу, о настройках рейда, без захода на него
Бу...
Обращал. Даже скрины всех менюшек делал, чтоб потом иметь инфу, о настройках рейда, без захода на него
что за контроллер, не помнишь?
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Vladislav
Vladislav
 Бу...
Бу...
 2happy
2happy
подскажите, зачем нужны журналируемые фс? чем черевато отключение журналирование, например у xfs?
за счёт чего файловая система сломаться может, данные на ней же есть, упорядочены, что не так?
Бу...
я привел все опции
Ну значит с конкретным контроллером не судьба или это куда-то в другое место вынесено. В больших контроллерах/хранилках/корзинах - последовательный старт прямо из коробки, иначе бп уйдет в защиту.
Александр
подскажите, зачем нужны журналируемые фс? чем черевато отключение журналирование, например у xfs?
за счёт чего файловая система сломаться может, данные на ней же есть, упорядочены, что не так?
Журналируемые ФС никогда не могут оказаться в состоянии "старые данные уже разрушены, новые еще недописаны". Почему ФС портятся, в одном абзаце не объяснить. Есть Танненбаум, есть Вахалия.
 Alexander 🖨
Alexander 🖨
подскажите, зачем нужны журналируемые фс? чем черевато отключение журналирование, например у xfs?
за счёт чего файловая система сломаться может, данные на ней же есть, упорядочены, что не так?
Сохранение нового файла требует кучи изменений на диске: записать сам файл, добавить метаданные о нем (имя, размещение, даты,...), обновить родительский каталог, обновить информацию о загятом и незанятом, где-то по дороге ещё возможно потребуется какое-нибудь дерево перебалансировать.
Все эти изменения надо либо выполнить полностью, либо не выполнять вовсе, иначе можно много проблем получить. Но нет гарантии, что в середине процесса не выключат свет.
Журнал - это временное место, куда мы сначала пишем все изменения которые хотим сделать. Если на этом этапе сбойнет - не страшно, они ещё не применялись и про них можно и забыть. Когда в журнал все записано, можно обновлять собственно саму фс, если тут сбойнет - сможем продолжить обновление подсмотрев в журнал.
Это один из подходов к обеспечению устойчивости к сбоям. Другой - это copy on write активно используемый в zfs. Тут все обновления пишутся в новое место и от листьев к корню формируется новая ветка метаданных, которая до последнего момента находится вне основного дерева, а в конце происходит единственная перезаписать, атомарно заменяющая старую ветку на новую
George
Журналируемые ФС никогда не могут оказаться в состоянии "старые данные уже разрушены, новые еще недописаны". Почему ФС портятся, в одном абзаце не объяснить. Есть Танненбаум, есть Вахалия.
именно данные - могут))) 99% журналируемых фс по дефолту только мету журналируют
George
90% надобности WAL логов в этом