Если уж тестить обычные ssd - то обычно имеет смысл Full Write делать или по времени гонять
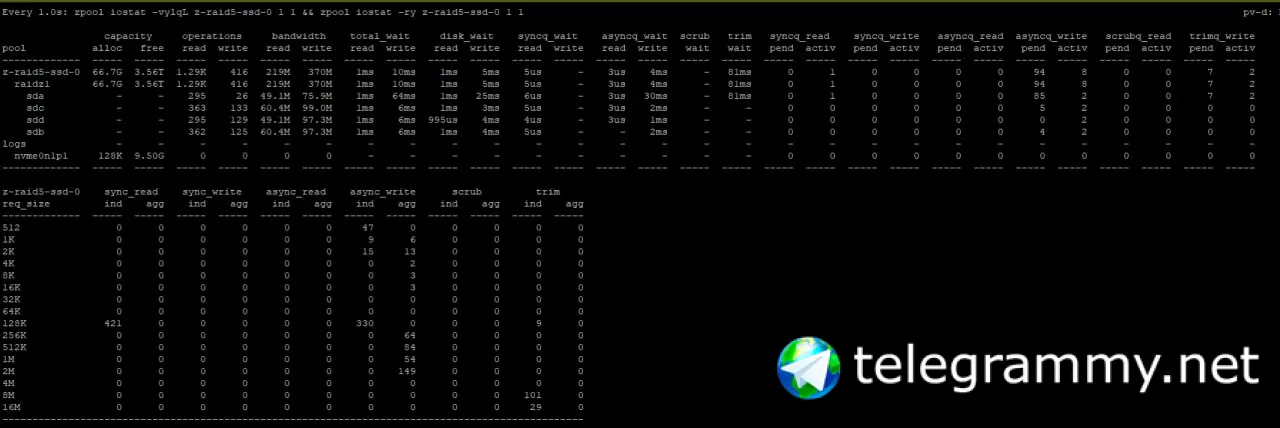
 Dmitriy
Dmitriy

 Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
 Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
 Ivan
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
Ivan
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Dmitriy
Вадим «Дым» Илларионов ☭
Dmitriy
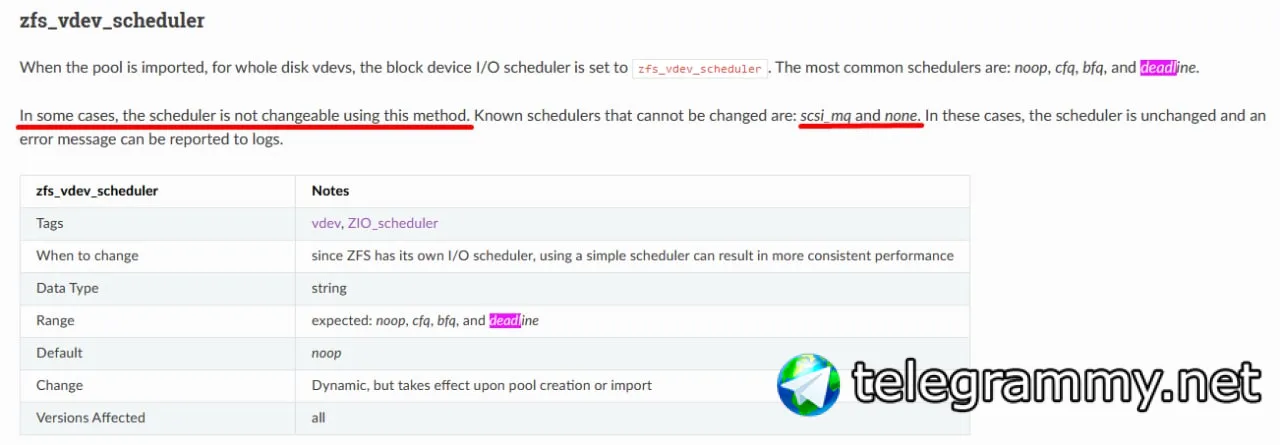 Dmitriy
riv
riv
Dmitriy
riv
riv
 Алексей
Алексей
Алексей
Алексей
Алексей
Алексей
 Vladislav
Vladislav
 Art
riv
Алексей
Art
riv
Алексей
 Aba
Vladislav
riv
riv
Vladislav
Vladislav
Вадим «Дым» Илларионов ☭
Aba
Vladislav
riv
riv
Vladislav
Vladislav
Вадим «Дым» Илларионов ☭
 inqfen
inqfen
inqfen
inqfen
inqfen
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
inqfen
inqfen
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
inqfen
Вадим «Дым» Илларионов ☭
inqfen
inqfen
inqfen
inqfen
inqfen
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
Вадим «Дым» Илларионов ☭
inqfen
inqfen
inqfen
Вадим «Дым» Илларионов ☭
inqfen
Вадим «Дым» Илларионов ☭
inqfen
inqfen
Вадим «Дым» Илларионов ☭