 Dmitriy
Dmitriy

 Dmitriy
Dmitriy
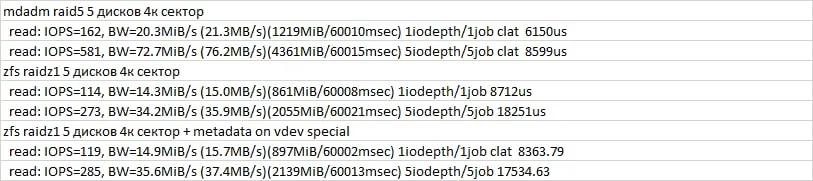
ничего страшного - в тесте там меньше 10 мбайт летит на чтение
 riv
riv
А файл большой для теста?
Dmitriy
50ГБ
riv
не собирается vdev без зеркала
Ради понимания, он собирается так:
zpool create -f newpool raidz /dev/sd{a,b,c,d,e} special /dev/sdf
Если ключа -f не хватает, то нужно использовать -F
Но собирается точно.
Dmitriy
ну ок - сейчас переделаю
Dmitriy
pool: external-sas
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
external-sas ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
s1-d00-part1 ONLINE 0 0 0
s1-d01-part1 ONLINE 0 0 0
s1-d02-part1 ONLINE 0 0 0
s1-d03-part1 ONLINE 0 0 0
s1-d04-part1 ONLINE 0 0 0
special
slog1-part2 ONLINE 0 0 0
logs
slog1-part1 ONLINE 0 0 0
errors: No known data errors
Dmitriy
 riv
riv
50ГБ
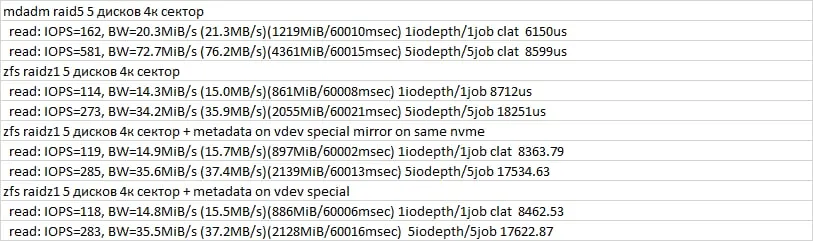
и пепед созданием файла:
zfs set recordsize=16k ...
Протестировать, затем
zfs set checksum=off ...
Dmitriy
riv
Я думаю отключение чексум приблизит результаты к софтрейду, но в продакшеге делать так, конечно не нужно.
riv
Dmitriy
ibm nmon
Dmitriy
 Dmitriy
Dmitriy
сейчас с контрольными суммами и размером 16к проверю
Ivan
хоть бы зеркало с зеркалом сравнивали или raid10. raid5 и raidz1 довольно разные.
 Алексей
Алексей
Со специальным vdev тмпа dedup. Наэто устройство упадет очень много записи и по iops и по объёму, возможно в 100 раз брльше записанных данных.
Мой опыт показал, что при коэффициеете сжатия 2.5х и дедупликации в районе 3х при использовании зеркала из sata intel s3700 можно записывать данные со скоростью ~100Мбит/сек до сжатия и дедупликации, а при использовании в качестве vdev dedup накопителя nvme intel optane 900P или 905P (500 000 iops на запись), скорость записи будет около 1ГБит в секунду (100МБ в сек)
сегодя весь день тестирую dedup vdev.
пул: raidz2 из 8 жестких дисков + 1 ssd под dedup
recordsize=256k
методика тестирования: из /dev/urandom с помощью dd генерится мусор и блоками по 1М пишется в пул.
скорость генерации/записи сырого мусора пока что стабильна и составляет 198 MB/s (быстрее проц не генерит)
чем больше таблица дедупликации, тем больше операций записи на dedup устройстве
по ощущениею скорость записи увеличивается, но не линейно, чем больше данных тем меньше ускорение роста скорости, но тем не менее оно неуклонно растёт
на данный момент записано ~4,5ТБ данных (изначально пул пустой), скорость записи на dedup ~21МБ/сек (усреднненное за 15 секунд)
оставлю генериться мусор до завтра, очень интересно какая будет скорость перезаписи в dedup устройстве когда будет хотя бы пару десятков терабайт.
riv
Dmitriy
хоть бы зеркало с зеркалом сравнивали или raid10. raid5 и raidz1 довольно разные.
просто у меня сомнения - возможно ли выжать из данного сетапа еще IOPs в случайном чтении или это потолок для дисков.
сравнивая с "простым" программным raid - я начал сомневаться
riv
riv
просто у меня сомнения - возможно ли выжать из данного сетапа еще IOPs в случайном чтении или это потолок для дисков.
сравнивая с "простым" программным raid - я начал сомневаться
У меня с диска около 100iops снимается. Я такую величину в голове держу при рассетах. Разумеется я не отключаю суммы.
riv
просто у меня сомнения - возможно ли выжать из данного сетапа еще IOPs в случайном чтении или это потолок для дисков.
сравнивая с "простым" программным raid - я начал сомневаться
Но zfs в попугаях всегда утупала голому железу. Дело не в максимуме попугаев. Потрея попугаев не бесплатна. Как я писал выше, на реальной нагрузке zfs уменьшает iops сваливающиеся на устройства на порядок или больше. второй момент снимки, третий контрольные суммы, котопых нет в рейде.
Если диск начал выдавать кривые данные, софтрейд поубивает всё, а зфс покажет проблему и продержится до замены диска, а если непродержится, то покажет в каких фацлах ошибки.
riv
Прошу прощение за опечатки. Hakers keybord на андройде имеет очень маленькие клавиши. Постоянно промахиваюсь.
Dmitriy
Dmitriy
Но zfs в попугаях всегда утупала голому железу. Дело не в максимуме попугаев. Потрея попугаев не бесплатна. Как я писал выше, на реальной нагрузке zfs уменьшает iops сваливающиеся на устройства на порядок или больше. второй момент снимки, третий контрольные суммы, котопых нет в рейде.
Если диск начал выдавать кривые данные, софтрейд поубивает всё, а зфс покажет проблему и продержится до замены диска, а если непродержится, то покажет в каких фацлах ошибки.
я поэтому и обратился к коллегам - из-за нехватки опыта - оценить насколько мои выводы верны
 Fedor
riv
Fedor
riv
я поэтому и обратился к коллегам - из-за нехватки опыта - оценить насколько мои выводы верны
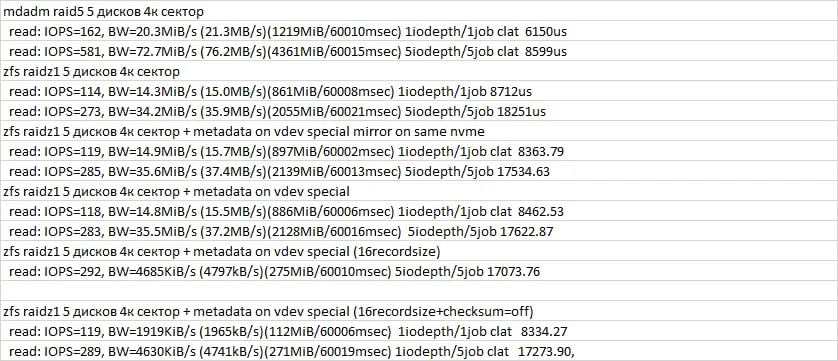
Как там с выключенными суммами?
Dmitriy
 Станислав
Станислав
сегодя весь день тестирую dedup vdev.
пул: raidz2 из 8 жестких дисков + 1 ssd под dedup
recordsize=256k
методика тестирования: из /dev/urandom с помощью dd генерится мусор и блоками по 1М пишется в пул.
скорость генерации/записи сырого мусора пока что стабильна и составляет 198 MB/s (быстрее проц не генерит)
чем больше таблица дедупликации, тем больше операций записи на dedup устройстве
по ощущениею скорость записи увеличивается, но не линейно, чем больше данных тем меньше ускорение роста скорости, но тем не менее оно неуклонно растёт
на данный момент записано ~4,5ТБ данных (изначально пул пустой), скорость записи на dedup ~21МБ/сек (усреднненное за 15 секунд)
оставлю генериться мусор до завтра, очень интересно какая будет скорость перезаписи в dedup устройстве когда будет хотя бы пару десятков терабайт.
Ждал, когда же результаты от вас пойдут)) Как я и писал выше, 100Мбит/с нереально мало.
Только будут ли данные дедупликацированные с /dev/urandom? Мне кажется, что нет
Dmitriy
минорный коммент, но что ж не отдать весь диск зфс? там вроде какое-то кеширование на уровне диска добавляется
пробовал и на голом диске - результат 1:1
кэширование на уровне vdev отключено в модуле - разработчики говорят что не эффективно
Fedor
riv
Алексей
Ждал, когда же результаты от вас пойдут)) Как я и писал выше, 100Мбит/с нереально мало.
Только будут ли данные дедупликацированные с /dev/urandom? Мне кажется, что нет
Конечно нет этого и не должно быть. Цель протестировать нагрузку. Только я не пойму про какие 100мбит вы пишите
riv
Я имел в аиду относительно softraid
Georg🎞️🎥
Нагрузку бы в нагрузке )))
riv
Конечно нет этого и не должно быть. Цель протестировать нагрузку. Только я не пойму про какие 100мбит вы пишите
Это, наверное про мой камент https://t.me/ru_zfs/44676
Georg🎞️🎥
Я свой тестовый гоняю в рабочей нагрузке 🤷🏻♂️пока все нравится, но у меня файлы жирные
Dmitriy
Dmitriy
вот готовлю второй сервер для миграции
riv
пробовал и на голом диске - результат 1:1
кэширование на уровне vdev отключено в модуле - разработчики говорят что не эффективно
еще нажо попробовать fio запустить не на файле а на zvol, кстати изначально так надо было сделать. Давайте сразу с отключенными чексуммами.
zfs creste -V 50G mypool/test.raw
riv
riv
Ещt zfs set atime=off желательно сделать
Dmitriy
это стояло
riv
Есть изменения?
Станислав
Конечно нет этого и не должно быть. Цель протестировать нагрузку. Только я не пойму про какие 100мбит вы пишите
Так если таблица дедупликации пустая, то и время тратить не приходится на поиск совпадений. Получается почти тоже самое, что и с отключенным dedup
Алексей
Так если таблица дедупликации пустая, то и время тратить не приходится на поиск совпадений. Получается почти тоже самое, что и с отключенным dedup
Таблица дедупликации не пустая и растёт как на дрожжах
Станислав
Таблица дедупликации не пустая и растёт как на дрожжах
А, блин, то я под конец дня уже не соображаю. Действительно, каждый блок хранит же
Алексей
Как она может быть пустой если все данные уникальные. Дублей нет, но таблица есть и всё проверяется
Батал Мадяев has been banned! Reason: CAS ban.
Dmitriy
Есть изменения?
на пустом zvol сжатие не дает читать с устройства - получаются искусственно завышенные результаты
 Vladislav
riv
Vladislav
riv
на пустом zvol сжатие не дает читать с устройства - получаются искусственно завышенные результаты
да, точно. Zfs знает куда не писались данные. Надо его заполнить
riv
У меня массив nvme уступает на порядок...
Ждем патчей для nvme. Это не удивительно. У топовых nvme латентность сопоставима с озу. громоздкие механизмы очередей сильно тлрмозят все
Dmitriy
да, точно. Zfs знает куда не писались данные. Надо его заполнить
это поверх ext4 поверх zvol read: IOPS=317, BW=5075KiB/s (5197kB/s)(297MiB/60017msec) латентнось 15 мс
Dmitriy
5 jobs
Dmitriy
сейчас раздел заполнится и прогоню поверх блочного устройства
Dmitriy
 Dmitriy
Dmitriy
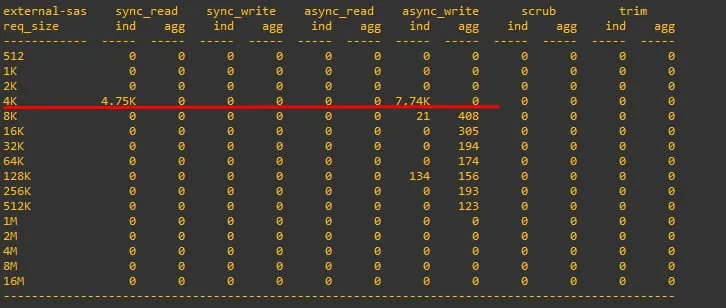
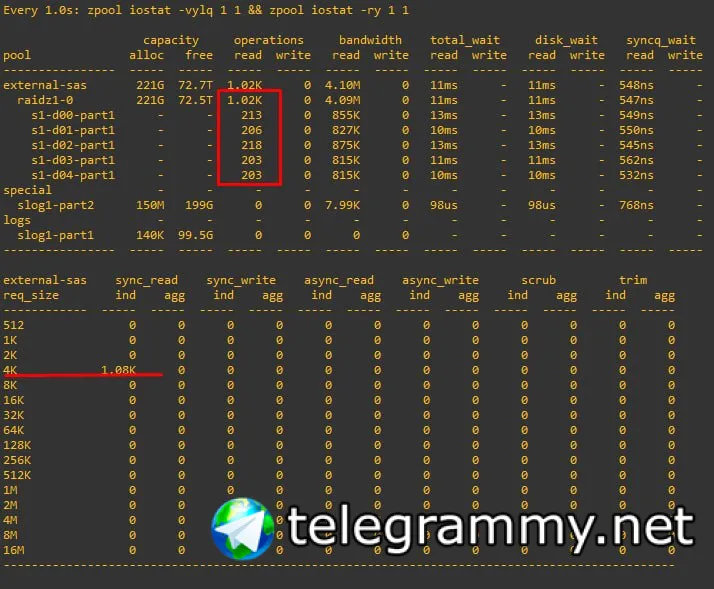
есть предположение что на уровне vdev запрашиваемые в очереди IO данные (где recordsize X) делятся на Y дисков в RAIDZ
я это проверял - похоже если recordsize 64K - а дисков 6 - то ZIO шлет запросы sync read по 64/6 с учетом остатка
Dmitriy
 Dmitriy
Dmitriy
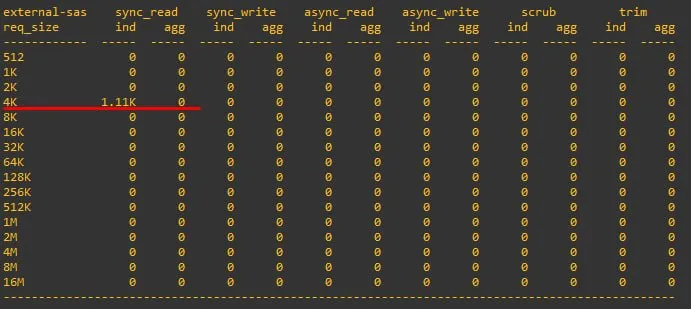
это FIO читает по 16К
Dmitriy
 Vladislav
Vladislav
Ждем патчей для nvme. Это не удивительно. У топовых nvme латентность сопоставима с озу. громоздкие механизмы очередей сильно тлрмозят все
Ждём, а пока я наблюдаю картину из разряда
12.1G на mdadm raid0
2-3G на страйпах zfs
Dmitriy
Ждём, а пока я наблюдаю картину из разряда
12.1G на mdadm raid0
2-3G на страйпах zfs
сегодня смотрел - вроде коммитеры уже одобрили патч
Vladislav
Он в 3.0 будет
Dmitriy
уххх... бл...
Dmitriy
это поверх ext4 поверх zvol read: IOPS=317, BW=5075KiB/s (5197kB/s)(297MiB/60017msec) латентнось 15 мс
голый zvol read: IOPS=304, BW=4871KiB/s (4988kB/s)(286MiB/60024msec) clat 16416.95us 5job
Georg🎞️🎥
У меня массив nvme уступает на порядок...
А что за массив, какого объёма и для чего, если не секрет ?
 George
George
но если делать в один поток - скорость случайного чтения из пула
read: IOPS=176, BW=22.1MiB/s (23.2MB/s)(1327MiB/60001msec)
clat (usec): min=21, max=35997, avg=5648.71, stdev=4481.83
lat (usec): min=21, max=35997, avg=5648.89, stdev=4481.83
строгий однопоток синхронный рандомный не может утилизировать более 1го vdev, а на 1м raidz vdev 1 блок размазан по всем дискам, т.е. на таком кейсе получать иопсы одного самого медленного диска - норма
Плюс если хочется именно на рандом затачиваться, то нужно отключать префетч, он отъест немного иопсов