 George
George


зато параллельный доступ независимый заскейлится на весь пул
George
мб кто-то уже ответил аналогично, сегодня в этом чате много текста)
 riv
riv
есть предположение что на уровне vdev запрашиваемые в очереди IO данные (где recordsize X) делятся на Y дисков в RAIDZ
я это проверял - похоже если recordsize 64K - а дисков 6 - то ZIO шлет запросы sync read по 64/6 с учетом остатка
Насколько я понимаю, 5 дисков raidz1 в них данные распределяются 4х4кб данных, т.е. 16кб эффективный сектор образуется при 4х устройствах данных с секторами по 4кб и 4кб на 5м диске - это паритет.
riv
Если испооьзуются 6 дисков, то надо делать raid-z2
 Vladislav
Vladislav
А что за массив, какого объёма и для чего, если не секрет ?
Просто 6 (уже 9) дисков NVMe разного пошиба (часть серверные, часть пользовательские), для виртуализации, выдающиеся ESXi по 40Г iSER
 Fedor
Fedor
 Dmitriy
Dmitriy
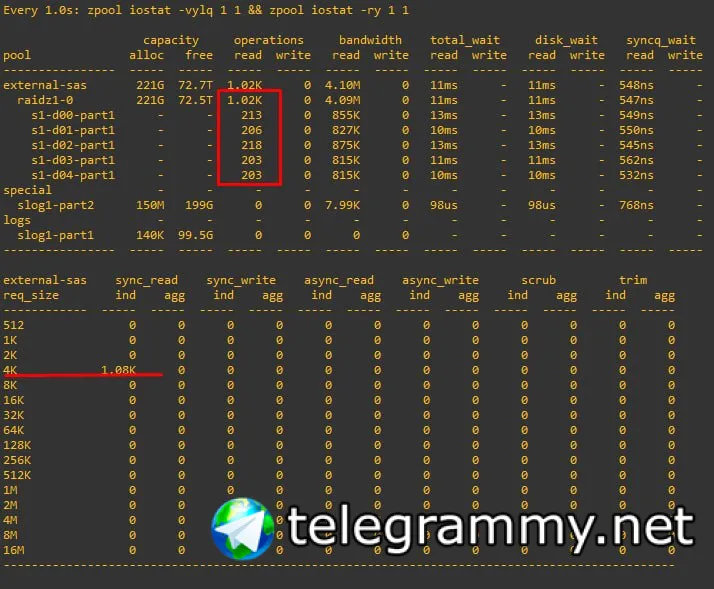
какой хороший иостат. это в линуксе сейчас такой?
комбо watch -n 1 "zpool iostat -vylq 1 1 && zpool iostat -ry 1 1"
Fedor
комбо watch -n 1 "zpool iostat -vylq 1 1 && zpool iostat -ry 1 1"
мне кажется, хорошо время сбора выставлять побольше, чем транзакция, чтоб прямо всё было видно, без скачков.
Dmitriy
мне кажется, хорошо время сбора выставлять побольше, чем транзакция, чтоб прямо всё было видно, без скачков.
важнее не итерация - а накопление. может кто умеет данные парсить и графы строить?
Dmitriy
важнее не итерация - а накопление. может кто умеет данные парсить и графы строить?
а то мне в голову кроме забикса ничего не лезет
 Vladislav
Vladislav
 Sergey
Sergey
а у ISO есть ssh демон?
Привет. Есть и запущен по умолчанию. Но у рута нет пароля, поэтому, для подключения надо сначала либо задать руту пароль, либо создать нового пользователя.
Vladislav
Vladislav
потому что я ищу Live-CD LInux с ssh доступом, чтоб тестировать скрипты.
Образы с уже установленным Linux не всегда передают нюансы при работы в условиях нехватки RAM.
Sergey
потому что я ищу Live-CD LInux с ssh доступом, чтоб тестировать скрипты.
Образы с уже установленным Linux не всегда передают нюансы при работы в условиях нехватки RAM.
тебе нужен образ, который пустит по ssh с дефолтным паролем?
Vladislav
пока не спеши
Vladislav
я может найду
George
 George
George
ну и кстати, не видел, recordsize менялся?
Georg🎞️🎥
у zfs при чтении без кеша всегда будут накладные расходы на вычитывание перед этим меты, ибо cow, плюс как выше писал про префетч, ну и 4к блок для zfs это очень медленный кейс как раз по причине меты. Как, в общем то, есть и кейсы где zfs быстрее чем mdadm) хорошая статья https://arstechnica.com/gadgets/2020/05/zfs-versus-raid-eight-ironwolf-disks-two-filesystems-one-winner/
Скажите , а имеет ли смысл мне спешал городить, когда мне для видео файлов больших префетч оч даже на руку. Частый сценарий - перерендер - когда ещё в кэш не попало, но нужно максимально хорошо читать с Блинов 👋👋👋я так понимаю спешал для мелочи хорош ?👋
George
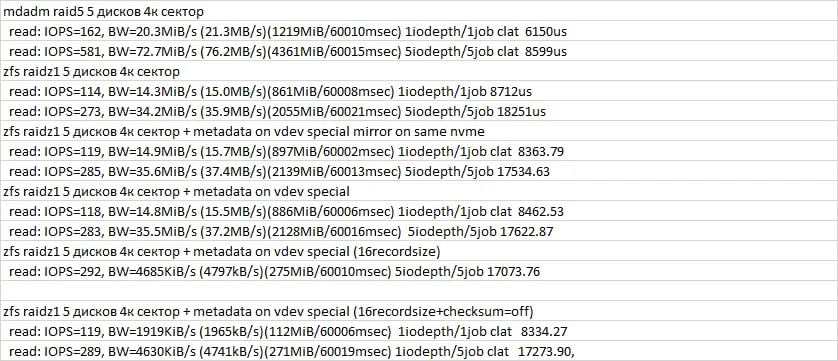
если тестить дефолтные recordsize=128K на 4К случайном доступе то можно и в полосу упереться
George
Скажите , а имеет ли смысл мне спешал городить, когда мне для видео файлов больших префетч оч даже на руку. Частый сценарий - перерендер - когда ещё в кэш не попало, но нужно максимально хорошо читать с Блинов 👋👋👋я так понимаю спешал для мелочи хорош ?👋
надо смотреть сколько мимо кеша мета промахивается, только для кейса мету на спешл вынести
Dmitriy
ну recordsize при тестах меняли на соответствующий нагрузке?
да - FIO генерировало запросы согласованным размером блока
George
в целом если по иопсам в блины упираетесь, то спешл может отлично снять лишние иопсы с них
Dmitriy
Dmitriy
Скажите , а имеет ли смысл мне спешал городить, когда мне для видео файлов больших префетч оч даже на руку. Частый сценарий - перерендер - когда ещё в кэш не попало, но нужно максимально хорошо читать с Блинов 👋👋👋я так понимаю спешал для мелочи хорош ?👋
линейное чтение больших файлов с включенным префетчем дает прекрасные результаты - в моем случае 80% от аналогичного по топологии mdraid
Vladislav
спс. так какая пакетная база? pacman ?
George
прирост есть 2-5%
это я выше отвечал, если что) на рандом только если спешл оч быстрый и в мету упёрлись
Georg🎞️🎥
линейное чтение больших файлов с включенным префетчем дает прекрасные результаты - в моем случае 80% от аналогичного по топологии mdraid
 Georg🎞️🎥
Georg🎞️🎥
надо смотреть сколько мимо кеша мета промахивается, только для кейса мету на спешл вынести
А кэш откуда , коли я только файлы скопировал и кинул их на рендер? Типа ещё кэш пустой ж ?
riv
А кэш откуда , коли я только файлы скопировал и кинул их на рендер? Типа ещё кэш пустой ж ?
Zfs не кэширует линейное чтение. Только то что имеет смысл чтобы сэкономить iops.
Georg🎞️🎥
Zfs не кэширует линейное чтение. Только то что имеет смысл чтобы сэкономить iops.
Да елки, это понятно )))
Спасибо 👋👋👋вроде есть команда заставить его кэшировать поток )
 Алексей
Алексей
сегодя весь день тестирую dedup vdev.
пул: raidz2 из 8 жестких дисков + 1 ssd под dedup
recordsize=256k
методика тестирования: из /dev/urandom с помощью dd генерится мусор и блоками по 1М пишется в пул.
скорость генерации/записи сырого мусора пока что стабильна и составляет 198 MB/s (быстрее проц не генерит)
чем больше таблица дедупликации, тем больше операций записи на dedup устройстве
по ощущениею скорость записи увеличивается, но не линейно, чем больше данных тем меньше ускорение роста скорости, но тем не менее оно неуклонно растёт
на данный момент записано ~4,5ТБ данных (изначально пул пустой), скорость записи на dedup ~21МБ/сек (усреднненное за 15 секунд)
оставлю генериться мусор до завтра, очень интересно какая будет скорость перезаписи в dedup устройстве когда будет хотя бы пару десятков терабайт.
промежуточный итог:
записано мусора ~14.5ТБ
размер DDT ~26.2ГБ
скорость генерации/записи мусора 189МБ/сек
скорость записи на dedup ~20МБ/сек
скорость чтения на dedup ~7МБ/сек
скорость записи мусора начала деградировать т.к. дешманский ssd уперся в свои возможности и загружен на 100%
пишем дальше...
 central
central
а какой смысл? dedup же в таких кейсах не используют все равно
Алексей
кстати если кто знает как генерировать мусора быстрее/больше буду признателен.
один процесс дд грузит ядро на 100%, второй поток начинает делить пополам скорость генерации и больше сгенерить мусора чем одним ядром не получается.
 Aleksandr
Aleksandr
Камрады, кто нибудь использует TruNAS Scale? Поставил новый сервер с 8 дисками по 14 ТБ, говорю ему собери raidz1. Стоит тупит, полчаса, час тупит, полез в консоль смотреть что там происходит, а там какая-то дичь. Он стоит и собирает mdadm raid6. Причем система тоже стоит на mdadm raid1, поверх которого ZFS mirror.
Посмотрел соседний TrueNAS Scale там raidz1 поврерх mdadm raid1, янихуанипони что это за наркомания???
https://pastebin.pl/view/c3d687ce
Aleksandr
zfs поверх mdam?
Да, гляньте консольный вывод который я в pastebin закинул (большая портянка)
central
Да, гляньте консольный вывод который я в pastebin закинул (большая портянка)
да тут дальше уже кажись смысла смотреть нету
Fedor
зфс необходимо ставить напрямую на диски, без подложек.
Aleksandr
я не эксперт по mdadm, может там какие-то хитрости, меня вот это смутило:
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md125 : active raid1 sde1[1] sdc1[0]
2097088 blocks super non-persistent [2/2] [UU]
md126 : active raid1 sdd1[1] sdb1[0]
2097088 blocks super non-persistent [2/2] [UU]
md127 : active raid1 sdf4[1] sda4[0]
16777216 blocks super non-persistent [2/2] [UU]
blocks super non-persistent
Aleksandr
зфс необходимо ставить напрямую на диски, без подложек.
да это я в курсе, от того и вопрос, что за дичь творит TrueNAS Scale
Fedor
может быть, на старых дисках осталась метка мдадма и он как-то поверх нее воткнулся
Vladislav
Учитывая полное отсутствие инфы про это в гугле - форматните первые 10МБ дисков через dd
 Egor
Egor
Опасно)
Vladislav
К тому же судя по всему сервер ещё не используется, поэтому проблем с данными нет
Sergey
Учитывая полное отсутствие инфы про это в гугле - форматните первые 10МБ дисков через dd
В зависимости от версии метаданных, md raid хранит суперблок в начале, середине, или конце диска, поэтому лучше использовать mdadm —zero-superblock или wipefs
Aleksandr
Установил TruNAS Scale на новую виртуалку:
Linux truenas 5.10.131+truenas #1 SMP Mon Aug 8 16:39:36 UTC 2022 x86_64
TrueNAS (c) 2009-2022, iXsystems, Inc.
All rights reserved.
TrueNAS code is released under the modified BSD license with some
files copyrighted by (c) iXsystems, Inc.
For more information, documentation, help or support, go here:
http://truenas.com
Welcome to TrueNAS
Last login: Wed Aug 24 02:28:46 PDT 2022 on pts/0
Warning: the supported mechanisms for making configuration changes
are the TrueNAS WebUI, CLI, and API exclusively. ALL OTHERS ARE
NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY
RESULT IN SYSTEM FAILURE.
root@truenas[~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 32G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 512M 0 part
└─sda3 8:3 0 31.5G 0 part
sdb 8:16 0 32G 0 disk
├─sdb1 8:17 0 1M 0 part
├─sdb2 8:18 0 512M 0 part
└─sdb3 8:19 0 31.5G 0 part
sdc 8:32 0 10G 0 disk
├─sdc1 8:33 0 2G 0 part
│ └─md127 9:127 0 2G 0 raid1
│ └─md127 253:0 0 2G 0 crypt [SWAP]
└─sdc2 8:34 0 8G 0 part
sdd 8:48 0 10G 0 disk
├─sdd1 8:49 0 2G 0 part
│ └─md127 9:127 0 2G 0 raid1
│ └─md127 253:0 0 2G 0 crypt [SWAP]
└─sdd2 8:50 0 8G 0 part
sde 8:64 0 10G 0 disk
├─sde1 8:65 0 2G 0 part
│ └─md126 9:126 0 2G 0 raid1
│ └─md126 253:1 0 2G 0 crypt [SWAP]
└─sde2 8:66 0 8G 0 part
sdf 8:80 0 10G 0 disk
├─sdf1 8:81 0 2G 0 part
│ └─md126 9:126 0 2G 0 raid1
│ └─md126 253:1 0 2G 0 crypt [SWAP]
└─sdf2 8:82 0 8G 0 part
sdg 8:96 0 10G 0 disk
├─sdg1 8:97 0 2G 0 part
│ └─md125 9:125 0 2G 0 raid1
│ └─md125 253:2 0 2G 0 crypt [SWAP]
└─sdg2 8:98 0 8G 0 part
sdh 8:112 0 10G 0 disk
├─sdh1 8:113 0 2G 0 part
│ └─md125 9:125 0 2G 0 raid1
│ └─md125 253:2 0 2G 0 crypt [SWAP]
└─sdh2 8:114 0 8G 0 part
sdi 8:128 0 10G 0 disk
├─sdi1 8:129 0 2G 0 part
│ └─md124 9:124 0 2G 0 raid1
│ └─md124 253:3 0 2G 0 crypt [SWAP]
└─sdi2 8:130 0 8G 0 part
sdj 8:144 0 10G 0 disk
├─sdj1 8:145 0 2G 0 part
│ └─md124 9:124 0 2G 0 raid1
│ └─md124 253:3 0 2G 0 crypt [SWAP]
└─sdj2 8:146 0 8G 0 part
sr0 11:0 1 1.5G 0 rom
root@truenas[~]# mdadm -D 127
mdadm: cannot open 127: No such file or directory
root@truenas[~]# mdadm -D /dev/md127
/dev/md127:
Version :
Creation Time : Wed Aug 24 02:29:34 2022
Raid Level : raid1
Array Size : 2097088 (2047.94 MiB 2147.42 MB)
Used Dev Size : 2097088 (2047.94 MiB 2147.42 MB)
Raid Devices : 2
Total Devices : 2
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Number Major Minor RaidDevice State
0 8 33 0 active sync /dev/sdc1
1 8 49 1 active sync /dev/sdd1
root@truenas[~]# zpool status
pool: boot-pool
state: ONLINE
status: Some supported and requested features are not enabled on the pool.
The pool can still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
config:
Aleksandr
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb3 ONLINE 0 0 0
sda3 ONLINE 0 0 0
errors: No known data errors
pool: data
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
0d9a38a9-28c5-46e6-b636-254d1ae8eabd ONLINE 0 0 0
79d59d79-9313-43ee-8350-fec5e4eb2cae ONLINE 0 0 0
d9c8d709-f7ca-43d5-a321-c755e74fae8e ONLINE 0 0 0
da959b19-7690-48e2-8d45-2f8b3d0116e5 ONLINE 0 0 0
13fe38e0-0594-4838-9733-b533bf94405d ONLINE 0 0 0
6c53fdb7-48d8-4165-a047-c3f0ef2ea5eb ONLINE 0 0 0
8aea84ab-de0d-458f-b0cb-970efe15bb53 ONLINE 0 0 0
6ef9a5cf-d6d9-4c26-96c9-dfeb027ea0c7 ONLINE 0 0 0
errors: No known data errors
root@truenas[~]#
Vladislav
Все понял
Vladislav
https://www.truenas.com/community/threads/i-wonder-why-mdadm-for-swap-instead-of-zfs.95816/
Vladislav
У вас mdadm поверх свопа (2гб) создаётся, я на размер не обратил внимание
Aleksandr
У вас mdadm поверх свопа (2гб) создаётся, я на размер не обратил внимание
Да, точно, так и есть, не очень внимательно смотрел. Спасибо!
 Δαρθ
Δαρθ
кстати если кто знает как генерировать мусора быстрее/больше буду признателен.
один процесс дд грузит ядро на 100%, второй поток начинает делить пополам скорость генерации и больше сгенерить мусора чем одним ядром не получается.
1. в 5.18 с этим получше (/dev/urandom в смысле)
2. юзай openssl шифруя им /dev/zero
Алексей
1. в 5.18 с этим получше (/dev/urandom в смысле)
2. юзай openssl шифруя им /dev/zero
ГЕНИАЛЬНО! СПАСИБО!!
 The Join Captcha Bot
The Join Captcha Bot
Капча решена, Пользователь подтвержден.
Добро пожаловать в чат, @Balex0ne
Nikolay
Не фатально. Разница не в пользу zfs - это норма )
Кое что надо знать об этих результатах. Ещё только появился zfsonlinux, а у меня была проблема: softraid raid10 из 10 дисков 10k rpm поверх коьорого был lvm с образами libvirt-виртуальных машин упирался в iops. Когда ситуауия усугибилась, попробовпли zfs и нагрузка упала процентов на 90.
есть методика позволчющая записать реальную нагрузку и проигрывать её на реальные блочные устройства.
@Zer6918 поделитесь пожалуйста, что за методика записи нагрузки?
Алексей
промежуточный итог:
записано мусора ~14.5ТБ
размер DDT ~26.2ГБ
скорость генерации/записи мусора 189МБ/сек
скорость записи на dedup ~20МБ/сек
скорость чтения на dedup ~7МБ/сек
скорость записи мусора начала деградировать т.к. дешманский ssd уперся в свои возможности и загружен на 100%
пишем дальше...
промежуточный итог2:
записано мусора ~26,6ТБ
размер DDT ~50,5ГБ
скорость генерации/записи мусора 167МБ/сек
скорость записи на dedup ~20МБ/сек
скорость чтения на dedup ~7МБ/сек
заполненность пула 64%
фрагментация 0%
можно констатировать что скорость генерации/записи мусора продолжает деградировать, а объем данных читаемых/записываемых в dedup устройство стабилизировался. К сожалению точных метрик я не снимал, но выглядит так, что чем больше размер DDT, тем больше dedup устройству приходится совершать операций read (при внешне одинаковом объеме прочитанных данных), отнимая при этом свободный ресурс который остаётся для write операций, тем самым понижая итоговую скорость записи мусора.
пишем дальше...
Алексей
а ты по себе других не суди
 Владимир
Владимир
А если свободной озу больше, почему её не использовать?
Владимир
ОЗУ что для прикола стоит чтобы так глупо ограничивать?