если du -s запускать периодически (например пару раз в день) - следующие разы быстрее
но быстрее - это 5-8 минут
 Nick
Nick


 George
George
подскажите, raidz1, крутящиеся диски, du -s занимает 21 минуту на сервере без нагрузки. Что можно покрутить в настройках zfs, чтобы стало существенно быстрее?
относительно гарантированный вариант - special alloc class, но до подключения стоит потестить удовлетворит ли, т.к. потом не отсоединить
А так за день из кеша часть меты 99% вымывается, `Metadata cache size (current): 88.1 % 13.7 GiB` это сразу после прогона или до?
George
подскажите, raidz1, крутящиеся диски, du -s занимает 21 минуту на сервере без нагрузки. Что можно покрутить в настройках zfs, чтобы стало существенно быстрее?
эм, вам занятое пространство только нужно? самый дешёвый путь - нужное место превратить в датасет и брать его свойства
Nick
относительно гарантированный вариант - special alloc class, но до подключения стоит потестить удовлетворит ли, т.к. потом не отсоединить
А так за день из кеша часть меты 99% вымывается, `Metadata cache size (current): 88.1 % 13.7 GiB` это сразу после прогона или до?
в той географии нет технической возможности выбрать другой набор дисков.
метадата - сейчас это уже после, но вообще это примерно постоянно.
Nick
эм, вам занятое пространство только нужно? самый дешёвый путь - нужное место превратить в датасет и брать его свойства
в этой задаче - приходится делать du -s разных подкаталогов в разном сочетании.
Нельзя все подкаталоги превратить в датасеты )
George
в этой задаче - приходится делать du -s разных подкаталогов в разном сочетании.
Нельзя все подкаталоги превратить в датасеты )
а насколько быстрее если сразу после ещё раз запустить? Чтобы понять скорость когда мета ещё в кеше точно
George
если только кешем решать - то увы только увеличивать его размер и регулярно прогревать, если всё же вымывается
Nick
real 2m18.759s
user 0m2.516s
sys 0m11.907s
~ 15 минут спустя предыдущего раза.
в raidz1 диска 3 по 10 терабайт.
Linux 5.4.0-96-generic 2.1.1-0york0~18.04
в процессе - du ест примерно 11% проца, иовейт подрастает до 8-12%
Nick
ARC size (current): 91.1 % 14.2 GiB
Target size (adaptive): 91.0 % 14.2 GiB
Min size (hard limit): 6.2 % 995.1 MiB
Max size (high water): 16:1 15.5 GiB
Most Frequently Used (MFU) cache size: 97.4 % 7.6 GiB
Most Recently Used (MRU) cache size: 2.6 % 206.9 MiB
Metadata cache size (hard limit): 100.0 % 15.5 GiB
Metadata cache size (current): 86.2 % 13.4 GiB
Dnode cache size (hard limit): 75.0 % 11.7 GiB
Dnode cache size (current): 23.3 % 2.7 GiB
Nick
но вообще в теории - это проблема количества файлов и вымывания кеша или чего-то еще? Кеш - метадата или дноде кеш сайз?
George
но вообще в теории - это проблема количества файлов и вымывания кеша или чего-то еще? Кеш - метадата или дноде кеш сайз?
Емнип размер в dnode, можете проверить посмотрев что из них увеличится после прогона
George
Но 86% занятой меты может быть немного на грани забитости. Да, больше файлов - больше чтения меты - больше меты в кеше
Nick
ок, понял, спасибо
Nick
в процессе похоже
Most Recently Used (MRU) cache size падает
а Metadata cache size (current) - растет
 nikolay
nikolay
Но 86% занятой меты может быть немного на грани забитости. Да, больше файлов - больше чтения меты - больше меты в кеше
Интересно, а тупняк пи подаче ls -l из этой же оперы?
George
Интересно, а тупняк пи подаче ls -l из этой же оперы?
Ага, на любой фс. Вообще на больших директориях ключ -l противопоказан
George
В плане меты интересно почитать как рекомендуют юзать lustre, у неё мета относительно централизована и не особо скейлится https://www.nas.nasa.gov/hecc/support/kb/lustre-best-practices_226.html
nikolay
Ага, на любой фс. Вообще на больших директориях ключ -l противопоказан
Без -l тоже минут по 5-7 ожидать приходится. В директории примерно 100к файлов, это много для zfs?
George
Без -l тоже минут по 5-7 ожидать приходится. В директории примерно 100к файлов, это много для zfs?
Зависит от многих факторов, но на любой фс работу с метой в директории с больше 10к файлов стоит не общими вещами делать а стараться получить только нужное. Вообще правильнее всего разбивать на поддиректории
nikolay
Зависит от многих факторов, но на любой фс работу с метой в директории с больше 10к файлов стоит не общими вещами делать а стараться получить только нужное. Вообще правильнее всего разбивать на поддиректории
Гм, не соглашусь, для 100к файлов ext4 и xfs строят листинги без проблем
nikolay
Зависит от многих факторов, но на любой фс работу с метой в директории с больше 10к файлов стоит не общими вещами делать а стараться получить только нужное. Вообще правильнее всего разбивать на поддиректории
Ещё вопрос возник - когда переполниться special vdev мета начнет писаться на обычные vdev с резким падением по производительности?
George
Гм, не соглашусь, для 100к файлов ext4 и xfs строят листинги без проблем
Зависит от, опять же, у меня есть пример с жирным массивом на xfs, конечно фс не простаивает в процессе, листинг с тысячей файлов весьма не моментален, если мета не в озу (а в xfs она оч быстро вымоется ещё)
George
В общем без условий по железу и тестов о цифрах не поговорить
George
Ещё вопрос возник - когда переполниться special vdev мета начнет писаться на обычные vdev с резким падением по производительности?
Да, только падение производительности опять же зависит от того, насколько вам special vdev помогал, тут стоит следить за местом
nikolay
Да, только падение производительности опять же зависит от того, насколько вам special vdev помогал, тут стоит следить за местом
Ага, а зеркало я же могу расширить путём добавления новых дисков в special vdev, это уже поддерживается вроде
George
Ага, а зеркало я же могу расширить путём добавления новых дисков в special vdev, это уже поддерживается вроде
просто новый special vdev добавлять можно
George
зеркало только размером диска увеличить можно через замену. Тут всё как у обычных vdevs
nikolay
просто новый special vdev добавлять можно
Логично, запись меты после добавления нового vdev автоматом на него пойдёт?
George
Логично, запись меты после добавления нового vdev автоматом на него пойдёт?
будет балансироваться между всеми special vdev автоматом, на перезаписи меты заполненный vdev даже будет освобождаться, т.к. zfs стремится к равенству заполненного места
nikolay
nikolay
зеркало только размером диска увеличить можно через замену. Тут всё как у обычных vdevs
Интересно когда уже подвезут нормальное расширение vdev..
George
Интересно когда уже подвезут нормальное расширение vdev..
ну зеркало только через страйпы расширяется. raidz да, в процессе
nikolay
ну зеркало только через страйпы расширяется. raidz да, в процессе
Выше написали что только заменой дисков на более объемные? Я запутался
George
Выше написали что только заменой дисков на более объемные? Я запутался
ну миррор безотносительно zfs именно как набор 2+ дисков только через увеличение объёма диска сам можно увеличить.
В общем zfs с миррорами расширяется прекрасно через vdevs, как и с raidz
Для raidz такое менее удобно т.к. он уже теоретически расширяем через добавление в него дисков, и raidz vdev обычно состоит из бОльшего количества дисков чем 2-3 в мирроре
 Δαρθ
Δαρθ
Зависит от многих факторов, но на любой фс работу с метой в директории с больше 10к файлов стоит не общими вещами делать а стараться получить только нужное. Вообще правильнее всего разбивать на поддиректории
сделал 100к пустых файлов в ехт4
после сброса дисковых кешей, ls -l >/dev/null работает 1..1.5 секунд, du -s . -- 0.5 c
диски крутящиеся, raid1
Δαρθ
повторил в зфс (те же диски в раидз2) -- 0.5с и 0.3с
Δαρθ
но это конечно скорее всего потому, что файлы на диск записались несколькими транзакциями и компактно, тк создавал их без синка после каждого тупо башем в цикле
Δαρθ
если они создавались в разное время и долго -- то скорее всего метадату распионерило рандомно по всему диску изза чего и тормоза
George
но это конечно скорее всего потому, что файлы на диск записались несколькими транзакциями и компактно, тк создавал их без синка после каждого тупо башем в цикле
ага, это тоже одна из составляющих.
Как ни смешно, работа с метой в zfs бывает быстрее даже, в частности т.к. он сжимает её через lz4
Nikita
Коллеги, подскажите оптимальное число дисков для массива raidz? есть 12 дисков. нужно сделать массив для хранения резервных копий snapshot-ов с других серверов. насколько я помню, обычно формула была примерно 2n+p, где n-целое, больше 1, а p - число дисков для parity, т.е. на моих 12-ти можно, к примеру, сделать raidz2 или raidz3+1 диск spare. З.Ы. сервер будет работать не круглосуточно, а включаться только для приёма снимков.
George
Коллеги, подскажите оптимальное число дисков для массива raidz? есть 12 дисков. нужно сделать массив для хранения резервных копий snapshot-ов с других серверов. насколько я помню, обычно формула была примерно 2n+p, где n-целое, больше 1, а p - число дисков для parity, т.е. на моих 12-ти можно, к примеру, сделать raidz2 или raidz3+1 диск spare. З.Ы. сервер будет работать не круглосуточно, а включаться только для приёма снимков.
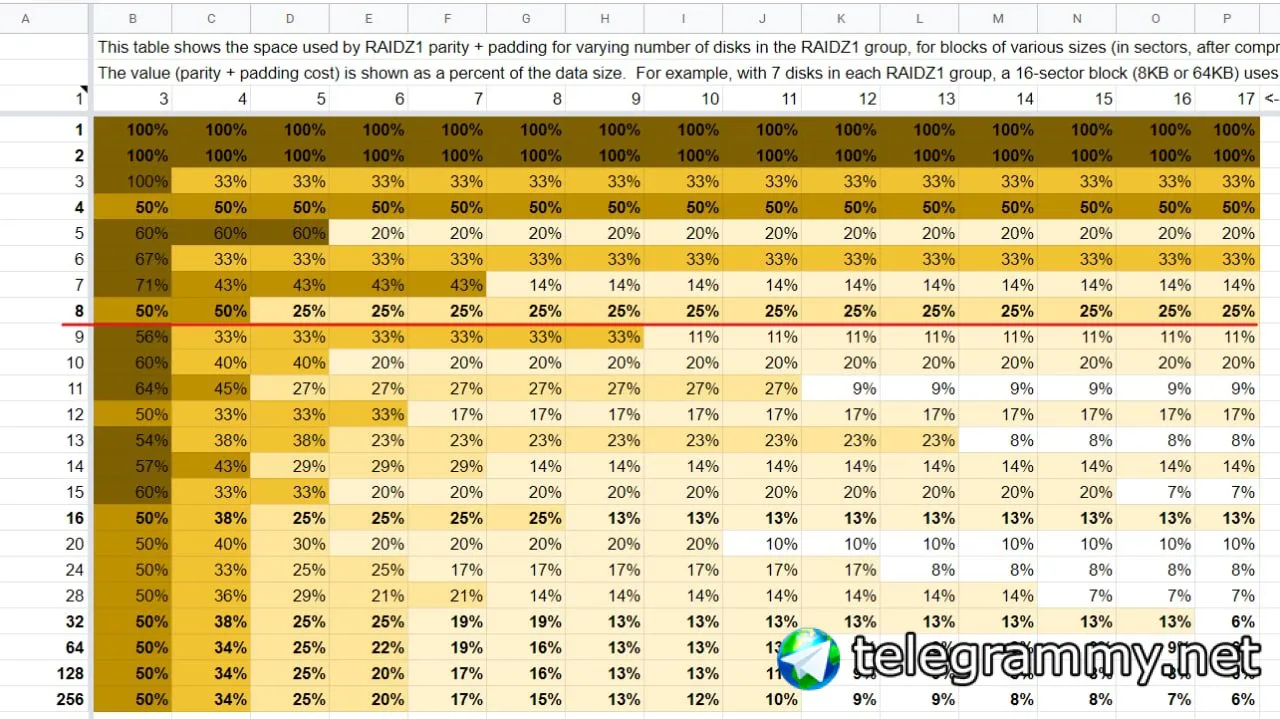
формулы по количеству дисков нет, но для вычисления полезного объёма относительно используемого размера блока стоит использовать эту таблицу https://docs.google.com/spreadsheets/d/1tf4qx1aMJp8Lo_R6gpT689wTjHv6CGVElrPqTA0w_ZY/edit?pli=1#gid=2126998674
George
вопрос производительности стоит отдельно, 1 raidz vdev на запись будет иметь iops самого медленного диска в нём
Nikita
формулы по количеству дисков нет, но для вычисления полезного объёма относительно используемого размера блока стоит использовать эту таблицу https://docs.google.com/spreadsheets/d/1tf4qx1aMJp8Lo_R6gpT689wTjHv6CGVElrPqTA0w_ZY/edit?pli=1#gid=2126998674
правильно ли я понял, что для бэкапов, учитывая особенность нагрузки, целесообразно использовать максимальный размер блока для экономии места и повышения производительности?
Nikita
Или при приёме snapshot существенную роль играет random iops?
 Vladislav
Vladislav
Или при приёме snapshot существенную роль играет random iops?
Если они будут литься все одновременно с инкрементами, то возможно немного рандома и будет, но бэкап же последовательная запись всегда
 Evgenii
Evgenii
формулы по количеству дисков нет, но для вычисления полезного объёма относительно используемого размера блока стоит использовать эту таблицу https://docs.google.com/spreadsheets/d/1tf4qx1aMJp8Lo_R6gpT689wTjHv6CGVElrPqTA0w_ZY/edit?pli=1#gid=2126998674
А почему при блоке в 8кб, процент накладных расходов на избыточность и паддинг не зависят от количества дисков??
Evgenii
 George
George
А почему при блоке в 8кб, процент накладных расходов на избыточность и паддинг не зависят от количества дисков??
потому что на 2 сектора в любом случае придётся записать 3й, вот и 100% оверхед
George
правильно ли я понял, что для бэкапов, учитывая особенность нагрузки, целесообразно использовать максимальный размер блока для экономии места и повышения производительности?
в целом да, но зависит от метода бекапа и требований к случайному чтению при восстановлении
Nikita
в целом да, но зависит от метода бекапа и требований к случайному чтению при восстановлении
zfs snapshot, send/recv инкрементно. всё средствами zfs) скорость восстановления не сильно важна, можно и подождать.
Δαρθ
а правду говорят что у zfs луа в ядерном модуле?
Δαρθ
а что оно там делает? )
George
а что оно там делает? )
https://openzfs.github.io/openzfs-docs/man/8/zfs-program.8.html?highlight=channel
Δαρθ
 tspok
tspok
Я эту телегу полдня катал :с
tspok
В общем, установил ZFS на рут убунты 20.04 по официальному гайду, теперь не могу ни загрузить ядро от 18.04 несмотря на установленный zfs-dkms, ни обновить меню груба (файл обновляется, а меню всё равно старое). Халп. Старое ядро загрузить нужно, обновить меню груба - не очень.
Ivan
В общем, установил ZFS на рут убунты 20.04 по официальному гайду, теперь не могу ни загрузить ядро от 18.04 несмотря на установленный zfs-dkms, ни обновить меню груба (файл обновляется, а меню всё равно старое). Халп. Старое ядро загрузить нужно, обновить меню груба - не очень.
наверно модуль ядра не собрался
Ivan
сделай dpkg-reconfigure нужного ядра и обнови initramfs на всякий
tspok
Наличие файликов я не проверил, но отрепортил что всё хорошо. А вот проверить initramfs я забыл, надо перепроверить.
tspok
Взлетело, спасибо!
Δαρθ
кстати а без инитрамфс с рут-зфс загрузиться совсем никак? даже если зфс вкомпилена в ядро, а не модулем?
Nick
George
а аналогичную табличку про draid еще не сделали?
Емнип она же действительна, он на raidz основан
 Art
Art
https://www.qnap.com/en-us/product/ts-h2490fu
 central
central
Эпик на один только zfs не многовато?
Art
Эпик на один только zfs не многовато?
Тож про это подумал, но тут я смотрю эпики по 3Гц - высокочастотность хороша для дедупа. Может, выбор этим определён
Vladislav
Эпик на один только zfs не многовато?
Не то, чтобы был богат выбор. Нужно много оперативной памяти + pcie 4.0 + много линий pcie для NVMe
Вика has been banned! Reason: CAS ban.
Vladislav
Не то, чтобы был богат выбор. Нужно много оперативной памяти + pcie 4.0 + много линий pcie для NVMe
А Threadripper стоит дороже и линий PCIe меньше
Evgenii
 Evgenii
Evgenii
Возможно собирают зеркало из локальных и удаленных дисков? Или у них свой форк ZFS с каким то слоем в user space?
Evgenii
Ограничения я понимаю.. у них там сетевухи по 40 и 100 гбит внутри стоят.. Мне интересно как это с точки зрения ZFS может выглядеть @gmelikov
 LordMerlin
LordMerlin
Мож каждую секунду zfs-send?
 Vladislav
Evgenii
Vladislav
Evgenii
Мож каждую секунду zfs-send?
тогда у них будет либо latency = 1 секунда в полке за миллион, либо асинхронные реплики с потерей данных, а не реалтайм
Evgenii
там скорее всего идет синхронизация снимками, как в sanoid
Если только они успевают слать 100 раз в секунду... и делать 100 снимков в секунду. И все равно будет медленно