 Олег
Олег


Ну вариантов тьма
Вышел диск из строя на его место 2tb, затем после синка выводишь из пула оставшийся 1тб и добавляешь оставшийся 1тб. Пусть поправят меня, но после второго синка место сразу увидится большего обьема
Олег
Даже при выводе последнего 1tb по идее должно увидется больше
 George
George
Ну вариантов тьма
Вышел диск из строя на его место 2tb, затем после синка выводишь из пула оставшийся 1тб и добавляешь оставшийся 1тб. Пусть поправят меня, но после второго синка место сразу увидится большего обьема
лучше сначала добавить новый в миррор и только после ресильвера старый выводить
Anonymous
лучше сначала добавить новый в миррор и только после ресильвера старый выводить
Новый не добавится.
Диск большего объема
Олег
О том и речь, схему же такую расписал
Олег
Меньший не добавится, большего кушаются на ура
Anonymous
Хотя стоп, зеркала уже нет.
Убрал диск (
Anonymous
Вижу сейчас решение Олега.
Реплейс на новый диск
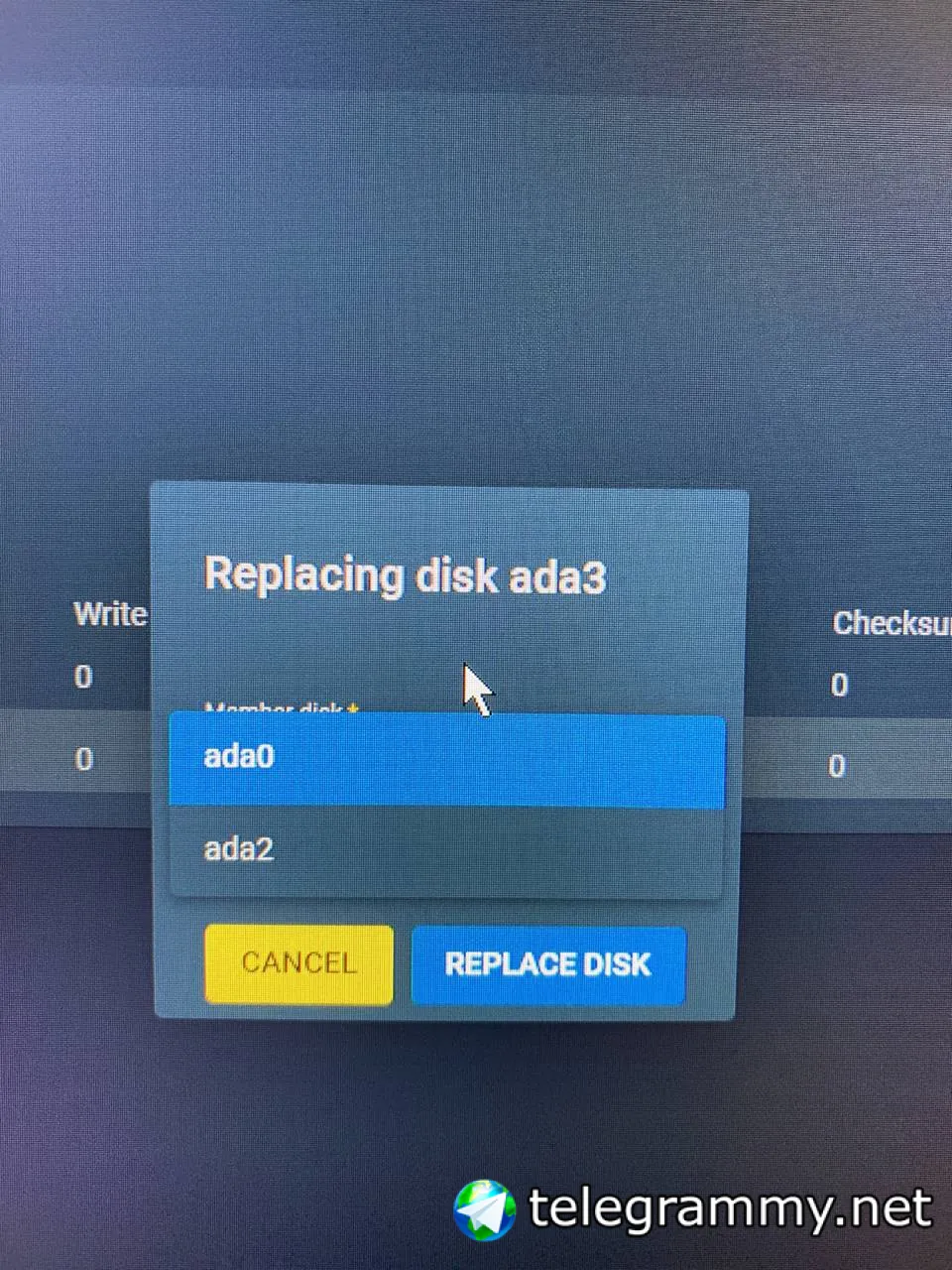 George
George
Лучше не реплейс а аттач
George
Чтобы миррор получился
George
Безопаснее
Anonymous
Лучше не реплейс а аттач
В общем получилось как выше задумал.
Аттачнул диск в миррор, процесс пошёл )
Спасибо
 Vladimir
Vladimir
ZFS на nvme устройствах имеет смысл поднимать, если скорость интересует?
Есть железяка с 6 NVMe дисками, сейчас работает в режиме RAID-5, отформатирована под ext4 , имеет смысл её на zfs переводить?
 central
central
ZFS на nvme устройствах имеет смысл поднимать, если скорость интересует?
Есть железяка с 6 NVMe дисками, сейчас работает в режиме RAID-5, отформатирована под ext4 , имеет смысл её на zfs переводить?
ЕМНИП полностью загрузить nvme на zfs так и не смогли
 inqfen
inqfen
ZFS на nvme устройствах имеет смысл поднимать, если скорость интересует?
Есть железяка с 6 NVMe дисками, сейчас работает в режиме RAID-5, отформатирована под ext4 , имеет смысл её на zfs переводить?
Имеет если нужны плюшки зфс типа снапшотов или сжатия
inqfen
А так, по скорости прироста точно не выйдет, на nvme ее и так хватает
Vladimir
а падения не будет?
Vladimir
С чего бы при прочих равных?
ну , по тестам Phoronix на nvme , ext4 заметно быстрее ZFS бывает, а xfs ещё быстрее
central
nikolay
Если у меня 2 HDD 1.8T для бэкапов в основном, мне достаточно log девайса для пула или сделать и l2arc?
Лог для бэкапа не нужен, можно и sync=disable сделать
nikolay
Насчёт l2arc не знаю, можете попробовать
ValkraS
Лог для бэкапа не нужен, можно и sync=disable сделать
для тестов, под пару ВМок думаю не помешает )
Andrey
Коллеги, здравствуйте. Собираю на ZOL такую штуку: ISCSI target для esxi6 (VMFS 5). Будет жить порядка 50VM с разной интенсивностью IO, но в основном это мелкие провайдерские сервисы с невысокой нагрузкой (dns, dhcp, web, radius и тому подободная фигня).
Andrey
Появились вопросы, как организовать pool
Andrey
понятно что это будет raid10 (для оптимизации io и надежности)
Andrey
но вот какие volsize, blocksize прописать ума не приложу...
Andrey
12xHDD по 4Тб, 512e
Andrey
просто официально VMFS5 использует блоки по 1Мбайту, но "народ" говорит, что по факту оперирует блоками по 16Кбайт... Думал может быть у кого-то есть "практика" в этом применении
nikolay
просто официально VMFS5 использует блоки по 1Мбайту, но "народ" говорит, что по факту оперирует блоками по 16Кбайт... Думал может быть у кого-то есть "практика" в этом применении
vmware пробрасывает блок от гостевой ос на сторадж as is, макс размер блока который может быть сброшен без сплита на уровне гипервизора - 32 мб вроде
Andrey
т.е. смотрю какие размера блоков на VMах (надеюсь они примерно одинаковые) и под этот размер подстраиваю блок в zvol?
nikolay
под средний размер блока можно подогнать, верно
Andrey
VMFS5 only offers only one block size:
1 MB block size – maximum file size: 64 TB.
вероятно выше речь шла об sub block которые могут быть до 64Кбайт... Т.е. все таки я думаю гипервизор "собирает" блоки на запись/чтение в VMFS, а потом их пачкой передает на схд (как раз блоками по 1Мб). Но что-то нигде не могу найти инфу об этом.
Anatoly
Я бы тестовый стенд собрал и посмотрел по метрикам
Andrey
нашел "Например, предположим, что настроена VMFS5, что означает размер блока (файла) 1 МБ, сопровождаемого субблоками 8 КБ. Теперь, когда системе необходимо сохранить файл размером 64 КБ, что намного меньше размера блока (файла) по умолчанию, она НЕ БУДЕТ сохранять файл, используя 8 субблоков по 8 КБ, нет, она просто сохранит файл в нормальный блок размером 1 МБ (файл). Только если размер файла на самом деле составляет 8 КБ или меньше, для его хранения будет использоваться субблок"
Andrey
легче не стало)
Anatoly
 Andrey
Andrey
о прикольно)
Andrey
и еще вопрос, когда организую ZIL и L2ARC на SSD, zfs надо как-то говорит что размер блока на SSD будет 8k, или она сама умеет определять это?
Anatoly
 Anatoly
Anatoly
 Anatoly
Anatoly
>zfs надо как-то говорит что размер блока на SSD будет 8k
помоему надо говорить через ashift
Andrey
>zfs надо как-то говорит что размер блока на SSD будет 8k
помоему надо говорить через ashift
для pool понятно, но тут то кеши... умеют ли они с ashift работать
Andrey
и еще не понятный момент, если делать zvol для iscsi есть ли смысл оставлять 20% резерва от емкости pool
Andrey
просто странно что в сети нет никакой вменяемой инфы по применению zfs+iscsi+esxi. Все на уровне теорий и рассуждений... неужто в продакшин никто не юзает
Anatoly
так как slog и l2arc добавляется уже в созданный пул если там blocksize какую-то роль и играет, то будет использоватся тот, что у пула, как кажется
iscsi+esxi - это технологии древних, сейчас все в контейнерах:) а сторадж или в БД/s3 или через ceph какой-нибудь
nikolay
VMFS5 only offers only one block size:
1 MB block size – maximum file size: 64 TB.
вероятно выше речь шла об sub block которые могут быть до 64Кбайт... Т.е. все таки я думаю гипервизор "собирает" блоки на запись/чтение в VMFS, а потом их пачкой передает на схд (как раз блоками по 1Мб). Но что-то нигде не могу найти инфу об этом.
вы можете думать как хотите, я написал вам как есть, с версии 6.0 такое поведение у io sched которое я описал
nikolay
и еще вопрос, когда организую ZIL и L2ARC на SSD, zfs надо как-то говорит что размер блока на SSD будет 8k, или она сама умеет определять это?
размеры блоков для slog и l2arc никак не настраиваются. и не нужно с этим заморачиваться
nikolay
нашел "Например, предположим, что настроена VMFS5, что означает размер блока (файла) 1 МБ, сопровождаемого субблоками 8 КБ. Теперь, когда системе необходимо сохранить файл размером 64 КБ, что намного меньше размера блока (файла) по умолчанию, она НЕ БУДЕТ сохранять файл, используя 8 субблоков по 8 КБ, нет, она просто сохранит файл в нормальный блок размером 1 МБ (файл). Только если размер файла на самом деле составляет 8 КБ или меньше, для его хранения будет использоваться субблок"
не надо лезть в эту тему с субблоками, она к вашему вопросу никакого отношения не имеет
Andrey
да, сэр!)
George
и еще вопрос, когда организую ZIL и L2ARC на SSD, zfs надо как-то говорит что размер блока на SSD будет 8k, или она сама умеет определять это?
лучше сказать явно, емнип оно умеет
Andrey
>iscsi+esxi - это технологии древних
в связи технологии очень консервативны)
nikolay
и еще не понятный момент, если делать zvol для iscsi есть ли смысл оставлять 20% резерва от емкости pool
зависит от вашей нагрузки, 20% места на пуле это рекомендации а не требование
central
зависит от вашей нагрузки, 20% места на пуле это рекомендации а не требование
для CoW это все таки больше требование
nikolay
лучше сказать явно, емнип оно умеет
? можно задать размер блока при создании slog или l2arc? или я что то не так понял
nikolay
если у вас 1000 условных iops с пула даже в raidz, диски справляются с нагрузкой и в основном чтение - какая разница 20% будет свободно на пуле или 10?
Andrey
тем более если еще и ZIL будет большой
riv
У соляриса вроде нфс без кеширования. Хотя не уверен. Не хочу искази) он не особо удобен
Nfs для файлов, а для блочных устройств жругие протоколы. К тому же, в проксмокс есть zvol over iscsi с поддержкой снепшотов из каробки. Но я не пробовал.
 Василий
Василий
Nfs для файлов, а для блочных устройств жругие протоколы. К тому же, в проксмокс есть zvol over iscsi с поддержкой снепшотов из каробки. Но я не пробовал.
гдето находил сравения, что нфс с есх работает чуть ли не быстрее чем с isci, а учитывая, что все равно, все тормоза сидят в зфс, а нфс удобнее, пользую нфс
nikolay
гдето находил сравения, что нфс с есх работает чуть ли не быстрее чем с isci, а учитывая, что все равно, все тормоза сидят в зфс, а нфс удобнее, пользую нфс
я сравнивал на 10 Gbe на нетапах перформанс внутри гостевых ос на датасторе выданной по iscsi и по nfs - на nfs показатели по iops выше, а latency ниже или сравнимое..
Василий
 Владимир
Владимир
Владимир
Владимир
колличество иопс зависит на прямую от латенси)
Владимир
и иопс может быть ббольше при более низком латенси только если число потоков увеличить
Ivan
и иопс может быть ббольше при более низком латенси только если число потоков увеличить
низкое латенси это ж хорошо )
Владимир
блин)
Владимир
низкое в смысле меньше мс, а не в смысле хуже?)
Владимир
богатый русский язык блин)
Василий
низкое в смысле меньше мс, а не в смысле хуже?)
низкое летисы в смысле плохо еще ни разу не слышал)