Ещё как вариант пошерстить командную строку qemu, это если надо в виртуалку передавать. Может быть там есть настройка?
у меня нет виртуалок )
 Dmitry
Dmitry

 Dmitry
Dmitry
точнее есть, но они тут совсем далеко )
Dmitry
riv
остаётся losetup, zfs так не может, хотя в багтрекере такие вопросы поднимались.
riv
прям то что надо! огромное спасибо! с меня стакан красного!
Рад был помочь. Никогда не задумывался о важности этого параметра для таблицы разметки. А вонанокак, оказывается.
Dmitry
Рад был помочь. Никогда не задумывался о важности этого параметра для таблицы разметки. А вонанокак, оказывается.
еще раз спасибо. Ну тут можно просто вспомнить про жесткие диски 512 и 4к. Суть та же. Если система не понимает диски 4к, она не увидит данные
riv
насколько я понимаю, на файловую систему это не повлияло. Скорее всего это так. А значит подобных проблем, вероятно, можно избежать, если форматировать в файловую систему не раздел, а всё устройство целиком.
Еще интересный момент. А что если "на шару" запустить gparted /dev/zvol/сломанный_zvol не сообразит ли он что таблицу разметки нужно пересчитать. Во всяком случае он предлагает что-то "исправить" в таких случаях. Возникает вопрос насколько корректно он это сделает?
Я вечерком попробую сэмулировать ситуацию.
Dmitry
но результат эксперимента крайне интересен
riv
xfs не монтируется с сообщением
mount: /mnt/test: mount(2) system call failed: Function not implemented.
Dmitry
xfs не монтируется с сообщением
mount: /mnt/test: mount(2) system call failed: Function not implemented.
у меня смонтировался как раз xfs
riv
я имел в виду, если создать её на 512b а монтироват при logical blocksize 4096
Dmitry
riv
а ext4 монтируется и так и так
riv
root@htz-vm01 /var/lib/vz/template/iso # losetup loop1 /dev/zvol/zfs-ssd-big/test -b 512
root@htz-vm01 /var/lib/vz/template/iso # mkfs.ext4 /dev/loop1
mke2fs 1.44.5 (15-Dec-2018)
/dev/loop1 contains a xfs file system
Proceed anyway? (y,N) y
Creating filesystem with 262144 4k blocks and 65536 inodes
Filesystem UUID: 657e8dd6-fa50-4a74-8b4d-f3549cbf1366
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
root@htz-vm01 /var/lib/vz/template/iso # losetup -d /dev/loop1
root@htz-vm01 /var/lib/vz/template/iso # losetup loop1 /dev/zvol/zfs-ssd-big/test -b 4096
root@htz-vm01 /var/lib/vz/template/iso # mount /dev/loop1 /mnt/test/
root@htz-vm01 /var/lib/vz/template/iso # mount | grep loop1
/dev/loop1 on /mnt/test type ext4 (rw,relatime)
root@htz-vm01 /var/lib/vz/template/iso # umount /mnt/test
root@htz-vm01 /var/lib/vz/template/iso # losetup -d /dev/loop1
root@htz-vm01 /var/lib/vz/template/iso # losetup loop1 /dev/zvol/zfs-ssd-big/test -b 512
root@htz-vm01 /var/lib/vz/template/iso # mount /dev/loop1 /mnt/test/
root@htz-vm01 /var/lib/vz/template/iso # mount | grep loop1
/dev/loop1 on /mnt/test type ext4 (rw,relatime)
riv
а ведь еще глюки всякие могут быть. Да тут не паханное поле, похоже...
Dmitry
ну да
 Алексей
Алексей
Всем привет. Может кто нибудь подсказать, как полностью перенести сервер на фряхе zfs с клетками на новый сервак? На ufs все проще с дампом , а вот на zfs пока не понял как
 LordMerlin
LordMerlin
снапшот кинуть
 Владимир
Владимир
рсинх тупее), там же ZFS)
 central
central
Всем привет. Может кто нибудь подсказать, как полностью перенести сервер на фряхе zfs с клетками на новый сервак? На ufs все проще с дампом , а вот на zfs пока не понял как
Разве нельзя сделать что то типо zfs send >> dump.bin
 Ilya
Ilya
Всем привет. Может кто нибудь подсказать, как полностью перенести сервер на фряхе zfs с клетками на новый сервак? На ufs все проще с дампом , а вот на zfs пока не понял как
на новом сервере создать разметку, создать пул, затем со старого сервера через zfs send|zfs recv скопировать все датасеты по ssh
riv
rsync-ом zfs? Сжечь еретика!
Владимир
)))
Владимир
ну как топором хлеб резать))
Ilya
Можно в качестве vdev использовать партицию.
Ilya
L2ARC - это кеш чтения. Уверен, что у тебя сейчас не хватает памяти под кэш? И уверен, что хватит на то, чтобы добавить L2ARC?
Ilya
так, может, под ARC в памяти больше места разрешить?
Владимир
это же хорошо, у ZFS как раз рекомендуют не забивать полностью
Ilya
когда у тебя много чтения одних и тех же данных, так что их неплохо бы все сунуть в кэш, но самой RAM не хватает под это всё, тогда, пожертвовав часть RAM под индексы L2ARC, можно часть кэша отодвинуть на диск
Владимир
ааа))
Ilya
да сможешь, конечно. В качестве vdev можно как целиком диск указать, так и партицию.
Ilya
в man zpool все детали
 nAHKPATOB
nAHKPATOB
могу предложить обновиться
Обновил систему до:
-13.0-RELEASE;
-ZPOOL тоже обновил, он добавил немного новых функций;
-ZFS сказал что обновлений нет, итак уже всё обновлено.
по итогу теперь zfs-2.0, zpool status также ошибок не выдаёт, zfs так и не нашёл потерю :(
Буду создавать новый датасет и мигрировать туда, а этот как-нибудь буду пилить, интересно же почему так вышло.
 Dmitry
Dmitry
Парни, вы бесстрашные обновляться на X.0. Я бы подождал минимум 13.1 или 13.2, когда все баги выловят
 #Root
#Root
Не все ещё выловили за 5 RC?
Dmitry
Практика подсказывает, что в версиях X.0 бывают сюрпризы, лучше их в прод не ставить
Роман
Добрый день, коллеги. Вопрос от ламера. ZFS никогда не использовал, но вот в новой конторе один из жестких дисков совсем отвалился (его даже биос не видит). RAID 6.
zpool import -d /dev/mapper -N <POOL NAME>
cannot import '<POOL NAME>': one or more devices is currently unavailable
В итоге zpool status - no pools availible.
Может кто подсказать, что дальше делать? И не может быть такого, что накрылся диск с метаданными и теперь не восстановишь?
Ilya
Ты шаблон вставил вместо реального имени пула.
Кроме того, если в RAID6 отвалился 1 диск, то массив продолжает работать. Даже с 2 продолжит работать.
Вот только какая связь zpool и рейдом? У тебя точно не LVM/md'ом массив собран?
Роман
Роман
Это не шаблон, я просто переименовал
Роман
POOL NAME у меня просто pool - это уже имя
Ilya
`cannot import '<POOL NAME>': one or more devices is currently unavailable`
вот этот вывод ты скопипастил, или скрыл от чата имя пула, чтобы тебя не похэкали?)
Ivan
а как в zfs рейд 6 сделать ?
Роман
это просто типа скрыл
Роман
Дополнительная инфа (делалось еще до меня , потому ). Команды делались все по умолчанию
Роман
zpool create -m /mnt/⟨массив⟩ -o ashift=12 ⟨массив⟩ /dev/mapper/⟨диск1⟩ … /dev/mapper/⟨дискn⟩
Комманда создаст новый массив ZFS под названием ⟨массив⟩ используя диски с ⟨диск1⟩ по ⟨дискn⟩ (на месте « … » идёт перечисление дисков). После выполнения, массив будет автоматически импортирован, смонтирован и готов к работе.
Роман
RAID-Z там. Я так понял он ближе к raid -5. Raid-z2 уже к raid-6
Ilya
без одного диска пул всё равно не должен был никуда пропасть.
диски в /dev/mapper недоступны вообще все, что ли?
lsblk что показывает?
Роман
sda 8:0 1 2,7T 0 disk
├─sda1 8:1 1 1M 0 part
├─sda2 8:2 1 2,7T 0 part /
└─sda3 8:3 1 16G 0 part
└─cryptswap1 252:0 0 16G 0 crypt
sdb 8:16 1 2,7T 0 disk
└─zfs14 252:14 0 2,7T 0 crypt
sdc 8:32 1 2,7T 0 disk
└─zfs12 252:12 0 2,7T 0 crypt
sdd 8:48 1 2,7T 0 disk
sde 8:64 1 2,7T 0 disk
sdf 8:80 1 2,7T 0 disk
sdg 8:96 1 2,7T 0 disk
sdh 8:112 1 3,7T 0 disk
sdi 8:128 1 2,7T 0 disk
└─zfs13 252:13 0 2,7T 0 crypt
sdj 8:144 1 2,7T 0 disk
sdk 8:160 1 3,7T 0 disk
sdl 8:176 1 2,7T 0 disk
sdm 8:192 1 2,7T 0 disk
└─zfs11 252:11 0 2,7T 0 crypt
sdn 8:208 1 2,7T 0 disk
loop0 7:0 0 100G 0 loop
└─seafile_crypt 252:1 0 100G 0 crypt /opt/seafiles
Ilya
ну вот, кажется, что надо device mapper'ом как-то те crypt девайсы (инициализировать|расшифровать), и потом уже импортировать пул, когда в /dev/mapper они появятся.
На этом мои знания всё
Роман
Спасибо
Alexander
Добрый день,
Alexander
Пожалуйста, подскажите, как так получается, что load overage больше количества процов во время zpool scrub, но при этом загрузка проца в целом меньше 30%?
central
Пожалуйста, подскажите, как так получается, что load overage больше количества процов во время zpool scrub, но при этом загрузка проца в целом меньше 30%?
не вижу связи - покажите конкретные цифры
Alexander
11:33:51 up 7:20, 7 users, load average: 4.69, 4.99, 4.77
central
и что смущает?
Alexander
dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
3 8 79 10 0 0| 11M 333k| 0 0 | 0 0 |1341 3177
3 6 91 0 0 0| 23M 0 | 0 118B| 0 0 |1497 3463
3 8 87 2 0 0| 23M 536k| 366B 418B| 0 0 |1824 4255
1 4 93 2 0 0| 14M 316k| 160B 184B| 0 0 |1161 2555
2 4 94 0 0 0| 12M 0 | 94B 184B| 0 0 |1254 2593
5 10 80 5 0 1| 19M 1284k| 206B 66B| 0 0 |2509 5412
7 11 79 2 0 1| 30M 232k| 94B 184B| 0 0 |2393 5968
Alexander
Idle около 80%
central
https://habr.com/ru/post/260335/
 Vladimir
Vladimir
Господа, а посоветуйте какое-нибудь сравнение надёжности zfs с lvm+{xfs,ext4} для большого дискохранилища , например на 300-500T ?
Владимир
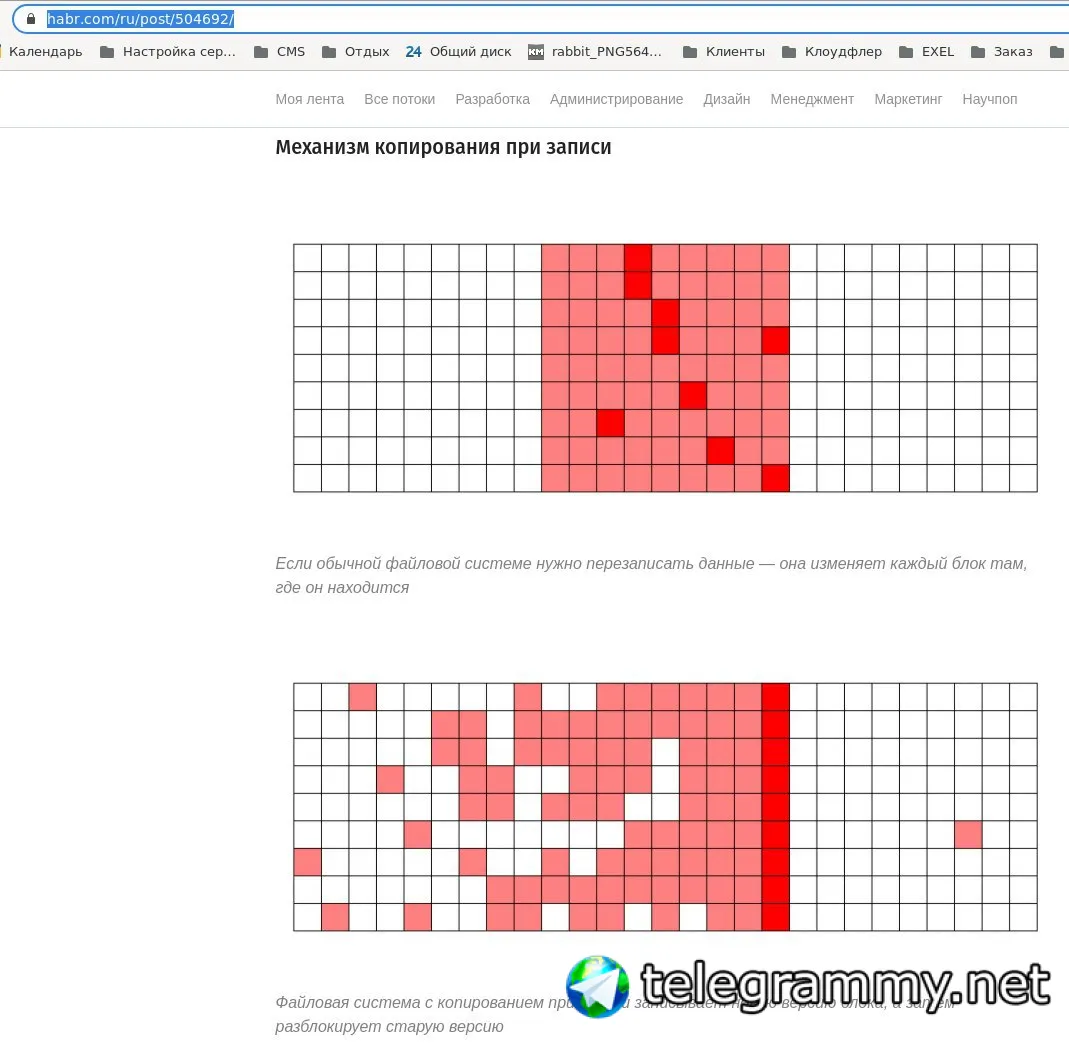
почитай что такое файловые системы копи ту врайт
Владимир
и тебе не прийдётся ничего сравнивать
Владимир
Господа, а посоветуйте какое-нибудь сравнение надёжности zfs с lvm+{xfs,ext4} для большого дискохранилища , например на 300-500T ?
https://habr.com/ru/post/504692/
Vladimir
что-то типа такого уже прочитал, теперь интересно сравнение как оно по надёжности и простоты восстанавливления после сбоя железа. По сравнению с классическим lvm+mdadm и т.д
Владимир
 Владимир
Владимир
начни с этого пункта
Владимир
вдумчиво
central
что-то типа такого уже прочитал, теперь интересно сравнение как оно по надёжности и простоты восстанавливления после сбоя железа. По сравнению с классическим lvm+mdadm и т.д
zfs в теории должна в любой момент времени оставаться консинстентной
Vladimir
скажем так, у меня есть одна система на ZFS, успешно крутится уже полтора года нагрузка низкая, сейчас появилась задача сделать ещё одну, уже под высокую нагрузку. И есть знакомые ( работающие в Redhat) которые отговаривают , типа они пробовали, при сбое все поломалось, починить не смогли, с тех пор zfs ни ногой, только mdadm + lvm
 Сергей
Сергей
скажем так, у меня есть одна система на ZFS, успешно крутится уже полтора года нагрузка низкая, сейчас появилась задача сделать ещё одну, уже под высокую нагрузку. И есть знакомые ( работающие в Redhat) которые отговаривают , типа они пробовали, при сбое все поломалось, починить не смогли, с тех пор zfs ни ногой, только mdadm + lvm
такие примеры могут рассматриваться?
https://zstor.de/en/petabyte-storage-e.html
Сергей
решения qnap на ZFS:
https://www.qnap.com/solution/qnap-zfs/en/
Сергей
https://openzfs.org/wiki/Companies
Vladimir
интереснее всего была бы статистика
Владимир
скажем так, у меня есть одна система на ZFS, успешно крутится уже полтора года нагрузка низкая, сейчас появилась задача сделать ещё одну, уже под высокую нагрузку. И есть знакомые ( работающие в Redhat) которые отговаривают , типа они пробовали, при сбое все поломалось, починить не смогли, с тех пор zfs ни ногой, только mdadm + lvm
А можно узнать что за сбой был и что именно сломалось?
Vladimir