 Maksym
Maksym


ну может 5К будет
 Nick
Nick
разбирайтесь с AF, один вызов в день вам ничего не сломает
 yopp
yopp
тогда AF и не парьтесь
Maksym
спасибо
 Alexey
Alexey
Привет, народ.
а вот интересно, при выборе ключа шардирования влияет ли на что-нибудь порядок сортировки индекса?
yopp
ключ шардирования это индекс, так что влиять будет так-же как это влияет на индекс
yopp
там что-то было с порядком связанное. помоему нельзя мешать порядки или что-то такое
yopp
A shard key index can be an ascending index on the shard key, a compound index that start with the shard key and specify ascending order for the shard key, or a hashed index.
Edouard
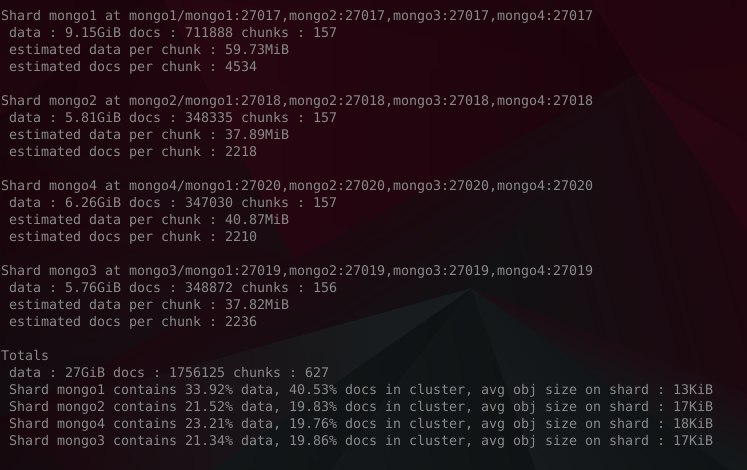
Привет, чат. Смущает колво документов при одинаковом количестве чанков на шард.
Edouard
 yopp
yopp
yopp
yopp
ни за размером чанков ни за количеством документов он не следит
yopp
в смысле не использует для балансировки
yopp
но у вас похоже не очень равномерный ключ
Edouard
Благодарю. Да, очень похоже.
 pplcf
pplcf
Может в сумму доков входят не шардед коллекции?
Edouard
Может. Но в запросе именно getShardDistribution.
Nick
Может в сумму доков входят не шардед коллекции?
не может, getShardDistribution показывает инфу по одной коллекции, а она либо шардед либо нет
 Aleksandr
Aleksandr
Добрый день. В монге новичек. Поднята на докерах репликация базы, в нее залита база из дампа примерно 4,5 гига. Докеры оперативы занимают 14 гигов это нормально? Докеры подняты пока на одной виртуалке для теста
 Aleksandr
Aleksandr
Добрый день. В монге новичек, так получилось что есть коллекция примерно 70Гб, нужно удалить половину записей, поле по которому нужно удалять не добавлено в индекс, что можно сделать? Спасибо.
Nick
удалять
Nick
никакой магии нет, в любом случае полный скан коллекции
Aleksandr
очень медленно, плюс в коллекцию пишется нонстопом
Nick
пока будете строить индекс тоже будет медленно
Nick
а потом удалять половину это тоже медленно
Aleksandr
где то видел вариант с переименованием коллекции и созданием новой, в которую переносятся только нужные записи, так не получится быстрее?
Nick
если бы вам надо было удалить пару тыщ доков по ключу, тогда имеет смысл сначала построить индекс, либо если эта опреация повторится в будущем. но когда надо удалить половину - дешевле удалять напрямую через скан, тем более что скорее всего планирвощик монги так же выберет вариант с сканом коллекции
Nick
запустите удаление во время минимальной активности системы, ночью например. а утром убейте запрос удаления. на следующий день так же, если вам прям сильно эффектит производительность системы удаление
Aleksandr
спасибо, буду пробовать
yopp
Добрый день. В монге новичек, так получилось что есть коллекция примерно 70Гб, нужно удалить половину записей, поле по которому нужно удалять не добавлено в индекс, что можно сделать? Спасибо.
открыть курсор без условий, проверять условие на клиенте и удалять документы по одному, ограничивая скорость выполнения скрипта
yopp
если пишутся документы которые надо потом удалять, то сначала сделать так, чтоб они не писались больше
 AstraSerg
AstraSerg
Добрый день. В монге новичек. Поднята на докерах репликация базы, в нее залита база из дампа примерно 4,5 гига. Докеры оперативы занимают 14 гигов это нормально? Докеры подняты пока на одной виртуалке для теста
Добрый. Это нормально. В памяти хранятся индексы и кеши.
rdcm
всем привет, сейчас пишу нагрузочные тесты для приложения с mongodb (net core)
С# mongo driver - 2.5.0
mongodb - 4.0.4 (single instance / mongodb atlas repl set)
под нагрузкой часть http запросов падает по таймауту монги (crud на БД)
эксепшон:
https://pastebin.com/g5gHf61U
кофигурация инстанса не имеет значения, реплика сет или сингл инстанс
в общем после пары дней изучения проблемы уперся в
MongoDB.Driver.MongoWaitQueueFullException: The wait queue for acquiring a connection to server host:port is full.
Кто-нибудь решал подобный кейс? На сколько тут поможет подбор значения maxPoolSize ?
*речь про C# / net core
 Viktor
Viktor
в общем после пары дней изучения проблемы уперся в
MongoDB.Driver.MongoWaitQueueFullException: The wait queue for acquiring a connection to server host:port is full.
Кто-нибудь решал подобный кейс? На сколько тут поможет подбор значения maxPoolSize ?
*речь про C# / net core
его еще придется выставлять у сервера
Nick
в общем после пары дней изучения проблемы уперся в
MongoDB.Driver.MongoWaitQueueFullException: The wait queue for acquiring a connection to server host:port is full.
Кто-нибудь решал подобный кейс? На сколько тут поможет подбор значения maxPoolSize ?
*речь про C# / net core
в С# хз есть аткое или нет, но жавском драйвере есть такое понятие как waitQueueMultiple, типа мольтипликтор стандартного размера очереди. в свое вреям тоже в очередь запросов упирался
 Oleg
Oleg
Oleg
Oleg
точнее не мультипликатор, а просто ручное выставление MaxConnectionPoolSize and WaitQueueSize
Oleg
но смыслу то же самое
Nick
просто меня сам механизм смущает что оно через мультипликатор задается, а не фиксировано, поэтому и не был уверен что такое же может быть
rdcm
спасибо, сейчас гляну! не видел раньше такой ручки, пул коннекшенов, это вроде другая ручка отвечающая только за кхм пул коннектов у MongoClient
Oleg
Oleg
собственно это основная ручка
Oleg
и из-за этого эксепшен и вылетает
rdcm
логично, а для него есть какая-нибудь усреднённая цифра?) или только методом проб и ошибок?
rdcm
дефолтная 100
Oleg
только эмпирически
Oleg
у каждого аппликейшена же своя нагрузка
Nick
логично, а для него есть какая-нибудь усреднённая цифра?) или только методом проб и ошибок?
а вы не для это разве нагрузочные настраиваете чтобы это как раз подобрать?
rdcm
так сходу не получилось, у меня тесты достаточно грубоватые, т.к. не специалист в нагрузочном тестировании
rdcm
пробовал разные значения, поведение сильно не менялось
Viktor
rdcm
изначально проблема была в том, что переезжая с виндовой тачки на линукс, один и тот же код работал по-разному
тут может быть много нюансов, но больше всего подозрений было на драйвер
хотел воспроизвести проблему
rdcm
через какое-то время все запросы отлетали по таймауту
Oleg
шарповый драйвер у монги ужасен
rdcm
в целом я как раз обратного мнения, но некоторые вещи можно было бы сделать более прозрачными
rdcm
совершенно точно более худшая клиентская либа это NEST для elasticsearch
Oleg
возможно, что так
я не говорил, что это истина и нет ничего хуже
но у монго драйвера меня раздражал крайне неудобный десериалиазатор
Oleg
я так и не смог добиться от него нужной гибкости, и пришлось писать бойлерплейт на маппинге
rdcm
а какого именно функционала не хватило?
rdcm
у меня о нём в целом только положительные впечатления
Oleg
у меня был кейс, что всё мапилось в реактивные обертки
условно поле в схеме с типом int становилось ReactiveProperty<int>
вот и развивая эту идею нам не хватало полного пути к десереализуемому полю, чтоб его апдейтить или хотя бы парента, чтоб построить весь путь
Oleg
именно на этапе десериализации
Oleg
чтоб прям в коде десереализатора зашивать этот путь
Oleg
там идея была, что в памяти держались реактивные модели изменяя которые, ты получаешь дифф, который применяешь в дб, когда закончил всю RPC успешно
Oleg
еще есть притензии к архитектуре, она размашистая, но при это негибкая, то есть много абстракций, которые по сути являются и имплементацией
ты либо десериализуешь как задумалось в драйвере, либо работаешь с BSON
других путей нет, кроме написания своего велосипеда
и по производительности драйвер спамит в память кучу строк, которые отъедают несправедливо много оперативки
Oleg
при этом это никак не отнимает, конечно, удобство самой монгодб; но не смотря весь крупный опыт в дотнете, я думаю, что на js я написал бы тот же объем функционала быстрее, удобнее и приятнее
rdcm
Короткий ответ такой, таскаете за собой специфичную реактивную либу - с сериализацией вам никто не поможет )
например noda time написанная джоном скитом, почти никем не поддерживается, хотя либа крутейшая
Viktor
у меня был кейс, что всё мапилось в реактивные обертки
условно поле в схеме с типом int становилось ReactiveProperty<int>
вот и развивая эту идею нам не хватало полного пути к десереализуемому полю, чтоб его апдейтить или хотя бы парента, чтоб построить весь путь
написание кастомного десериализатора решило бы проблему
Oleg
написание кастомного десериализатора решило бы проблему
это плохо стыкуется с драйвером, дальше об этом писалось :)
получился бы огромный велосипед, который пришлось бы хорошо документировать, чтоб люди могли работать
Oleg
Короткий ответ такой, таскаете за собой специфичную реактивную либу - с сериализацией вам никто не поможет )
например noda time написанная джоном скитом, почти никем не поддерживается, хотя либа крутейшая
да здесь дело даже не в реактивщине, а просто в самом неудобном апи
Viktor
Oleg
да
Viktor
я писал парочку сериализаторов на старой (1.х) и новой (2.+) версиях драйверов - легко пишется и вполне понятно
Oleg
просто наследование и определение ассоциаций было сделано
Oleg
написано же, чего нет в десериалиазаторе
Oleg
"вот и развивая эту идею нам не хватало полного пути к десереализуемому полю, чтоб его апдейтить или хотя бы парента, чтоб построить весь путь"
Oleg
нам нужна была эта информация внутри десериалиазатора
Viktor
а зачем?
Oleg
так там тоже написано