 Vadim
Vadim


404
 Nick
Nick
почему нет? если у вас тяжелая операция, на которую не хочется тратить серверное время и дешевле отдать данные и загрузить проц у пользователя, то почему бы и нет7
Nick
но это уже исключительно какие даныне у вас и насколько нежелательно их попадание в руки недоброжелательного пользователя
 Alexander
Alexander
почему нет? если у вас тяжелая операция, на которую не хочется тратить серверное время и дешевле отдать данные и загрузить проц у пользователя, то почему бы и нет7
а гонять тонны данных между фронтом и бэком?
Alexander
Oleg
почему нет? если у вас тяжелая операция, на которую не хочется тратить серверное время и дешевле отдать данные и загрузить проц у пользователя, то почему бы и нет7
и у пользователей со слабым железом будет грузить полчаса.
Nick
смотря какие задачи, может всеравно пользователю нужны все эти данные, но то накаждый чих сервис дергаьб а другое выдать ему данные и пусть он их ворочит как хочет не грузя сервак
Nick
я же в качестве предложения, нельзя всегда быть однобоким, иногда есть смысл чтото делать не так как принято
Nick
вот те же 10к строк - это же детские размеры данных по современным меркам и единственно гед будет актуально какието телодвижения - мобильный интернет
 Іван 🤙
Іван 🤙
Ребят, подскажите как лучше:
работать с датой монги Date()
или просто стрингой писать дату , которая будет генерится внутри проги (python) ?
я так понимаю, что если поле будет одинаково у нескольких документов, (выборка по дате), то впринципи без разницы(всм. делать так как удобней)
или есть разница(в скорости например)?
 yopp
yopp
дату лучше хранить как UTC datetime
yopp
ну хотите в монге, хотите в приложении. главное не в виде строки, а ввиде объекта который сериализуется в BSON тип UTC datetime.
 Val
Val
тут выше писали что $group $unwind крайне дорого, а что юзать если есть тонна данных с сенсоров и нужно получить выборку средних значений?
yopp
$avg отлично работает с массивами в $project/$addFields
yopp
$addFields: { avg: { $avg: "$arrayField" } }
Val
$project еще не юзал, а как в нем сгруппировать данные по значениям? еще и посчитать среднее по вложенным значениям без $unwind
Val
вообще насколько хорошая идея юзать монгу для timeseries данных? они вроде как сами форсят использование на эту тему, но где то видел весьма критичную статью
yopp
вы очень абстрактно описываете своб проблему
yopp
монгу для timeseries можно использовать, но для этого надо очень аккуратно проектировать документы, под чтение
Val
{
sensor: { type: SchemaTypes.ObjectId, ref: "Sensor", required: true },
timestampMinute: Date,
name: { type: String, required: true },
values: [{ date: Date, value: Number }]
}
 Serj
Serj
Ребят, подскажите как лучше:
работать с датой монги Date()
или просто стрингой писать дату , которая будет генерится внутри проги (python) ?
я так понимаю, что если поле будет одинаково у нескольких документов, (выборка по дате), то впринципи без разницы(всм. делать так как удобней)
или есть разница(в скорости например)?
Храни дату всегда в ISO формате. Для обработки используй moment.js
Val
сам aggregate длинный)
Val
$unwind values по ним считаю среднее для минуты, дальше группирую данные уже по нужным промежуткам и считаю среднее для него
 Bro
Bro
для питона datatime.utcnow()
Bro
дата
rdcm
всем привет, сейчас пишу нагрузочные тесты для приложения с mongodb (net core)
С# mongo driver - 2.5.0
mongodb - 4.0.4 (single instance / mongodb atlas repl set)
под нагрузкой часть http запросов падает по таймауту монги (crud на БД)
эксепшон:
https://pastebin.com/g5gHf61U
кофигурация инстанса не имеет значения, реплика сет или сингл инстанс
rdcm
Кто-нибудь сталкивался?
 Viktor
Viktor
Viktor
Viktor
Драйвер стоит обновить, кстати
Viktor
всем привет, сейчас пишу нагрузочные тесты для приложения с mongodb (net core)
С# mongo driver - 2.5.0
mongodb - 4.0.4 (single instance / mongodb atlas repl set)
под нагрузкой часть http запросов падает по таймауту монги (crud на БД)
эксепшон:
https://pastebin.com/g5gHf61U
кофигурация инстанса не имеет значения, реплика сет или сингл инстанс
Еще такой эксепшен вылетает, когда коннект до базы обрывается
rdcm
на счет пула не уверен, проблема была и в mongodb atlas, при 50 коннектах
на счет драйвера согласен, постепенно рефакторю легаси код
rdcm
Еще такой эксепшен вылетает, когда коннект до базы обрывается
знаю, но это только под нагрузкой такое поведение, базу данных приложенме видит
Viktor
Хм, а лимит подключений у монги выставлен?
rdcm
дефолтный коннекшн стринг
mongodb://host:27017/admin
rdcm
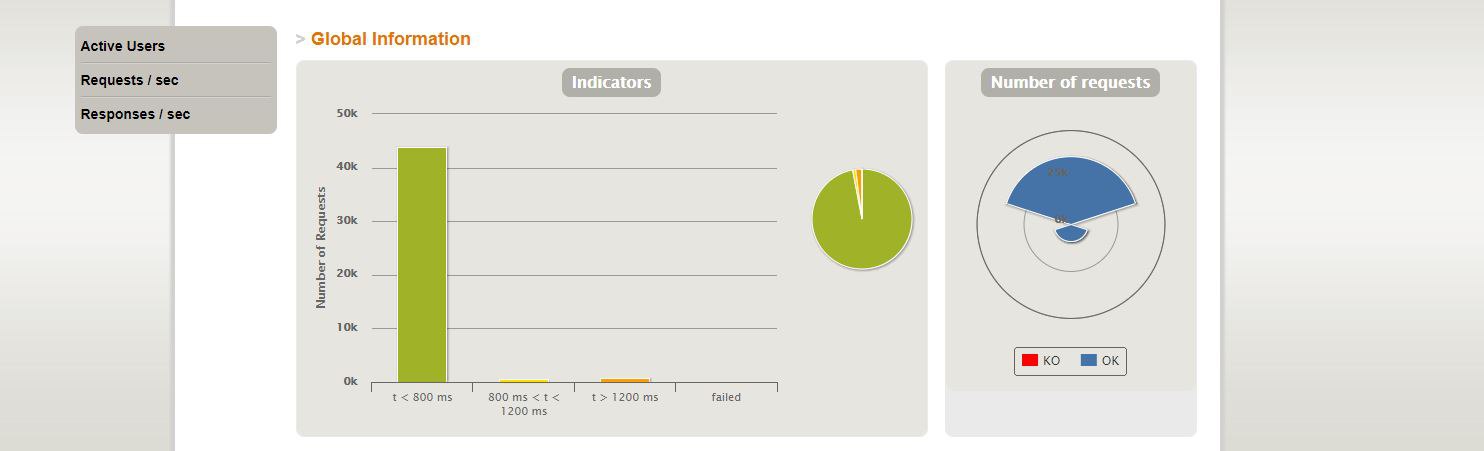 rdcm
rdcm
digital ocean - все запросы ок
rdcm
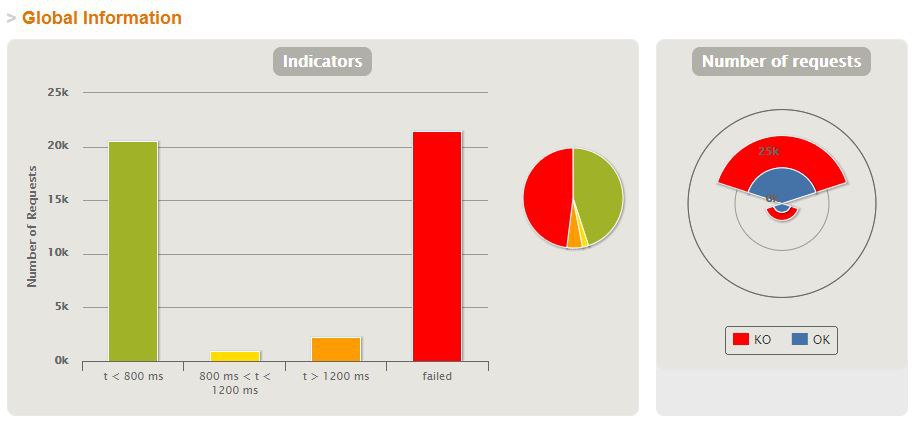 rdcm
rdcm
k8s google - половина отваливается по таймауту
rdcm
коннекшн стринг везде одинаковый
Viktor
В лимит ресурсов мб упирается? Не сталкивался с таким
rdcm
не, ресурсы машин - ок, смотрел
Viktor
Сеть тогда?
Viktor
Гугл мож думает, что ты его ддосишь
rdcm
тогда отлетали бы http запросы а не crud в бд
>Сеть тогда?
Есть простой вариант проверить?)
Viktor
тогда отлетали бы http запросы а не crud в бд
>Сеть тогда?
Есть простой вариант проверить?)
Побомбить монгу напрямую разве что
rdcm
нет, обычный коннекшн, даже без basic authentication, для тестирования
прод через TLS от mongodb atlas
yopp
А в логах монги что?
yopp
Что происходит на сервере когда на начинаются отказы?
yopp
Я имею ввиду с ресурсами что происходит
rdcm
docker образ с монгой
CPU 3.38%
RAM USAGE/LIMIT 294.1MiB / 992.2MiB
NET I/O 545MB / 4.84MB
BLOCK I/O 785MB / 702
логи самой монги
end connection host:port (312 connections now open)
end connection host:port (311 connections now open)
end connection host:port (310 connections now open)
end connection host:port (309 connections now open)
end connection host:port (308 connections now open)после прогона тестов, количество коннектов уменьшается,
на сколько я помню, лимит пула примерно в 300 соединений
rdcm
что просиходит с ресурсами нод в k8s мне пока сложно сказать )
yopp
что просиходит с ресурсами нод в k8s мне пока сложно сказать )
судя по вашему описанию, проблема у вас только с gce. ваше исключение о том, что драйвер не смог выбрать из топологии ни одного сервера за 30с, а это значит что все обнаруженные клиентом сервера недоступы.
вероятнее всего вы упёрлись в какие-то ресурсы или как выше сказали, к вашим контейнерам применили какие-то ограничения
yopp
для этого изучайте что с ресурсами
Anonymous
привет. Нужен совет. Некоторое время назад понадобилось добавить в документ поле, рассчитываемое при запросах. Благополучно заткнул костылём на бэкенде. Но теперь понадобилось осуществлять поиск и фильтрацию по этому полю. Поле меняется раз в сутки. Есть какие-нибудь возможности адекватно реализовать такой функционал?
Daniil
Сделать его хранимым, а когда обновляется - обновлять? В вычисляемых полях нет ничего костыльного
Anonymous
Сделать его хранимым, а когда обновляется - обновлять? В вычисляемых полях нет ничего костыльного
обновление раз в сутки будет для всех записей. Их пока около 900, планируется рост, но не космический. Я бы мог написать скрипт для перебора и апдейта раз в сутки, но правильно ли это?
 V
V
ребят а кто-то сравнивал, mongo и firestore(Google cloud)?
Вообще можно ли как-то объективно сказать что надо брать mongo, чем какое-то cloud решение
Nick
привет. Нужен совет. Некоторое время назад понадобилось добавить в документ поле, рассчитываемое при запросах. Благополучно заткнул костылём на бэкенде. Но теперь понадобилось осуществлять поиск и фильтрацию по этому полю. Поле меняется раз в сутки. Есть какие-нибудь возможности адекватно реализовать такой функционал?
а почему оно меняется раз в сутки? оно строится на данных в документе или тянет доп данные еще откудато?
Anonymous
а почему оно меняется раз в сутки? оно строится на данных в документе или тянет доп данные еще откудато?
Поле считается по текущей дате и датам в полях документа.
Nick
и что туда записывается?
Nick
логически дял чего это сделано
Anonymous
и что туда записывается?
Строка, статус события. Нужно для отображения клиенту, прошло оно или нет, или происходит. А теперь по нему надо еще и запрос строить.
Nick
Строка, статус события. Нужно для отображения клиенту, прошло оно или нет, или происходит. А теперь по нему надо еще и запрос строить.
так почему оно вычислялось? это самое обыкновенное поел со статусом, просто кхарните ег ои изменяйте тогда когда начинается обработка
Anonymous
информация то должна актуальной быть. "Начинается обработка" - какая обработка?
yopp
ребят а кто-то сравнивал, mongo и firestore(Google cloud)?
Вообще можно ли как-то объективно сказать что надо брать mongo, чем какое-то cloud решение
для сравнения сначала необходимо определитсья с параметрами :)
Nick
информация то должна актуальной быть. "Начинается обработка" - какая обработка?
ну вот вы говорите "Нужно для отображения клиенту, прошло оно или нет, или происходит. " вот это ваше "проиходит" в чем заключается?
V
для сравнения сначала необходимо определитсья с параметрами :)
параметры чего? что ты имеешь ввиду?
yopp
с параметрами по которым сравнивать
Anonymous
ну вот вы говорите "Нужно для отображения клиенту, прошло оно или нет, или происходит. " вот это ваше "проиходит" в чем заключается?
Диапазон дат. если сегодняшнее число внутри диапазона, то статус "происходит"
V
скорость обработки запросов на чтение например,одновременных
yopp
сравнивать на синтетических данных никакого смысла не имеет
V
не обязательно это, но ты как mega mongo user, явно уже нашёл ответы
Nick
Диапазон дат. если сегодняшнее число внутри диапазона, то статус "происходит"
и в чем проблема сделать запрос покрывающий ваши задачи? диапазоны дат вполне себе обычный критерий для фильтраций
Nick
давайте с другой стороны, вот вы юзеру что сейчас должны показать?
yopp
все эти тесты производительности обычно натягивают котов на глобус, потому что не учитывают специфику или паттерны конкретного хранилища