 yopp
yopp


какую проблему вы пытаетесь решить?
yopp
этапы не очень интересны
 Viktor
Viktor
предсказать примерное кол-во пользователей, которое может потянуть система
yopp
возьмите самую страшную пиковую нагрузку, замерьте использование ресурсов, поделите на активные сессии, получите утилизацию на 1 сессию
Viktor
у вас на продакшене уже есть нагрузка
есть часы, когда на проде нет нагрузки (или она около 0), в это время и тестим
yopp
это вообще смысла не имеет
yopp
имеет смысл тестировать _реальную_ нагрузку
yopp
потому что от того какой реальный паттерн нагрузки у вас формируется, будет зависеть то, какие грабли вас будут ждать
yopp
вы можете мерять один паттерн «мы пишем много документов» при нулевой нагрузке, получить удовлетворительные результаты, а в бою окажется что это накладывается на момент когда дисковая система загружена чтением и вся всё стоит в iowait
yopp
или что запас ресурсов такой, что туда влазит существенно меньше записи чем показали ваши замеры
yopp
синтетика нужна как относительная метрика: у нас тут стало лучше, тут стало хуже
yopp
и это имеет смысл только как часть CI. в бою надо смотреть в живые данные
Viktor
ну сейчас мы так и используем, как бейзлайн
Viktor
но хотелось бы иметь предсказательную силу
yopp
зачем?
Viktor
чтобы запланировать скейлинг базы
yopp
какой горизонт предсказаний?
yopp
скейлинг базы надо вместе с бизнесом планировать
yopp
у вас уже есть реальные данные, используйте их
yopp
синтетика это иллюзия
Viktor
у меня ситуация такая: приходит бизнес и говорит, что мол в следующем году будет в два раза больше пользователей (бизнес знает точное кол-во, потому что специфика такая), вот мне надо как-то понять скейлить ли базу или задуматься про шардинг или еще что-нибудь
yopp
открываете свой дешборд, берёте точку в которой была самая страшная пиковая нагрузка и смотрите сколько ресрусов использовалось
Viktor
// голова к вечеру не варит уже
yopp
экстраполируете, вычитаете 20-30% и получаете цифру от которой можно будет отталкиваться
Viktor
ага, идею понял
yopp
если вы начали думать о шардинге, значит пришло время шардить
yopp
TL;DR: запас это day-to-day метрика, её можно в дешборде посчитать, а потом попробовать свою собственную методику попытаться опровергнуть сравнив предсказание с реальными данными
yopp
если вы не собираете данные об использовании дискового хранилища, то стоит начать это делать
yopp
вообще всё IO нужно покрыть глазами, как количественными метриками, так и всякими качественными
Viktor
а что подразумевается под качественными?
yopp
50%  загрузка вашего канала, метрика ничего не значащая сама по себе. эти 50% могут быть ретрансмитами, от того что где-то кабель плохо обжали
yopp
сам по себе iowait малозначащая метрика, потому что у вас мог посыпаться диск и там дискач с реаллоакцией
yopp
и так далее
Viktor
направление мысли понял, спасибо
 Юрий
Юрий

 Andrejs Sahniks
Andrejs Sahniks
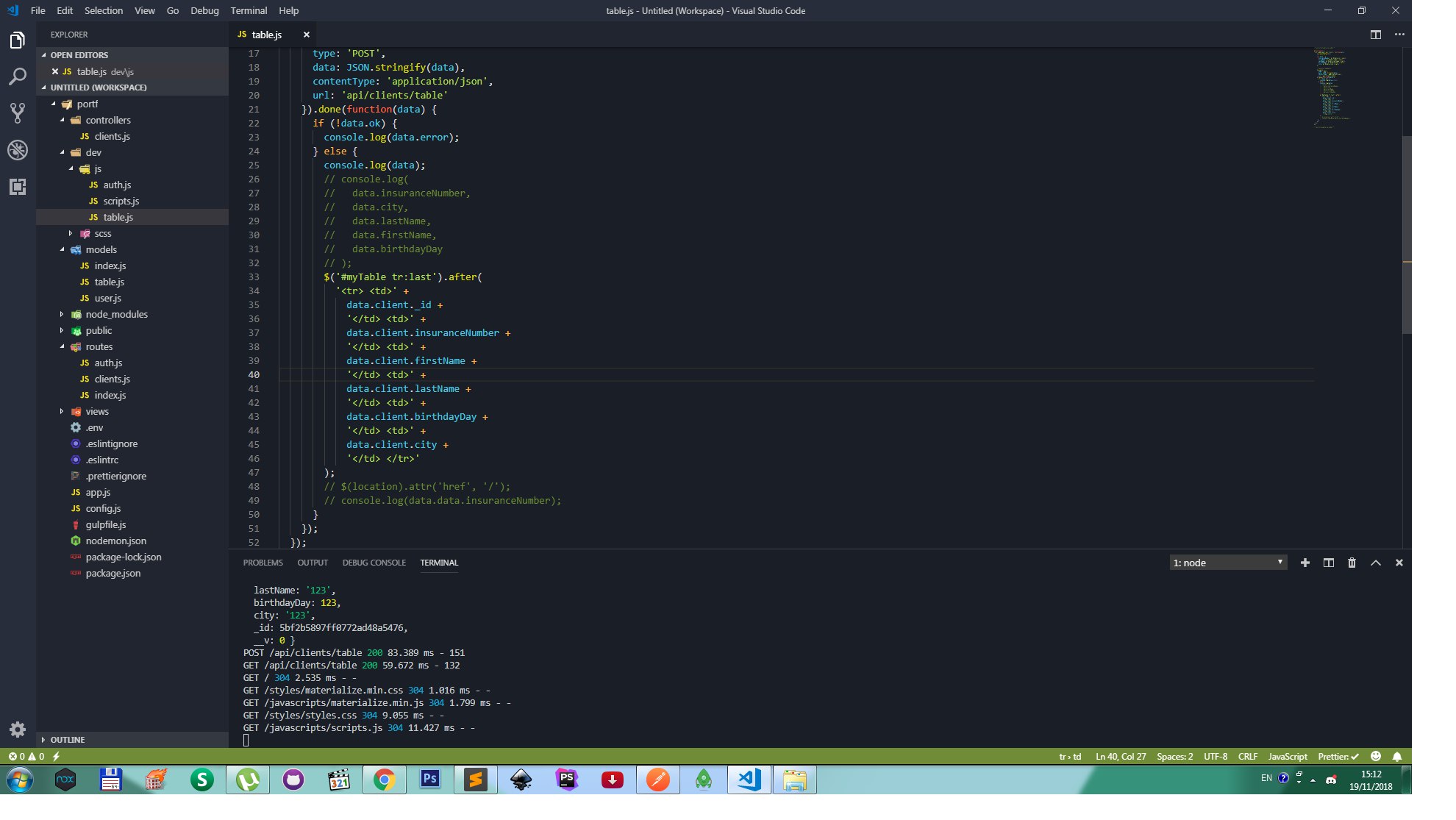
Всем привет у меня есть вопросик, у меня есть база данных в которую сохраняються данные и все работает вот код
Andrejs Sahniks
 Andrejs Sahniks
Andrejs Sahniks
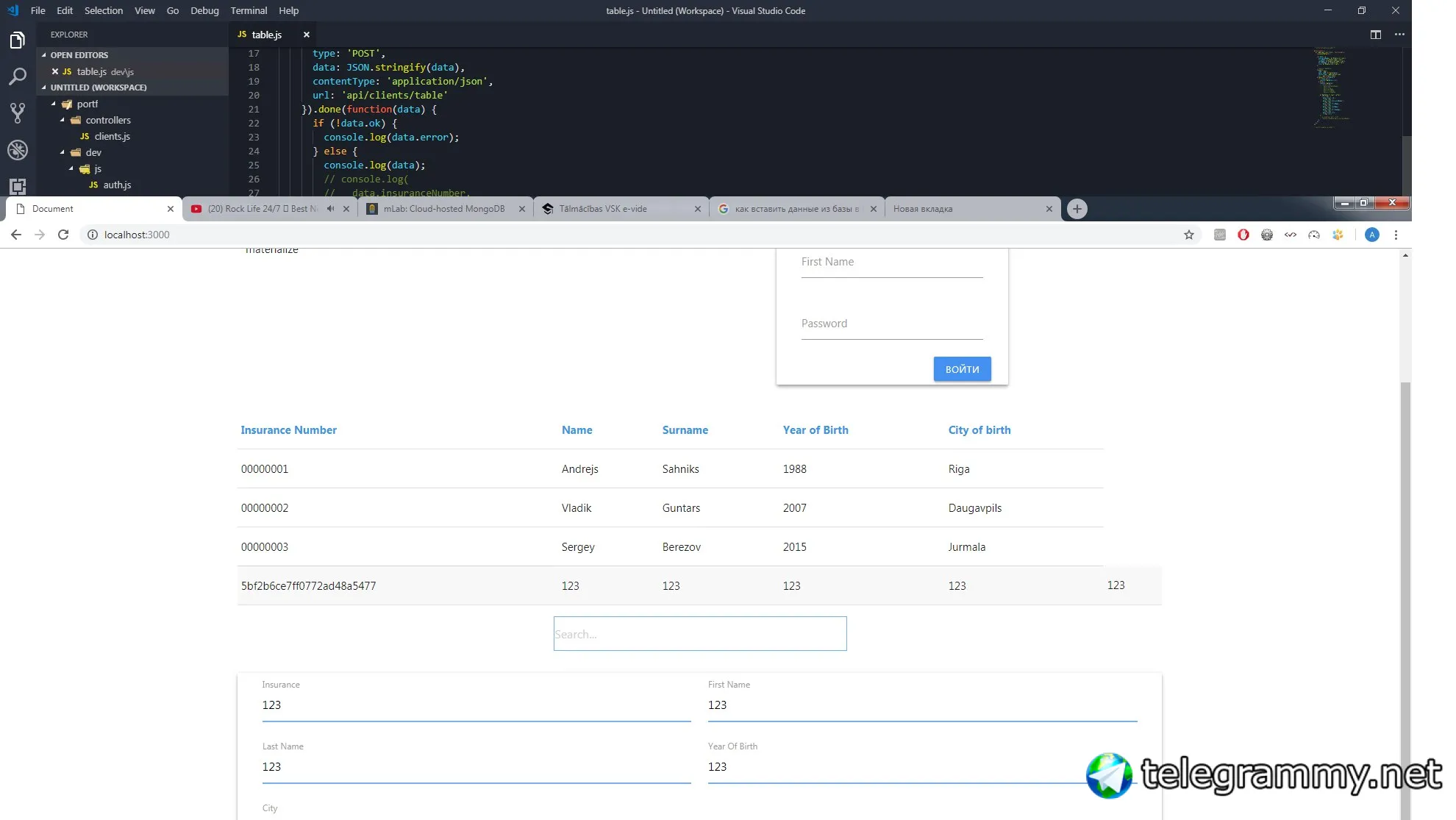
потом всё выводиться в table html
Andrejs Sahniks
 Andrejs Sahniks
Andrejs Sahniks
но после перезагрузки страницы данные пропадают :(
Andrejs Sahniks
как их сохранить, и что для этого использовать...
Andrejs Sahniks
как я понимаю jQuery не добавляет разметку, а только временно вставляет на страницу
 Nick
Nick
 倫太郎
倫太郎
как я понимаю jQuery не добавляет разметку, а только временно вставляет на страницу
как я понимаю жиквери ненужен
 Nor
Nor
Привет
Nor
Не выходит использовать $elemMatch структура документа {_id, field_values: {inn, id}, ...} всегда возвращает пустоту
use erp;
db.erp_order.find(
{
field_values: {
$elemMatch: {
id: 3
}
}
}
)
倫太郎
Не выходит использовать $elemMatch структура документа {_id, field_values: {inn, id}, ...} всегда возвращает пустоту
use erp;
db.erp_order.find(
{
field_values: {
$elemMatch: {
id: 3
}
}
}
)
может потому что опертор $elemMatch для работы с массивами?
Nick
Nor
db.erp_order.find({field_values.id: '3'})
2018-11-19T13:07:21.031+0000 E QUERY [js] SyntaxError: missing : after property id @(shell):1:31
>
Nor
-(
 Alexander
Alexander
парни, можно ли в аггрегации запустить итерацию по массиву, чтобы и элемент был, и его индекс?
Например, есть филд с массивом
[V, V, V, A, A, V, A, V, V, A]
надо выбрать только пары V-A (когда А следует за V)
в ноде это просто итерация с текущим интексом и индексом+1. как в монге такое сделать?
Nor
https://docs.mongodb.com/manual/tutorial/query-embedded-documents/#query-on-nested-field
А есть возможность сделать запрос независимым от типа данных?
yopp
в монге нет типизации аттрибутов, вы можете в виде значения иметь любой тип, который поддерживается BSON
yopp
ключи строго символьные
Nor
Благодарю!
Nor
Теперь осталось это в куери билдер YII2го прикрутить 😵
yopp
парни, можно ли в аггрегации запустить итерацию по массиву, чтобы и элемент был, и его индекс?
Например, есть филд с массивом
[V, V, V, A, A, V, A, V, V, A]
надо выбрать только пары V-A (когда А следует за V)
в ноде это просто итерация с текущим интексом и индексом+1. как в монге такое сделать?
интересная проблема. просто решить не выйдет, насколько мне известно в AF нет операторов над массивами которые и значение и индекс передают. но можно попробовать сделать unwind, добавить поле с индексом, а потом сделать group, преобразовав массив [{o: V, i: 0}, {o: A, i: 1}…]
yopp
и дальше по такому массиву сделать map
yopp
но мне кажется будет проще это сделать на клиенте
Alexander
интересная проблема. просто решить не выйдет, насколько мне известно в AF нет операторов над массивами которые и значение и индекс передают. но можно попробовать сделать unwind, добавить поле с индексом, а потом сделать group, преобразовав массив [{o: V, i: 0}, {o: A, i: 1}…]
я сейчас пробую решить через mapReduce. Если не получится, то, скорее всего, через $unwind придется делать
yopp
но зачем вам это в монге делать?
Alexander
но мне кажется будет проще это сделать на клиенте
на клиенте оверзатратно это будет )) там порядка 10000 записей за неделю )
Nick
)
Alexander
но зачем вам это в монге делать?
в моге я с разными параметрами могу выборку делать разом через $facet
yopp
на клиенте оверзатратно это будет )) там порядка 10000 записей за неделю )
10к записей это чень мало
yopp
$unwind и $group это очень дорого
yopp
mapReduce это очень плохо
Alexander
вай?
yopp
его невозможно отладить нормально
yopp
оно себя очень непредсказуемо ведёт, особенно в sharded окружении. в нём очень легко прострелить себе и соседям коленки :)
Nick
парни, можно ли в аггрегации запустить итерацию по массиву, чтобы и элемент был, и его индекс?
Например, есть филд с массивом
[V, V, V, A, A, V, A, V, V, A]
надо выбрать только пары V-A (когда А следует за V)
в ноде это просто итерация с текущим интексом и индексом+1. как в монге такое сделать?
если вы это сделаете через мап редьюс, то напишите ровно такую же логику как и на клиенте, если у вас js как бек. Но дебажить мапредьюс у вас не выйдет, да и фильтрацию всеравно настроить нормально не сможете
yopp
я бы сделал это на клиенте, раз у вас уже есть готовая логика
yopp
один $unwind и $group по 10к элементам это уже усиление в N*10k, где N размер документа
Alexander
ок, тогда не на клиенте, а на бэке лучше сделать. спасибо за советы
Nick
ну бек/клиент относительно бд одно и то же)
Alexander
ну бек/клиент относительно бд одно и то же)
я к тому, что на клиент лишний раз логику отдавать нет смысла
yopp
Stable: 4.0.4 (Nov 8, 2018) Bugfix: 3.6.9 (Nov 16, 2018), Legacy: 3.4.18 (Nov 7, 2018)
4.0.4: https://docs.mongodb.com/manual/release-notes/4.0/#nov-8-2018
3.6.9: https://docs.mongodb.com/manual/release-notes/3.6/#nov-16-2018
3.4.18: https://docs.mongodb.com/manual/release-notes/3.4/#nov-7-2018
End of life: 3.4 (EOL: June 2019), 3.2.21 (REL: Sep 2018 / EOL: Sep 2018), 3.0.15 (REL: May 2015 / EOL: Feb 2018)
MongoDB quick overview/production notes: https://www.percona.com/live/e17/sites/default/files/slides/Running%20MongoDB%20in%20Production%20-%20FileId%20-%20115299.pdf