 dima
dima


я учу монго. Начинал файрстор но он цук платный. у нас апка повесилась в первый же день тестового релиза
 V
V
я учу монго. Начинал файрстор но он цук платный. у нас апка повесилась в первый же день тестового релиза
но это не объективно, платно иши не платно, монго на middle data уже становися не дешёвым
 Anonymous
Anonymous
и в чем проблема сделать запрос покрывающий ваши задачи? диапазоны дат вполне себе обычный критерий для фильтраций
Будет круто, если примерно подскажете, как искать по диапазону дат. Сейчас они заливаются через монгуз в формате строки даты.
V
вон выше была озвучена цена 126$ в час
Anonymous
давайте с другой стороны, вот вы юзеру что сейчас должны показать?
Сейчас показываем все записи, со статусом для каждой. Появилась задача показывать только с одним статусом.
 yopp
yopp
если у вас уже firestore, то проще на нём дальше и лететь
V
yopp
если у вас монга, то продолжайте ехать на монге
yopp
если вы выбираете новое хранилище, то выбирайте то, с которым у команды больше опыта
 Nick
Nick
Будет круто, если примерно подскажете, как искать по диапазону дат. Сейчас они заливаются через монгуз в формате строки даты.
вот первое что нужно сделать это сделать поле датой. после этого можно использовать $gte и $lt для указания нижней и верхней границ
dima
не подключал к дб
V
если у вас уже firestore, то проще на нём дальше и лететь
вопрос не конкретно мой, а клиентов так как часто приходится объяснять и искать ответы, вот и спрашиваю об опыте. если клиент например хочет в облако полностью но у него уже на mogno все, как объективно можно выявить mongo vs cloud nosql.
как ни крути в cloud - era вопрос актуальный.
yopp
для монги есть atlas
yopp
зачем менять хранилище
Nick
Сейчас показываем все записи, со статусом для каждой. Появилась задача показывать только с одним статусом.
если это дикая пробелма и много логики завязано на это поле, то можно сделать рядом с ним еще одно, которое уже будет датой. пройтись по всем докам и преобразовать сохраненную строку в дату и сохранит ьв новое поле
Anonymous
вот первое что нужно сделать это сделать поле датой. после этого можно использовать $gte и $lt для указания нижней и верхней границ
в базе поле уже дата, если я правильно понял {"$date":%%%}. Если операторы поддерживают и поиск по датам, то это супер, я вам очень благодарен за помощь
Nick
V
если вы выбираете новое хранилище, то выбирайте то, с которым у команды больше опыта
ну получается по ответам что разницы между mongo или cloud nosql не так много, (человеческий факт толькл)
yopp
это неверный вывод
yopp
советовать менять хранилище без очень веского основания — неэффективная трата денег
V
это неверный вывод
да я чувствую что это не так и хотел у тебя знать, так как ты самый опытный в этом.
yopp
смена хранилища это _очень дорого_
V
смена хранилища это _очень дорого_
да вопрос стоял не только в смене но и в выборе объективно, когда например команда формируется
yopp
так что в случае когда у клиента уже есть монга, ему дешевле поехать в атлас
yopp
firestore как и dynamo это автоматический vendor-lock
V
вот у тебя нет ещё специалиста но ты знаешь что есть выбор firestore or mongo и в тупике так как не понимаешь до конца. какие критерии могут тебе указать. на правильность выбора
yopp
нет, потому что я могу уехать с атласа куда угодно
yopp
а с файрстором я остаюсь прибитым к гуглу намертво
V
а с файрстором я остаюсь прибитым к гуглу намертво
но если vendor lock не пугает, то какие ещё могут быть основания выбрать именно монго?
yopp
доступность специалистов, инструментарий, стоимость
yopp
развитие
V
и кстати по поводу atlas, ты сам говорил что если много данных то надо сразу рассматривать вариант шардинга, но я не увидел слов sharding в atlas
V
доступность специалистов, инструментарий, стоимость
подходит ли mongo как сервис на петапайты данных, (search engine)
yopp
наличие коммерческой поддержки, гарантии поддержки, обновления, наличие прозрачного роадмапа, наличие scheduled obsolescence
yopp
я в петабайты не верю
yopp
не верю клиентам которые приходят и рассказывают про петабайты
yopp
покажите ваши петабайты
yopp
утром петабайты, через месяц придумаем где их хранить
yopp
компании с петабайтами это исключение на рынке
V
утром петабайты, через месяц придумаем где их хранить
я не занимаюсь конкретно базой данных, но скаже что там более 20 петабайт
V
на elasticsearch
yopp
терабайты то больно хранить, а петабайты будет больно хранить абсолютно везде. все эти бигдата хранилища лепятся не от хорошей жизни
yopp
и кстати по поводу atlas, ты сам говорил что если много данных то надо сразу рассматривать вариант шардинга, но я не увидел слов sharding в atlas
https://docs.atlas.mongodb.com/create-new-cluster/#create-cluster-sharding
yopp
короче выбирать хранилище по названию, это так себе подход
yopp
берём данные, берём планы запросов, строим тестовые столы
yopp
берём запросы и гоняем их по срезу данных
yopp
смотрим укладываются ли они в установленные требования
yopp
всё остальное это бла-бла-бла
yopp
петабайты в обалке, это надо брать калькулятор и считать
V
всё остальное это бла-бла-бла
ну в общем я и ожидал ответа такого. но я уверен у тебя все равно уже есть наработки
yopp
какие наработки?
yopp
у всех разные данные
yopp
у всех требования разные
Nick
мне интересно неужели люди, у которых из изниоткуда берутся петабайты данных не в состоянии досконально проанализировать работу БД и выбрать подходящую, да и вообещ по идее им должно быть проще под их данные скастомить велосипед
yopp
да не берутся они из ниоткуда
Nick
я про вот это
Nick
подходит ли mongo как сервис на петапайты данных, (search engine)
yopp
1 петабайт это вобще гигантский объём данных, его тяжело просто так взять :) чтоб за год собрать 1 петабайт надо ежедневно генерировать 3 терабайта данных или около 32 мегабит в секунду
Nick
мегабайта может?
Nick
а то 32 мегабита не так уж и много
yopp
непрерывного потока данных на запись? много
yopp
ммм
Nick
я знаю что много, но генерить его досточно легко - обыкновенные логи, по которым есть требование о хранении
yopp
ты прав, кстати, 32 мегабайта :)
yopp
256 мегабит
yopp
я знаю что много, но генерить его досточно легко - обыкновенные логи, по которым есть требование о хранении
3 мегабайта логов в секунду?
 Константин
Константин
 Константин
Константин
 Константин
Константин
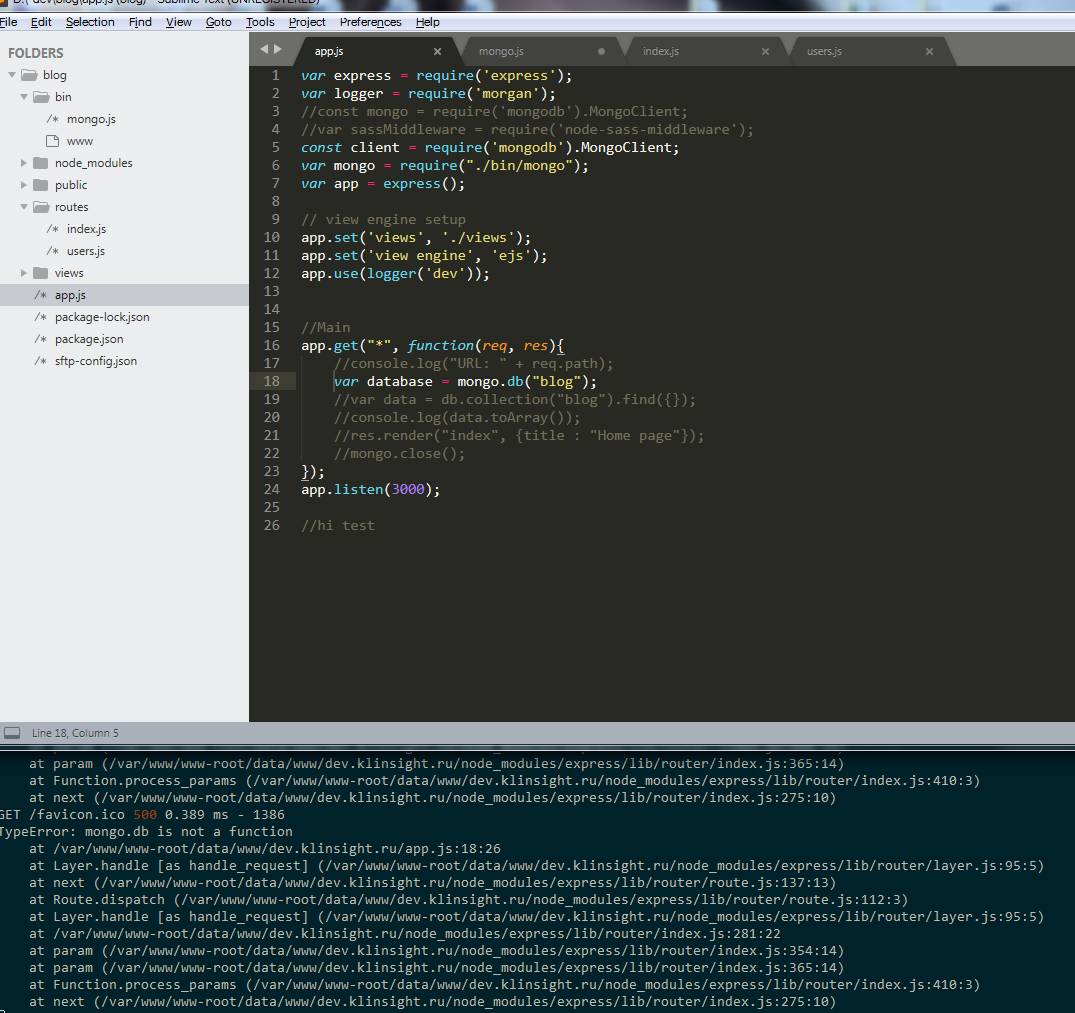
Ребят, помогите плиззз. Что за фигня?
V
мне интересно неужели люди, у которых из изниоткуда берутся петабайты данных не в состоянии досконально проанализировать работу БД и выбрать подходящую, да и вообещ по идее им должно быть проще под их данные скастомить велосипед
хочется быть объективным но и при этом минимизировать, постоянные тесты. и я не говорил сразу о петабайтах, а искал объективные способы оценить базы данных (clouds vs non-cloud), и так как тут yopp самый объективный в mongo я был уверен он уже знает часть ответов
yopp
ты не хочешь слышать совета, а хоешь сразу таблетку
yopp
волшебную