А как тогда сейчас жить с nvme без директ ио?
А можете пояснить для тех кто не в курсе за O_DIRECT, как это поднимет производительность для NVME?
 Pavel
Pavel


 жюн
жюн
А можете пояснить для тех кто не в курсе за O_DIRECT, как это поднимет производительность для NVME?
ну если совсем просто:
прямая запись на диск мимо всех кэшей
жюн
диски нынче настолько быстрые, что идти до них через кучу кешей по итогу получается медленее, чем напрямую
жюн
надеюсь, понятно сказал :)
жюн
 Pavel
Pavel
диски нынче настолько быстрые, что идти до них через кучу кешей по итогу получается медленее, чем напрямую
Ну это очень от диска конечно зависит и от типа доступа, рандомный очень медленный на многих NVME даже сейчас, последовательная запись чтение может быть вполне
жюн
ну вот речь именно про nvme, да
жюн
на шпинделях, думается, это сильно хуже сделает только)
Pavel
ну вот речь именно про nvme, да
Не, речь, что он льет данные на том при помощи dd это чисто последовательна запись.
НА шпинделях кстати при последовательном доступе иногда рекомендуют кэш просто отключать, поскольку наличие блоков в кэше препятствует линейному доступу
 Denver
Denver
Если не ошибаюсь, то на серверных nvme дисках стоят свои кэши с конденсаторами. И смысла в двойном кэшировании нет.
жюн
жюн
кондеи там больше про тему fsync'a
Pavel
Если не ошибаюсь, то на серверных nvme дисках стоят свои кэши с конденсаторами. И смысла в двойном кэшировании нет.
Вопрос в размере кэша NVME как обычно и не забываем про случайный доступ...
жюн
а direct io - это про arc уже zfs'a, а не дисковой подистсемы
если ещё раз - иногда с arc'ом будет медленнее, чем без него (nvme)
жюн
Вопрос в размере кэша NVME как обычно и не забываем про случайный доступ...
я всё равно вот не понимаю, чем вам не нравятся иопсы на nvme, дохера же их там
Pavel
я всё равно вот не понимаю, чем вам не нравятся иопсы на nvme, дохера же их там
Ну не скажите, в однопоточном режиме, их реально мало может быть, конечно не так как на шпинделе.
В общем все от нагрузки конкретной зависит.
жюн
Ну не скажите, в однопоточном режиме, их реально мало может быть, конечно не так как на шпинделе.
В общем все от нагрузки конкретной зависит.
в 1 поток не заоблочно, да, только оно от 128 потоков не умирает)
жюн
ну иопсы прямо исходят из задержек диска
жюн
а на nvme они настолько низки, что гуляние по кэшам оказывает внушительный эффект
Pavel
в 1 поток не заоблочно, да, только оно от 128 потоков не умирает)
Конечно, но вашей программе, которой нужен следующий блок от этого не легче, да 100 программ будут ждать примерно одинаково.
А вот если у вас блок в Arc лежит, то это другое дело...
Pavel
а на nvme они настолько низки, что гуляние по кэшам оказывает внушительный эффект
Я не большой спец конечно, но как я понимаю, универсальных решений нет, важно понимать тип нагрузки для пула.
Раньше для последовательных нагрузок предлагалось отрубать Arc целиком на пуле или кэшировать только метаданные. O_DIRECT видимо позволит это делать более гранулярно для томов и файловых систем.
 Vladislav
Vladislav
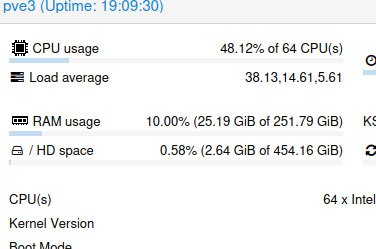
28% одного ядра?
Vladislav
28% от всех ядер?
Vladislav
28 ядер?
Pavel
 Vladislav
Vladislav
Говорит примерно ничего
Vladislav
Открываешь top, nmon, s-tui
Vladislav
открываешь iostat
Vladislav
Vladislav
Что по Used%? Что по wait%?
Pavel
28% это ВМки? 28% это zvol? 28% это khangs? 28% это zfs_wait?
Wait не скопировалось но по-моему в районе 5%
Но лучше я перемерю
Vladislav
Причём тут ZFS?
Pavel
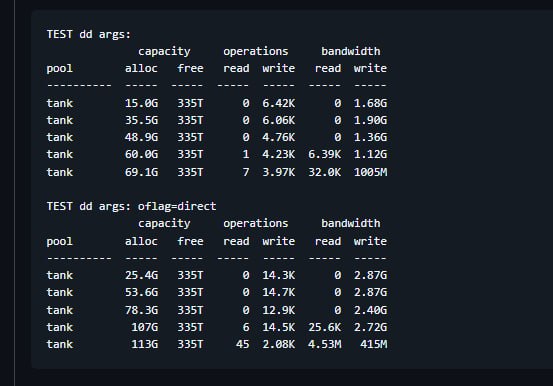
Ну как я тестировал производительность пула с помощью fio
Поверьте на чисто этом NVME эта же конфигурация fio давала загрузку в районе 6%
Vladislav
Берёшь чистый Debian без прокса
Vladislav
Берёшь ZFS и тестируешь
Vladislav
Смотреть на график который говорит попугаи это прикольно
Vladislav
Если нравится на него смотреть, то технических вопросов быть не может
Vladislav
Рекомендую тогда перейти на LVM
Pavel
Берёшь ZFS и тестируешь
Мысль конечно интересная, но вообще я изначально спросил про то, есть ли внятные оценки потребления CPU ZFS-ом для различных сценариев применения и нагрузки?
Ну вот допустим у СУБД публикуются данные по производительности на определенном оборудовании, которые каждый может воспроизвести, если конечно проведет тесты в аналогичных условиях. Есть такие же данные доя SPDK например.
Вот и хотелось увидеть что-то аналогичное для ZFS
Vladislav
Смотришь.
Либо описываешь целиком своё железо от и до
Vladislav
А потом идёшь и открываешь гайды от Intel\AMD и настраиваешь Биос под HPC
 sexst
sexst
Мысль конечно интересная, но вообще я изначально спросил про то, есть ли внятные оценки потребления CPU ZFS-ом для различных сценариев применения и нагрузки?
Ну вот допустим у СУБД публикуются данные по производительности на определенном оборудовании, которые каждый может воспроизвести, если конечно проведет тесты в аналогичных условиях. Есть такие же данные доя SPDK например.
Вот и хотелось увидеть что-то аналогичное для ZFS
И толку от этих публикаций у СУБД - ноль. 20 лет работаю, 20 лет на задачи предварительной оценки железа отвечаю: "ну примерно так, но вообще - хуй знает, нужно тестировать"
Pavel
Смотришь.
Либо описываешь целиком своё железо от и до
Вы меня не понимаете.
Я спрашиваю про эталонные конфигурации и потребление.
Я их сравню со своим потреблением и решу уже куда мне идти :)
Vladislav
Не про то, сколько SAP жрёт CPU. А то сколько транзакций он тебе выдаст на сертифицированном оборудовании
Vladislav
И что тебе даст если скажут, что на Xeon E5 v3 потребление ZFS 2.10 на 2 HDD дисках 2% CPU в последовательном тесте fio 3.13?
sexst
И что тебе даст если скажут, что на Xeon E5 v3 потребление ZFS 2.10 на 2 HDD дисках 2% CPU в последовательном тесте fio 3.13?
Во вторник вечером при ретроградном Марсе
Pavel
И толку от этих публикаций у СУБД - ноль. 20 лет работаю, 20 лет на задачи предварительной оценки железа отвечаю: "ну примерно так, но вообще - хуй знает, нужно тестировать"
Не ну согласитесь, прежде чем мне лезть в биос и настраивать HPC надо понимать верхнюю планку и эталонное потребление.
Нахуя я буду вертеть на хую свое железо, если оно отстает от эталонного в тесте на 10%.
А вот если при примерно одинаковой ситуации у меня оказывается потребление CPU вдвое выше эталона, я задумаюсь
Vladislav
Если мне скажут, что ZFS потребляет 100% CPU на Amd Epyc 9175F (4.2ГГц база, 5ГГц турбо, 16 ядер) с 25 NVMe диска по 15ТБ, я скажу - Нихуя себе
Vladislav
Если мне скажут, что он потребляет 1% - я скажу нихуя себе
sexst
У меня есть x86, aarch64 пары видов, ещё какое-то говно. Что-то из этого с сетевыми стораджами.
Реальность такова, что даже такая, казалось бы, простая вещь уже настолько много переменных несёт, что проще и быстрее погонять нагрузочные тесты и выбрать вариант, чем пытаться посчитать
Vladislav
Не ну согласитесь, прежде чем мне лезть в биос и настраивать HPC надо понимать верхнюю планку и эталонное потребление.
Нахуя я буду вертеть на хую свое железо, если оно отстает от эталонного в тесте на 10%.
А вот если при примерно одинаковой ситуации у меня оказывается потребление CPU вдвое выше эталона, я задумаюсь
Нет, не соглашусь. Если тебе нужна производительность под какую-то задачу - вендор дал тебе ЧТО для этого надо настроить.
sexst
*а ещё лучше и проще заранее заложить заведомо гораздо более мощное железо, дяди оплатят и будут довольны, что всё работает как обещано*
sexst
Ибо им затраты на железо - вообще наименьшая статья расходов
Pavel
#define "эталонное железо"
Да похуй, если есть в чате те у кого пул из NVME типа raid-10 два зеркала vdev
Отзовитесь, я бы скинул параметры fio прогоните скажите какая загрузка CPU и дисков
Vladislav
PM9A3? PM9A1? 970 evo? WD BLUE 250GB?
Vladislav
Ты стебёшься или да?
Pavel
Если мне скажут, что ZFS потребляет 100% CPU на Amd Epyc 9175F (4.2ГГц база, 5ГГц турбо, 16 ядер) с 25 NVMe диска по 15ТБ, я скажу - Нихуя себе
Вот и я смотрю на цифры которые у меня и хуй его знает, много это или мало.
Сравнить блядь не с чем.
Если это нормик то ок, я просто приму это как данность, а если нет буду смотреть что не так с производительностью
sexst
О, про nvme. Никто не видел адаптеров механических, которые позволяют 110мм в 80мм слоты присрать без скотча, но ч нормальным винтовым креплением?
sexst
Я чот поискал и нифига не нашел
жюн
жюн
9300 микроны
Pavel
Пойдет
жюн
а про что беседа? фио погонять там?
sexst
Пятница. Иди пинбол в баре погоняй!
жюн
t1q1 и t1q128 или чего поинтереснее потыкать?
Vladislav
Вот и я смотрю на цифры которые у меня и хуй его знает, много это или мало.
Сравнить блядь не с чем.
Если это нормик то ок, я просто приму это как данность, а если нет буду смотреть что не так с производительностью
Правильно. Потому что это зависит от
-Какие NVMe
-Сколько настроено памяти на arc
-Выключён ли повторяемый буфер FIO
-В рандомные ли участки пишет каждая из job fio или они пишут друг поверх друга (и всё это красиво ложится в буфер)
и т.д.