 Alexey
Alexey


сложно сказать, может у Вас виртуалка на винде и она тянет обновления...
 Andrey
Andrey
то КБ мб
Andrey
если правельно понял запустить и нажать "а" чтобы процессы зафиксировать
Alexey
полезная утилита!
Andrey
полезная утилита!
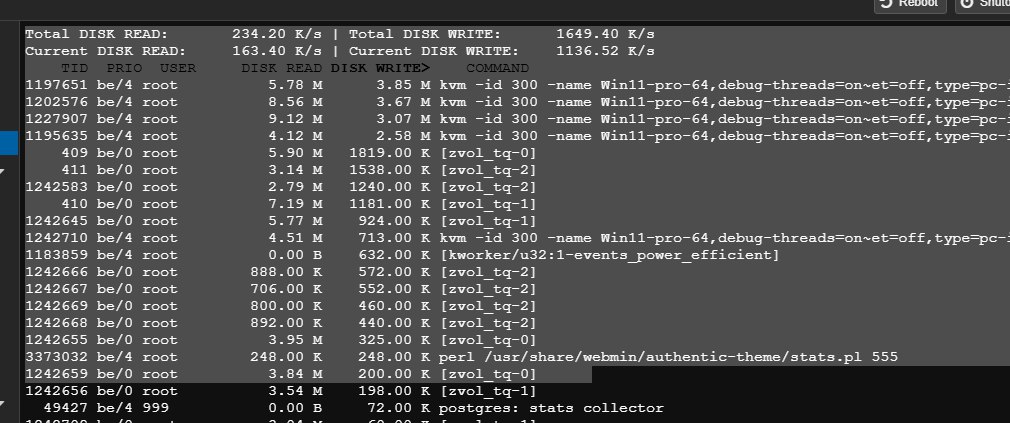
спасибо буду знать, я почему беспокоился у меня 2 диска примерно одна и та же наработка но один диск показывает что 1% износа а второй с примерно такими же данными 0% вот и обратил внимание что что-то пишет нехило
Andrey
 Andrey
Andrey
похоже VM win что-то делает
Alexey
вполне вероятно...
Andrey
единственное я не знаю правельно ли я выбрал ashift=12 для ssd Samsung 970 Evo plus, диск говорит что он 512к
Andrey
раньше я btrfs использовал, там как то такой стремительной записи в зеркале небыло.
Andrey
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
loop0 ext4 1.0 ba49dfd3-6968-4508-8f6c-33522c292b6b 125.4G 38% /var/lib/lxc/700/rootfs
 central
central
раньше я btrfs использовал, там как то такой стремительной записи в зеркале небыло.
какая разница блин какая ФС, вы думаете что процессы чекают какая там файловая система и в зависимости от этого решают писать больше данных или меньше?
central
заходите в винду и смотрите сколько какой процесс написал данных на диск и отрубайте к фигам его если не нужен
Andrey
я правильно понимаю это точка монтирования как раз диска vm c ntfs, но почему тогда определяется как ext4
central
Andrey
Ну да windows что то пишет посмотрел статистику толко в самой виде не видать что пишет. Ну главное что я понял теперь кто виновник
exit_node🙂↕️
Винде в принципе лучше не давать писать. Ну хотя бы не на хдд
Andrey
Винде в принципе лучше не давать писать. Ну хотя бы не на хдд
Ну раньше такого небыло, VM висела в фоне и не писало фоном ни чего, а тут сменил btrfs на zfs и на тебе вот и думаю из-за чего такая фигня. VM погасил.
Станислав
Ну раньше такого небыло, VM висела в фоне и не писало фоном ни чего, а тут сменил btrfs на zfs и на тебе вот и думаю из-за чего такая фигня. VM погасил.
Так может вы вчера переносили ВМ/другие данные?)
Andrey
Переносил неделю назад
Alexey
Возможно, дефрагментация?
 Pavel
Pavel
День добрый.
Может кто-то подсказать, какая примерно должна быть загрузка CPU если у меня pool из двух vdev mirror nvme
Проверял нагрузкой fio rw=randwrite numjobs=4 bs=4k iodeps=128
Жрет в районе 28 CPU 2.6Ghz
Вот хочется понять это нормик или что-то не так?
Pavel
Компрессия тоже стандартная
Nikita
Компрессия тоже стандартная
lz4? попробуйте поставить "compresison=off" на датасете, где проводите тестирование для начала и повторить тест.
Pavel
lz4? попробуйте поставить "compresison=off" на датасете, где проводите тестирование для начала и повторить тест.
Спасибо попробую конечно.
А нет ли где-то внятных оценок потребления CPU ZFS-ом для различных сценариев применения и нагрузки?
Pavel
lz4? попробуйте поставить "compresison=off" на датасете, где проводите тестирование для начала и повторить тест.
Там ещё по мимо сжатия расчет контрольных сумм идет, как с ним бороться?
Можно как-то его офлоадить например у меня карта есть сетевая, которая умеет это делать.
Nikita
Спасибо попробую конечно.
А нет ли где-то внятных оценок потребления CPU ZFS-ом для различных сценариев применения и нагрузки?
Давайте для начала разберемся, что именно у вас эти ресурсы потребляет.
Pavel
Давайте для начала разберемся, что именно у вас эти ресурсы потребляет.
root@pve3:~# zfs get compression testpool/vm-100007-disk-0
NAME PROPERTY VALUE SOURCE
testpool/vm-100007-disk-0 compression off local
root@pve3:~# fio -name=test -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=4 -iodepth=128 -group_reporting -runtime=30 --time_based -filename=/dev/zvol/testpool/vm-100007-disk-0
test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=128
...
fio-3.33
Starting 4 processes
Jobs: 4 (f=4): [w(4)][100.0%][w=302MiB/s][w=77.2k IOPS][eta 00m:00s]
test: (groupid=0, jobs=4): err= 0: pid=459216: Fri Jun 13 17:07:08 2025
write: IOPS=95.3k, BW=372MiB/s (390MB/s)(10.9GiB/30073msec); 0 zone resets
slat (nsec): min=1539, max=2178.0k, avg=4828.74, stdev=9657.20
clat (nsec): min=1425, max=189503k, avg=5367667.17, stdev=12661148.62
lat (usec): min=18, max=189506, avg=5372.50, stdev=12660.85
clat percentiles (usec):
| 1.00th=[ 30], 5.00th=[ 40], 10.00th=[ 61], 20.00th=[ 149],
| 30.00th=[ 219], 40.00th=[ 310], 50.00th=[ 429], 60.00th=[ 652],
| 70.00th=[ 1303], 80.00th=[ 5276], 90.00th=[ 16909], 95.00th=[ 30802],
| 99.00th=[ 66323], 99.50th=[ 78119], 99.90th=[ 96994], 99.95th=[103285],
| 99.99th=[113771]
bw ( KiB/s): min=236389, max=577304, per=100.00%, avg=381870.62, stdev=19085.96, samples=240
iops : min=59097, max=144326, avg=95467.72, stdev=4771.50, samples=240
lat (usec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.01%, 50=8.15%
lat (usec) : 100=6.06%, 250=19.75%, 500=20.25%, 750=8.52%, 1000=4.24%
lat (msec) : 2=7.01%, 4=4.63%, 10=4.04%, 20=8.78%, 50=6.48%
lat (msec) : 100=2.00%, 250=0.07%
cpu : usr=7.74%, sys=14.16%, ctx=1492759, majf=0, minf=17068
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued rwts: total=0,2864510,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs):
WRITE: bw=372MiB/s (390MB/s), 372MiB/s-372MiB/s (390MB/s-390MB/s), io=10.9GiB (11.7GB), run=30073-30073msec
Pavel
 Free
Free
В результате выключения питания испортилось несколько файлов, без которых не запускались мои сервисы.
Удалось "исправить" файлы (на самом деле с потерей информации, но оказалось не критично для моих сервисов) с помощью ddrescue.
Не знаю, так ли это, но есть предположение, что ddrescue изменило содержимое файлов, но не изменило их контрольные суммы (для меня удивительно, как она это могло сделать, минуя файловую систему - но вдруг?)
Мои сервисы заработали.
Но в результате НА ВСЕХ ДИСКАХ ПУЛА РАВНОМЕРНО возникают ошибки контрольных сумм
root@PC3 ~# zpool status s3x10; date
pool: s3x10
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub repaired 0B in 06:04:25 with 94 errors on Mon Jun 9 19:28:29 2025
config:
NAME STATE READ WRITE CKSUM
s3x10 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-ST3000VM002-1ET166_W6A0154H ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A03CVQ ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A046X8 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A04Y1Z ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A05L9D ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0655Q ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A06WE1 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0M5GP ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W7302K8Q ONLINE 0 0 4.92K
ata-ST3000VM002-1F316N_Z301S3TW ONLINE 0 0 4.92K
В конце концов все диски помечаются как degraded.
❓Можно ли заставить zfs пересчитать контрольные суммы файлов (их блоков) в соответствии с текущим содержимым этих файлов и считать их правильными?
 Fedor
Fedor
на этом пуле раньше не было аварий?
Fedor
имхо, если была хоть одна логическая авария, нужно вытаскивать данные и пересоздавать пул начисто, проверив корректность работы аппаратного обеспечения.
Fedor
иначе сайд эффекты могут поползти
Free
Ну вот при отключении питания и была авария.
Вот какие-то файлы "вытащил", исправил.
На ошибки аппаратные сейчас не похоже: если бы ошибки появлялись только на одном (ну, даже на нескольких) дисках - можно было бы подозревать диски, кабели, контроллер и т.д.
Но когда НА ВСЕХ СТРОГО ОДИНАКОВОЕ количество (и растет монотонно равномерно) - мне кажется это аппаратные проблемы исключает
 George
George
В результате выключения питания испортилось несколько файлов, без которых не запускались мои сервисы.
Удалось "исправить" файлы (на самом деле с потерей информации, но оказалось не критично для моих сервисов) с помощью ddrescue.
Не знаю, так ли это, но есть предположение, что ddrescue изменило содержимое файлов, но не изменило их контрольные суммы (для меня удивительно, как она это могло сделать, минуя файловую систему - но вдруг?)
Мои сервисы заработали.
Но в результате НА ВСЕХ ДИСКАХ ПУЛА РАВНОМЕРНО возникают ошибки контрольных сумм
root@PC3 ~# zpool status s3x10; date
pool: s3x10
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub repaired 0B in 06:04:25 with 94 errors on Mon Jun 9 19:28:29 2025
config:
NAME STATE READ WRITE CKSUM
s3x10 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-ST3000VM002-1ET166_W6A0154H ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A03CVQ ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A046X8 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A04Y1Z ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A05L9D ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0655Q ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A06WE1 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0M5GP ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W7302K8Q ONLINE 0 0 4.92K
ata-ST3000VM002-1F316N_Z301S3TW ONLINE 0 0 4.92K
В конце концов все диски помечаются как degraded.
❓Можно ли заставить zfs пересчитать контрольные суммы файлов (их блоков) в соответствии с текущим содержимым этих файлов и считать их правильными?
пока не понял как вы использовали ddrescue. Но, как и для любой ФС, частично менять руками байты на диске без готовности руками же править метаданные (а значит - и разобраться в on-disk структуре данных) категорически не рекомендуется.
Ближе к делу - если хотите заменить в zfs данные на "правильные" - просто сделайте это поверх zfs, он должен принимать на запись полный блок даже если с ним что-то не так на диске. Тогда и метаданные будут уже правильные.
Free
пока не понял как вы использовали ddrescue. Но, как и для любой ФС, частично менять руками байты на диске без готовности руками же править метаданные (а значит - и разобраться в on-disk структуре данных) категорически не рекомендуется.
Ближе к делу - если хотите заменить в zfs данные на "правильные" - просто сделайте это поверх zfs, он должен принимать на запись полный блок даже если с ним что-то не так на диске. Тогда и метаданные будут уже правильные.
Просто копировать поврежденный файл поверх zfs не получалось: при попытке чтения файла выдавалась i/o error.
ddescue использовал командами вида:
ddrescue /s3x10/304/storage/BAD/hashtbl-0000000000000230.BAD /s3x10/304/storage/BAD/hashtbl-0000000000000230 log304.txt
George
В результате выключения питания испортилось несколько файлов, без которых не запускались мои сервисы.
Удалось "исправить" файлы (на самом деле с потерей информации, но оказалось не критично для моих сервисов) с помощью ddrescue.
Не знаю, так ли это, но есть предположение, что ddrescue изменило содержимое файлов, но не изменило их контрольные суммы (для меня удивительно, как она это могло сделать, минуя файловую систему - но вдруг?)
Мои сервисы заработали.
Но в результате НА ВСЕХ ДИСКАХ ПУЛА РАВНОМЕРНО возникают ошибки контрольных сумм
root@PC3 ~# zpool status s3x10; date
pool: s3x10
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub repaired 0B in 06:04:25 with 94 errors on Mon Jun 9 19:28:29 2025
config:
NAME STATE READ WRITE CKSUM
s3x10 ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-ST3000VM002-1ET166_W6A0154H ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A03CVQ ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A046X8 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A04Y1Z ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A05L9D ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0655Q ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A06WE1 ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W6A0M5GP ONLINE 0 0 4.92K
ata-ST3000VM002-1ET166_W7302K8Q ONLINE 0 0 4.92K
ata-ST3000VM002-1F316N_Z301S3TW ONLINE 0 0 4.92K
В конце концов все диски помечаются как degraded.
❓Можно ли заставить zfs пересчитать контрольные суммы файлов (их блоков) в соответствии с текущим содержимым этих файлов и считать их правильными?
ну и кстати да, это не файлы испортились, а приложение не умеет переживать потерю питания. Если на zfs проходит скраб, то это значит что он успешно записал что ему передали (за оговоркой того, что переданное ему был цело, да, тут про ecc)
George
Просто копировать поврежденный файл поверх zfs не получалось: при попытке чтения файла выдавалась i/o error.
ddescue использовал командами вида:
ddrescue /s3x10/304/storage/BAD/hashtbl-0000000000000230.BAD /s3x10/304/storage/BAD/hashtbl-0000000000000230 log304.txt
так зачем читать? если вы хотели перезаписать
Free
так зачем читать? если вы хотели перезаписать
Чтение имелось в виду при копировании.
Когда пытался скопировать файл для его изучения/исправления в другом месте.
В результате сделал mv файла в другое место, там исправил, и исправленную копию вернул на место
George
ох, т.е. zfs всё же считал что есть проблемы с данными? тогда и правда по железу вопросы
Free
Столько проблем находите, удивительно. Память ECC на сервере?
У меня 8 серверов.
На 6 из них (в том числе на тех, про ошибки которых ранее рассказывал) ECC.
Этот пул стоял на десктопе
Free
ох, т.е. zfs всё же считал что есть проблемы с данными? тогда и правда по железу вопросы
Да, данные как-то испортились, я в данном случае zfs не виню.
Но мне удалось файл "исправить" - так, что мои сервисы их проглотили.
Теперь на эих исправленных файлах ошибки чтения не возникает.
Но идут массировано ошибки CRC от zfs.
Подозреваю, что именно от этих "исправлений".
И вопрос был - нельзя ли упросить zfs подправить на этих файлах CRC.
Как мне казалось - скраб (берущий в случае ошибок информацию из дополнительных копий) в этом случае не поможет, потому что исправленные файлы, видимо, во всех копиях имеют одну и ту же информацию.
Но если других идей нет - попробую прогнать скраб.
George
Да, данные как-то испортились, я в данном случае zfs не виню.
Но мне удалось файл "исправить" - так, что мои сервисы их проглотили.
Теперь на эих исправленных файлах ошибки чтения не возникает.
Но идут массировано ошибки CRC от zfs.
Подозреваю, что именно от этих "исправлений".
И вопрос был - нельзя ли упросить zfs подправить на этих файлах CRC.
Как мне казалось - скраб (берущий в случае ошибок информацию из дополнительных копий) в этом случае не поможет, потому что исправленные файлы, видимо, во всех копиях имеют одну и ту же информацию.
Но если других идей нет - попробую прогнать скраб.
Если zfs даёт считать эти блоки, то он их не считает проблемными и чексуммы верные (если их не отключали).
а что про сами ошибки - если пул не переходит в состояние suspended (и доступ к нужным данным есть) значит zfs считает что он смог исправить проблему, по хорошему вам бы бекап снять, но вообще да - 2 раза прогнать скраб и дать фс саму себя полечить если она сможет
Free
Если zfs даёт считать эти блоки, то он их не считает проблемными и чексуммы верные (если их не отключали).
а что про сами ошибки - если пул не переходит в состояние suspended (и доступ к нужным данным есть) значит zfs считает что он смог исправить проблему, по хорошему вам бы бекап снять, но вообще да - 2 раза прогнать скраб и дать фс саму себя полечить если она сможет
Да вот исправляет-исправляет, а чексуммы всё прибавляются...
Раньше никогда не видел, чтобы так равномерно по всем дискам raidz2.
Интересно, почему при одинаковом количестве ошибок какие-то диски считает, что too many errors (причем на значительно меньших значениях начинает), а какие-то нет (вот один даже при 59.9К не too many)
NAME STATE READ WRITE CKSUM
s3x10 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-ST3000VM002-1ET166_W6A0154H DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A03CVQ DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A046X8 DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A04Y1Z DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A05L9D DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A0655Q DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A06WE1 DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A0M5GP DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W7302K8Q DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1F316N_Z301S3TW ONLINE 0 0 59.9K
George
Да вот исправляет-исправляет, а чексуммы всё прибавляются...
Раньше никогда не видел, чтобы так равномерно по всем дискам raidz2.
Интересно, почему при одинаковом количестве ошибок какие-то диски считает, что too many errors (причем на значительно меньших значениях начинает), а какие-то нет (вот один даже при 59.9К не too many)
NAME STATE READ WRITE CKSUM
s3x10 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-ST3000VM002-1ET166_W6A0154H DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A03CVQ DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A046X8 DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A04Y1Z DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A05L9D DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A0655Q DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A06WE1 DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W6A0M5GP DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1ET166_W7302K8Q DEGRADED 0 0 59.9K too many errors
ata-ST3000VM002-1F316N_Z301S3TW ONLINE 0 0 59.9K
первый скраб как раз ищет проблемы и увеличивает их счётчики. Второй скраб как раз и нужен чтобы уже найденные и полеченные проблемы убрать из статуса пула.
Alexey
День добрый.
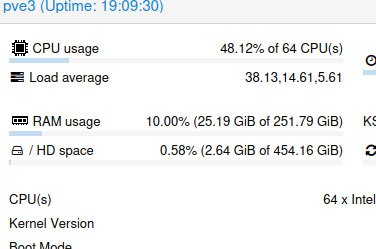
Может кто-то подсказать, какая примерно должна быть загрузка CPU если у меня pool из двух vdev mirror nvme
Проверял нагрузкой fio rw=randwrite numjobs=4 bs=4k iodeps=128
Жрет в районе 28 CPU 2.6Ghz
Вот хочется понять это нормик или что-то не так?
на debian12 6.12.12+bpo-amd64
zfs-2.3.1-1~bpo12+1
zfs-kmod-2.3.1-1~bpo12+1
при переносе примерно 256 гб данных (zfs send пулл1 | zfs receive пулл2)
загрузка была примерно 8,5 ядер на 100% amd epyc 7302
пулл1 - это зеркало 2 HDD 500гб
пулл2 - draid1 3 HDD 1000гб сжатие zstd по умолчанию.
время переноса 35мин. средняя скорость записи на пулл2 - 155мб/сек. На диски - 52мб/сек.
средняя скорость чтения с пулл1 - 101 мб/сек. С дисков по 50мб/сек.
Переносился один zfs volume.
Alexey
defaults
жюн
Мужики, а поясните пожалуйста про o_direct, как вообще включено/нет оно в конкретном пуле?
Станислав
Мужики, а поясните пожалуйста про o_direct, как вообще включено/нет оно в конкретном пуле?
А Вы собрали ZFS с ним?
жюн
я где-то слышал, для zvol'ов его добавили
жюн
или о каком сборе речь?
Станислав
надо билдить, оно не присутствует ещё?
В 3.0 планируется, насколько знаю. Чтобы сейчас попробовать, нужно самостоятельно собрать для текущей версии
жюн
В 3.0 планируется, насколько знаю. Чтобы сейчас попробовать, нужно самостоятельно собрать для текущей версии
https://github.com/openzfs/zfs/releases/tag/zfs-2.3.0
в 2.3.0
жюн
а у меня с proxmox'ом последним 2.2.7 только приехало > никаких директов там и в помине нет)
жюн
А как тогда сейчас жить с nvme без директ ио?
 Vladislav
Vladislav
Прочитай коммит
Vladislav
https://github.com/openzfs/zfs/pull/10018
Vladislav
 Vladislav
Vladislav
 жюн
жюн
там про zvol'ы отдельный pr был
жюн
сейчас поищу
Vladislav
там про zvol'ы отдельный pr был
https://github.com/openzfs/zfs/issues/12483
"Note that ZFS will always use the ARC in both the non-O_DIRECT and O_DIRECT cases (although this may change with"
жюн
видимо, я шизею уже, нашел как раз твоё в Витасторе, ты писал что наоборот для zvol'ов нет его ещё
Vladislav
"Just to be sure it wasn't ZFS behavior, I also explicitly cleared O_DIRECT on any zvol write: but got the same performance results I saw earlier."
Pavel
на debian12 6.12.12+bpo-amd64
zfs-2.3.1-1~bpo12+1
zfs-kmod-2.3.1-1~bpo12+1
при переносе примерно 256 гб данных (zfs send пулл1 | zfs receive пулл2)
загрузка была примерно 8,5 ядер на 100% amd epyc 7302
пулл1 - это зеркало 2 HDD 500гб
пулл2 - draid1 3 HDD 1000гб сжатие zstd по умолчанию.
время переноса 35мин. средняя скорость записи на пулл2 - 155мб/сек. На диски - 52мб/сек.
средняя скорость чтения с пулл1 - 101 мб/сек. С дисков по 50мб/сек.
Переносился один zfs volume.
Спасибо большое за отклик.
Я просто не ожидал, что диски NVME будут не загружены, а процессор уйдет почти в полку.
Видимо нужны значительно более производительные процы для пулов на NVME... :(
Alexey
Вполне возможно.