Логично, потому что сперва надо импортнуть пулы
ЧТОБЫ ОНИ В СЛУЧАЕ ЕСЛИ НЕ ИМПОРТНУТСЯ - ЕХАТЬ В ДАЛЬНЮЮ ДОРОГУ
 Dexex
Dexex


 Vladislav
Vladislav
ЧТОБЫ ОНИ В СЛУЧАЕ ЕСЛИ НЕ ИМПОРТНУТСЯ - ЕХАТЬ В ДАЛЬНЮЮ ДОРОГУ
А смысл? У тебя данных нет
Vladislav
Вот загрузился ты. А у тебя /etc лежит на ZFS
Vladislav
Как пример
Dexex
А потом все остальное
Vladislav
Иными словами. Порядок загрузки по умолчанию спокойно уходит в таймаут по импорту (600с вроде), если ядро не крашится
А если ядро крашится, то что-то нахуевертили. К примеру, обновили ядро не обновив ZFS
Dexex
Иными словами. Порядок загрузки по умолчанию спокойно уходит в таймаут по импорту (600с вроде), если ядро не крашится
А если ядро крашится, то что-то нахуевертили. К примеру, обновили ядро не обновив ZFS
Нет. У меня я так понимаю куча незавершенных транзакций
Dexex
Может мне эти данный в начале нафик не нужны, там vpn сервер и dns стоит. А оно полностью прерывает процесс загрузки сети
Dexex
Сейчас я скачиваю данные. Они доступны.
Dexex
После скорее всего пересоздам пул. zfs в отказоустойчивость не шмогла
Dexex
Это по факту. С этими транзакциями полная задницы. На SSD все отлично как правило. Но на HDD - zfs часто подводит своими приколами.
Dexex
swapА накинул на ssd диске системном, если памяти хватать не будет посмотрим. Пожалуй по итогу будет пересоздание пула
Vladislav
Вообще, у меня был анекдот с ZFS и Toshiba P300 3TB 5400rpm, но это просто потому что у него слишком высокая задержка была и ZFS считал, что это таймаут операции
Dexex
Вдруг прожует это. До завтра. Если не прожует - нахер диски потру живые и пересоздам ибо нафиг
Andrey
 Dexex
Dexex
Вообще, у меня был анекдот с ZFS и Toshiba P300 3TB 5400rpm, но это просто потому что у него слишком высокая задержка была и ZFS считал, что это таймаут операции
Да одному богу известно сколько там таких приколов еще найдется. zfs живет своей жизнью
Dexex
primarycache=none не отключает arc, он просто говорит пулу чтобы не использовал arc, который выделило ядро zfs
необходимо задать параметры zfs_arc_max и zfs_arc_min минимальными и я думаю равными друг другу, например 250 Мб
options zfs zfs_arc_min=268435456
options zfs zfs_arc_max=268435456
через /etc/modprobe.d/zfs.conf
и перезагрузиться
или динамически
echo 268435456 > /sys/module/zfs/parameters/zfs_arc_min
echo 268435456 > /sys/module/zfs/parameters/zfs_arc_max
и сбросить кэши sync; echo 3 > /proc/sys/vm/drop_caches
Значение 0 не отключает arc cache, а определяет поведение по умолчанию - забирается половина всей памяти и в случае повышенного ее потребления как раз появляются эти процессы, которые пытаются поджать arc
Пробую. Кстати система не перезагружается. Оно фризится нафиг, потому что он не может сделать unmount
Dexex
Ну кеши я сбрасываю = 0 реакции потому что оно даже status не может показать.
Dexex
Че там происходит я хз
Dexex
Короче пересоздать пул придется скорее всего. Не решаемо как по мне.
Dexex
Но данные доступны! Хотя бы так
Andrey
zfs_arc_max и zfs_arc_min должны быть скорее всего равны, т к при нехватке памяти процессы evict и prune по идее должны увидеть, что поджимать arc некуда, т к он жестко задан.
Но если не будет хватать памяти системе видимо активизируется своп и oomkiller
Andrey
Буквально на днях была похожая ситуация, zfs начал жрать память.
Проблема возникла из-за проблем с дисками.
Появились ошибки на пуле
после двухкратного zpool scrub все починилось
 Alexey
Alexey
коллеги, не забывайте писать хотя бы версию пула и ядра.
Alexey
а то не понятно, бояться нам того же или нет :)
 Free
Free
zfs_arc_max и zfs_arc_min должны быть скорее всего равны, т к при нехватке памяти процессы evict и prune по идее должны увидеть, что поджимать arc некуда, т к он жестко задан.
Но если не будет хватать памяти системе видимо активизируется своп и oomkiller
У меня вначале они и были одинаковые (=8). Все равно evict и prune возбуждались.
Alexey
У меня вначале они и были одинаковые (=8). Все равно evict и prune возбуждались.
есть у меня где-то в памяти, что нельзя их делать одинаковыми. Они должны быть в пропорции. Вроде 4:1
Alexey
Это минимальная пропорция. Но не настаиваю, что это верно...
 Hennadii
Hennadii
После скорее всего пересоздам пул. zfs в отказоустойчивость не шмогла
zfs в отказоустойчивость не шмогла
какая именно версия zfs там используется?
причина проблем может быть как в коде zfs (если используется нестабильная версия) так и в hardware (например, память без ECC, которая глючит, или глючная материнская плата, процессор, блок питания), или же проблемы могут быть в настройке zfs - если она не может понять такого прикола, когда pool создан с короткими именами дисков /dev/sda /dev/sdb и т.п. и эти диски часто меняются в системе местами - возможно никакой защиты от этого в коде файловой системы нет - в документации не рекомендуется создавать pool используя короткие имена дисков. А если использовать полные имена дисков из /dev/disk/by-id - так они не меняются и всегда статичны.
было бы интересно все таки понять root cause проблемы, потому что "zfs в отказоустойчивость не шмогла" - это может быть слишком поспешный вывод, на нормальном железе и при нормальной настройке как правило стабильные версии не глючат - в Lawrence Livermore National Laboratory же создатели OpenZFS используют ее как основу для Lustre, для самого мощного ( по данным сайта https://top500.org/ ) кластера в мире - https://computing.llnl.gov/projects/openzfs - и у них все получается нормально и почему-то у них нет такой проблемы, что "zfs в отказоустойчивость не шмогла". вот и хотелось бы лучше понять, что именно они делают не так, что у них эта Ваша проблема не воспроизводится.
Hennadii
перезагрузка после паники ядра отключена ?
Да:
root@S04:~# cat /proc/sys/kernel/panic
0
и если мы видим перезагруженный сервер в данном случае, то это должно быть аппаратная проблема.
Не объясняет, почему при уменьшении количества запущенных нод перезагрузки становятся реже (и даже совсем пропадают при количестве нод примерно менее половины).
Не говоря о том, что аптайм до апгрейда был несколько месяцев в полной загрузке.
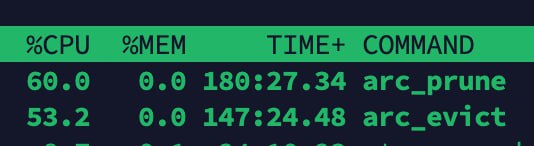
И вообще исходный вопрос был: чем так интенсивно занимаются arc_prune и arc_evict при primarycache=none на всех датасетах и как этого избежать.
если автоматическая перезагрузка сервера в случае kernel panic отключена и при этом сервер все таки самопроизвольно перезагружается - это практически 100% говорит об аппаратной проблемы сервера.
а если проблема аппаратная - то никакими настройками размера ARC эту проблему исправить не получится.
Andrey
Да, проблема с памятью наблюдалась с такой версией
На 2.0.7 и более ранних и 2.2.4 при проблемах с дисками такой проблемы не наблюдалось
Alexey
на дебиан 12 версия zfs 2.2.7
Alexey
посмотрите:
Alexey
apt search zfs-dkms
Alexey
какую версию выдает?
Andrey
По проблеме
https://github.com/openzfs/zfs/issues/14005
ARC eviction code was completely rewritten in upcoming ZFS 2.2.
Ivan
Подскажите по работе direct io, я ожидал прироста производительности, но получил обратное. Как его правильно использовать, что от него ожидать ?
У меня root на zfs, использую на nvme. Поставил zfs 2.3, убедился что zfs_dio_enabled включена. Вижу что arc как использовался, так и используется (хотя пишут что он не будет использоваться при directio), ну я его подрезал сделав primarycache=none и указав fs_arc_min/max в минимальное значение.
cat /sys/module/zfs/parameters/zfs_dio_enabled
1
zfs -V
zfs-2.3.0-1
zfs-kmod-2.3.0-1
uname -a
6.12.13-amd64
Vladislav
Подскажите по работе direct io, я ожидал прироста производительности, но получил обратное. Как его правильно использовать, что от него ожидать ?
У меня root на zfs, использую на nvme. Поставил zfs 2.3, убедился что zfs_dio_enabled включена. Вижу что arc как использовался, так и используется (хотя пишут что он не будет использоваться при directio), ну я его подрезал сделав primarycache=none и указав fs_arc_min/max в минимальное значение.
cat /sys/module/zfs/parameters/zfs_dio_enabled
1
zfs -V
zfs-2.3.0-1
zfs-kmod-2.3.0-1
uname -a
6.12.13-amd64
Он будет работать только если у тебя нагрузка из 5-10 потоков
Vladislav
Но деградации я не помню при 1 потоке
Ivan
Но деградации я не помню при 1 потоке
я тестов не проводил. но на глаз заметно как приложения начали запускаться заметно дольше. будто на hdd пересел. похоже я зря арк подрезал, но с другой стороны обещали что он не будет использоваться при directio, а он продолжал использоваться.
Vladislav
На пул флаг выставлен direct=always ?
Vladislav
A new dataset property direct has been added with the following 3
allowable values:
disabled - Accepts O_DIRECT flag, but silently ignores it and treats the request as a buffered IO request.
standard - Follows the alignment restrictions outlined above for write/read IO requests when the O_DIRECT flag is used.
always - Treats every write/read IO request as though it passed O_DIRECT. In the event the request is not page aligned, it will be redirected through the ARC. All other alignment restrictions are followed.
Vladislav
у меня только флаг direct есть, он в standard
так очень мало какое приложение пишет в o_direct
Ivan
о, спасибо. понаблюдаю че как.
Hennadii
https://habr.com/ru/companies/vk/articles/529516/
[...]
В настоящий момент в планах на развитие идет упор на производительность, к примеру на оптимизацию для NVMe. Они дорогие, хочется выжать из них максимум. ARC в данном случае не даёт сильного выигрыша, так как это дополнительные операции по копированию данных в ОЗУ. Сейчас, если поставить 5 — 10 NVMe, мы быстро упремся в производительность ОЗУ и ЦПУ. Специально для этого случая ведутся работы по поддержке direct io с целью исключения лишних операций в ARC.
[...]
То есть, direct io даст прирост производительности только в случае когда 5-10 и больше NVMe в сервере. Тест от Phoronix это и подтверждает - при тестировании zpool, состоящем из 12 шт. Samsung PM1725a NVMe SSD они получили прирост производительности в три раза на операциях чтения и полтора раза на операциях записи.
Если же обычная для серверов ситуация и там всего два NVMe в mirror - то принудительное включение режима direct io может и не дать прироста производительности, потому что скорость обмена данными с ARC в RAM будет все-таки быстрее, чем скорость прямого чтения и записи NVMe при отключенном ARC.
 The Join Captcha Bot
The Join Captcha Bot
Татьяна Кравец не удалось разгадать капчу. "пользователя" выгнали.
Free
для меня важнее было сэкономить несколько гигов рамы за счет избавления от arc без явной потери производительности.
А каким образом удалось избавиться от arc?
Ivan
А каким образом удалось избавиться от arc?
полностью не удалось избавиться, только ограничил его размер.
Hennadii
размером ARC можно управлять через zfs_arc_min и zfs_arc_max и экономии памяти можно добиться таким способом, уменьшив размер ARC до минимально возможного значения и установив zfs_arc_min и zfs_arc_max в одинаковое значение. И меньше самого минимального значения - размер ARC сделать не получится, он все равно не будет нулевым.
а если необходимо запретить кэширование данных в ARC, это можно сделать установив primarycache=metadata для всех датасетов - тогда в ARC будут попадать только метаданные.
если поменять primarycache=all на primarycache=metadata - тогда уменьшится "нагрузка" на память, но увеличится нагрузка на дисковую подсистему. Если установить primarycache=none в таком случае - еще сильнее уменьшится "нагрузка" на память, но еще больше возрастет нагрузка на накопители, и файловая система будет еще сильнее тормозить.
если ядерные процессы, связанные с arc начинают занимать много процессора - то имеет смысл найти root cause именно этой проблемы и найти как именно эту проблему устранить - это ошибка в коде zfs, или это аппаратные проблемы с сервером. вполне может быть и так, что это ошибка в коде, или какие-то неоптимальные алгоритмы, когда процесс ядра, работающий с arc много времени крутится в spinlock и тупо выжирает процессор таким образом.
кроме того, на сайте Proxmox есть такая рекомендация:
https://pve.proxmox.com/wiki/ZFS_on_Linux#sysadmin_zfs_limit_memory_usage
Limit ZFS Memory Usage
[...]
Allocating enough memory for the ARC is crucial for IO performance, so reduce it with caution. As a general rule of thumb, allocate at least 2 GiB Base + 1 GiB/TiB-Storage. For example, if you have a pool with 8 TiB of available storage space then you should use 10 GiB of memory for the ARC.
ZFS also enforces a minimum value of 64 MiB.
[...]
То есть, если много-много терабайт на диске в zpool и при этом выставить ARC минимального размера - все будет тормозить и по arcstat и arc_summary будут видны конкретные показатели, что нет так, в чем cache miss. И root cause этих проблем с производительностью в том, что не хватает размера ARC для быстрой работы файловой системы.
это легко проверить, позапускав бенчмарки, например, fio и посмотрев когда получается выше производительность.
По умолчанию - "ZFS uses 50 % of the host memory for the Adaptive Replacement Cache (ARC) by default" и это положительно сказывается на производительности сервера, потому что - как правило - работа с RAM идет быстрее, чем работа операций ввода/вывода напрямую с установленными в сервере HDD/SSD/NVMe накопителями в обход ARC.
И только в очень специфической ситуации - как исключение из правила - когда в сервере установлено много очень быстрых NVMe - только тогда ARC оказывается "бутылочным горлышком", замедляет работу файловой системы и целесообразно будет ARC отключать, чтобы в результате получить быстрее работающую файловую систему.
Dexex
перезагрузка после паники ядра отключена ?
Да:
root@S04:~# cat /proc/sys/kernel/panic
0
и если мы видим перезагруженный сервер в данном случае, то это должно быть аппаратная проблема.
Не объясняет, почему при уменьшении количества запущенных нод перезагрузки становятся реже (и даже совсем пропадают при количестве нод примерно менее половины).
Не говоря о том, что аптайм до апгрейда был несколько месяцев в полной загрузке.
И вообще исходный вопрос был: чем так интенсивно занимаются arc_prune и arc_evict при primarycache=none на всех датасетах и как этого избежать.
если автоматическая перезагрузка сервера в случае kernel panic отключена и при этом сервер все таки самопроизвольно перезагружается - это практически 100% говорит об аппаратной проблемы сервера.
а если проблема аппаратная - то никакими настройками размера ARC эту проблему исправить не получится.
Да диски у меня сыпались. Но zfs крашила систему своим sd_sync, txd_sync и т.д. Вот в чем печаль. В таких случаях ничего не остаётся, кроме как сохранять данные, пока оно не повесили систему и полностью заменять диски на исправные. Создавать тупо пул и вливать назад. Я целый день потерял пытаясь сделать реплейс.
Dexex
Так что по поводу обслуживания пула все очень не надёжно как по мне. Полгода до этого работал неплохо.
Dexex
Ну и второе это hdd. Hdd - гавно. Любой ссд лучше любого hdd, кроме самых дешманских паленок. Практика это доказала.
Dexex
Моему wd gold всего два года - а он посыпался в зюзю. Никаких нагрузок ему не давали больших.
Dexex
2тб SSD стоит уже 7к. Только в видео регистраторы ещё можно ставить хдд. Больше - никогда принципиально не буду ставить хоть какие они!
Станислав
Моему wd gold всего два года - а он посыпался в зюзю. Никаких нагрузок ему не давали больших.
Кто хочет может в меня плеваться, но есть у меня приличный опыт (сотнями) взаимодействия с вдшками и сигейтами не из энтерпрайза и вывод один - они дерьмо.
Dexex
Кто хочет может в меня плеваться, но есть у меня приличный опыт (сотнями) взаимодействия с вдшками и сигейтами не из энтерпрайза и вывод один - они дерьмо.
Абсолютно одинаковое фуфло. Такое впечатление, что они все бу. Год максимум и пипец. Только если линейно писать вроде живые.
Dexex
Два стояли ну вы видели. Сеагейты грины нулевые абсолютно. Полгода и кряк
Станислав
Мне очень нравились ребята, которые на серверах (чаще терминальные) в зеркало WD черные, мониторинг не настраивали, а через год их приносили на восстановление. Оказывается один сдох через пол года, второй через год))
Станислав
Абсолютно одинаковое фуфло. Такое впечатление, что они все бу. Год максимум и пипец. Только если линейно писать вроде живые.
Абсолютно верно. Товарищи собирали на голубых ВД сервера под видеонаблюдение - всего несколько штук из пары сотен умерли за 5-6 лет
Dexex
Абсолютно верно. Товарищи собирали на голубых ВД сервера под видеонаблюдение - всего несколько штук из пары сотен умерли за 5-6 лет
Ага. Ваще необъяснимое явление. Как нагрузил какую то базу или ещё что - они прям на глазах заканчиваются. В виделрегиках лол по 3 года стоят - живые ничо...
Nikita
У меня WD Blue у пользователей стоят вторым диском по 10+ лет. В серверах Gold и в последнее время HC 310 также по 10 лет 24х7 бегают. Бывает, что дохнут, но не массово и "предупреждают" об этом заранее.
Hennadii
Да диски у меня сыпались. Но zfs крашила систему своим sd_sync, txd_sync и т.д. Вот в чем печаль. В таких случаях ничего не остаётся, кроме как сохранять данные, пока оно не повесили систему и полностью заменять диски на исправные. Создавать тупо пул и вливать назад. Я целый день потерял пытаясь сделать реплейс.
у меня еще ни разу не было проблем с zpool replace в серверах где стоит много HDD в режиме RAIDZ2 - все эти HDD всегда использовал в режиме "whole disk", так что замена в zpool сбойного диска на новый - всегда была тривиальной операцией, всего одной командой.
А что надо сделать для того, чтобы вызвать kernel panic в процессе выполнения команды zpool replace ?
В какой именно версии zfs команда zpool replace на Вашем компьютере вызывает kernel panic в sd_sync / txd_sync ?
Выполнять эту команду на сервере надо уже после того, как сбойный HDD заменен на новый.
когда надо получить большое по объему хранилище на много терабайт - тогда именно сервера с HDD будут самым целесообразным выбором, если эти HDD собирать в RAIDZ2 vdev, чтобы получить избыточность и защиту данных.
Если у Вас там все часто сыпется и глючит постоянно - может быть там память без ECC, и Memtest86+ смог бы помочь найти выявить проблемы? Если запустить его на ночь или на несколько суток. При использовании zfs рекомендуется, чтобы память была ECC, потому что, как я понимаю, глючная память может привести к серьезным разрушениям файловой системы zfs, так что потом ее будет или очень трудно или вообще невозможно восстановить.
да, файловая система zfs не является идеальной и у нее много недостатков, но для очень большого количества применений - на текущий момент она является наилучшим выбором, если нужна сохранность данных - если использовать вариант zfs из стабильного репозитория, а не из тестового репозитория zfs-testing.
для целого класса задач именно zfs будет наилучшим выбором, потому что ближайшие аналоги и конкуренты - btrfs и bcachefs оказываются еще менее стабильными и еще менее надежными. Возможно в будущем ситуация изменится, но пока что я сколько не искал - не смог найти лучшего варианта файловой системы, чем zfs.
Или я что-то пропустил и уже появилась какая-то новая файловая система, которая лучше, чем OpenZFS?
Ivan
 Vladislav
Vladislav
Ляпота какая
Vladislav
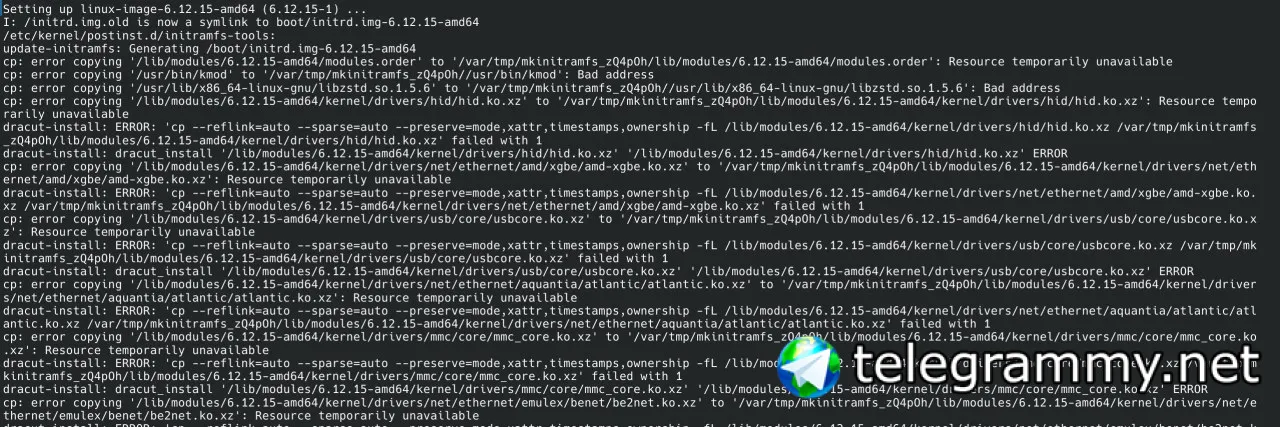
Это тянет на issue
Vladislav
DirectIO на самом деле очень много ждали, но итог очень узконаправленный
БД
и
ВМ
Dexex
Да диски у меня сыпались. Но zfs крашила систему своим sd_sync, txd_sync и т.д. Вот в чем печаль. В таких случаях ничего не остаётся, кроме как сохранять данные, пока оно не повесили систему и полностью заменять диски на исправные. Создавать тупо пул и вливать назад. Я целый день потерял пытаясь сделать реплейс.
у меня еще ни разу не было проблем с zpool replace в серверах где стоит много HDD в режиме RAIDZ2 - все эти HDD всегда использовал в режиме "whole disk", так что замена в zpool сбойного диска на новый - всегда была тривиальной операцией, всего одной командой.
А что надо сделать для того, чтобы вызвать kernel panic в процессе выполнения команды zpool replace ?
В какой именно версии zfs команда zpool replace на Вашем компьютере вызывает kernel panic в sd_sync / txd_sync ?
Выполнять эту команду на сервере надо уже после того, как сбойный HDD заменен на новый.
когда надо получить большое по объему хранилище на много терабайт - тогда именно сервера с HDD будут самым целесообразным выбором, если эти HDD собирать в RAIDZ2 vdev, чтобы получить избыточность и защиту данных.
Если у Вас там все часто сыпется и глючит постоянно - может быть там память без ECC, и Memtest86+ смог бы помочь найти выявить проблемы? Если запустить его на ночь или на несколько суток. При использовании zfs рекомендуется, чтобы память была ECC, потому что, как я понимаю, глючная память может привести к серьезным разрушениям файловой системы zfs, так что потом ее будет или очень трудно или вообще невозможно восстановить.
да, файловая система zfs не является идеальной и у нее много недостатков, но для очень большого количества применений - на текущий момент она является наилучшим выбором, если нужна сохранность данных - если использовать вариант zfs из стабильного репозитория, а не из тестового репозитория zfs-testing.
для целого класса задач именно zfs будет наилучшим выбором, потому что ближайшие аналоги и конкуренты - btrfs и bcachefs оказываются еще менее стабильными и еще менее надежными. Возможно в будущем ситуация изменится, но пока что я сколько не искал - не смог найти лучшего варианта файловой системы, чем zfs.
Или я что-то пропустил и уже появилась какая-то новая файловая система, которая лучше, чем OpenZFS?
Про zpool replace вообще скажу, что концепт замены совершенно отсталый. Если я изначально не по id сделал, то возникает путаница. Например у меня был диск, который я поставил на замены, а потом передумал - теперь у меня висит старый id не понятно чего was "такой то" и рядом идет ресилвер нового. Абсолютно не логично. А логично было бы, чтобы zfs записывала свои собственные id в пулах и сама ими рулила. Как например в mdadm, пофиг какая там буква - он его найдет, если они местами поменяются и массив заработает.