перезагрузка после паники ядра отключена ?
Да:
root@S04:~# cat /proc/sys/kernel/panic
0
 Free
Free


 Ivan
Ivan
Да:
root@S04:~# cat /proc/sys/kernel/panic
0
и если мы видим перезагруженный сервер в данном случае, то это должно быть аппаратная проблема.
Free
и если мы видим перезагруженный сервер в данном случае, то это должно быть аппаратная проблема.
Не объясняет, почему при уменьшении количества запущенных нод перезагрузки становятся реже (и даже совсем пропадают при количестве нод примерно менее половины).
Не говоря о том, что аптайм до апгрейда был несколько месяцев в полной загрузке.
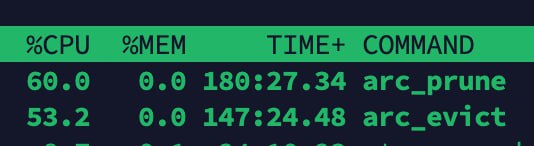
И вообще исходный вопрос был: чем так интенсивно занимаются arc_prune и arc_evict при primarycache=none на всех датасетах и как этого избежать.
Ivan
Не объясняет, почему при уменьшении количества запущенных нод перезагрузки становятся реже (и даже совсем пропадают при количестве нод примерно менее половины).
Не говоря о том, что аптайм до апгрейда был несколько месяцев в полной загрузке.
И вообще исходный вопрос был: чем так интенсивно занимаются arc_prune и arc_evict при primarycache=none на всех датасетах и как этого избежать.
ну сделайте даунгрейд и надейтесь что нагрузка станет меньше.
 Vladislav
Vladislav
Как вариант открыть issue на Гите
Vladislav
https://github.com/openzfs/zfs/pull/17065
Vladislav
Тут спрашивали почему использовать кэш плохо
Vladislav
Так вот
Vladislav
ZFS игнорирует ошибки flush (потому что изначально не предназначено, что они будут ему поступать)
Free
ну сделайте даунгрейд и надейтесь что нагрузка станет меньше.
Нагрузка от storj не уменьшится.
А иногда будет и увеличиваться (было уже так несколько месяцев назад когда разработчики проводили нагрузочное тестирование).
Вопрос в том, как заставить zfs не пытаться при этом всё в кэш упихивать, даже если мне это не требуется (когда от storj идут массовые загрузки для долгого хранения)
 Alexey
Alexey
Нагрузка от storj не уменьшится.
А иногда будет и увеличиваться (было уже так несколько месяцев назад когда разработчики проводили нагрузочное тестирование).
Вопрос в том, как заставить zfs не пытаться при этом всё в кэш упихивать, даже если мне это не требуется (когда от storj идут массовые загрузки для долгого хранения)
проведите тестирование памяти.
постепенно отключайте пулы, чтобы выявить на каком будут отчетливые изменения.
и в обратную сторону, подключайте постепенно пулы, что понять на каком начинает глючить.
Alexey
Arc Вам наоборот снижает нагрузку ввода-вывода на диски...
Free
проведите тестирование памяти.
постепенно отключайте пулы, чтобы выявить на каком будут отчетливые изменения.
и в обратную сторону, подключайте постепенно пулы, что понять на каком начинает глючить.
Примерно так делаю.
Вот сейчас аптайм 6 часов уже, осталось 10 нод из 60 запустить.
Сейчас процессы arc по 40-50% отжирают.
При критическом увеличении начнутся перезагрузки, поэтому постепенно добавляю
 Artem
Free
Artem
Free
Arc Вам наоборот снижает нагрузку ввода-вывода на диски...
Этого я разумом не понимаю.
Storj читает то, что давным давно записал.
Загрузку дисков он не уменьшит.
А вот процессор перегружает
Alexey
Каждый раз, когда идет обращение на чтение к диску, zfs проверяет есть ли запрашиваемые данные в arc. Если есть, то они из arc берутся, с диска не читается.
Alexey
Если данные пишутся на диск, то они тоже попадают в arc.
Alexey
Данные из arc "вымываются" по хитрому алгоритму. Если данные часто запрашиваются, то они "живут" в arc долго.
Free
Данные из arc "вымываются" по хитрому алгоритму. Если данные часто запрашиваются, то они "живут" в arc долго.
Одно и то же два раза не запрашивается.
Это ведь как бекап.
Вот сделали вы бекап, зачем его в памяти хранить, пока вам восстановление из бекапа не потребуется?
А вот эти процессы непрерывного "вымывания", как видно, процессор перегружают
Alexey
если есть память zfs ее использует. Она "не знает", что у Вас за данные: бэкап или виртуалки....
Free
если есть память zfs ее использует. Она "не знает", что у Вас за данные: бэкап или виртуалки....
Память мне не жалко.
Пусть использует.
Но когда она процессор этим вымыванием насилует до зависаний/перезагрузки - мне хочется это отключить.
Но не получается
Alexey
нет-нет. процессор не насилуется записью в память и чтением. Нагрузка может быть из-за например сильного сжатия данных при записи. Тогда да... Может быть занято ядром при записи из-за например того, что диск тупит и iowait висит.
Alexey
у Вас случаем не gzip-9 сжатие настроено?
Alexey
у меня была ситуация на паре серверов на дисках samsung 860 pro. Диски замирают, на них не возможно что-либо записать, считать. iowaite под 100%, система висит, кроме zabbix
Alexey
это быстрый метод сжатия, быстрее только lzo, но он сжимает очень просто и быстро
Free
нет-нет. процессор не насилуется записью в память и чтением. Нагрузка может быть из-за например сильного сжатия данных при записи. Тогда да... Может быть занято ядром при записи из-за например того, что диск тупит и iowait висит.
 Vladislav
Vladislav
Vladislav
Vladislav
Вообще, поставь metadata only и дай ему хотя бы гигов 16
Alexey
не знаю, я бы вернул настройки в значения по-умолчанию. Затем отключил бы все пулы. Убедился, что эти процессы не занимают проц. (что с оборудованием и ос все в порядке.) Затем подключал бы каждый пул и смотрел на каком будет проявляться симптом.
Free
Вообще, поставь metadata only и дай ему хотя бы гигов 16
Да я даже none ставил - никакого толку.
Память он сейчас по дефолту (как Георгий рекомендовал) 32 взял
Vladislav
Free
не знаю, я бы вернул настройки в значения по-умолчанию. Затем отключил бы все пулы. Убедился, что эти процессы не занимают проц. (что с оборудованием и ос все в порядке.) Затем подключал бы каждый пул и смотрел на каком будет проявляться симптом.
Так и сделал.
Но там не на конкретном пуле проявляется, а постепенно на количестве
Alexey
если не интересно разобраться, то можно все снести, переустановить Ос, zfs, пересоздать пулы и наблюдать. Если будут проблемы, то это железо...
Vladislav
Vladislav
Никак не отменяет это
Alexey
только на одной ноде?
Alexey
так не делается: "а давайте сделаем что-то, посмотрим, что будет...". Нужно ожидать какого-либо результата, простите за нравоучения...
Alexey
Вы вроде писали, что у Вас несколько таких серверов? Или я путаю?
Alexey
у Вас ядро 6.12... по умолчанию стоит 6.1.0...
Free
Как я понял только на одной, которую обновили до свежей версии
Нет, контейнеры нод вообще автоматически обновляются довольно часто.
Я там по другим причинам общий upgrade сделал.
Сейчас склоняюсь к тому, что не само обновление виновато, а факт одновременногоо запуска всех нод после обновления.
У них в самом начале более интенсивная работа с диском, чем в "крейсерском" режиме.
Надеюсь, если без перезагрузки сейчас обойдется плавное подключение - то потом снова будет многомесячный крейсерский режим
Alexey
это ядро находится в backports
Free
Вы вроде писали, что у Вас несколько таких серверов? Или я путаю?
Да, 4 сервера и 2 десктопа.
Все на днях обновил одновременно
Alexey
Вы вручную установили ядро из backports?
Alexey
Да, 4 сервера и 2 десктопа.
Все на днях обновил одновременно
а проблема проявляется на одном, ели я правильно понял?
Free
а проблема проявляется на одном, ели я правильно понял?
да
Возможно, потому что на других дисков и нод меньше
Alexey
нет из backports нужно вручную ядро поставить
Alexey
какие ядра на остальных серверах?
Free
нет из backports нужно вручную ядро поставить
На этом сервере (в отличие от остальных) непосредственно после апгрейда появилось сообщение
The ZFS modules cannot be auto-loaded.
Try running 'modprobe zfs' as root to manually load them.
что я и сделал.
Остальное - upgrade автоматом
Free
А, вот еще было
E: dpkg was interrupted, you must manually run 'dpkg --configure -a' to correct the problem.
Что тоже сделал руками
Alexey
если сомневаетесь, что правильно скомпелировались модули zfs, то можно их перекомпелировать:
dpkg-reconfigure zfs-dkms
update-initramfs -u -k all
update-grub
reboot
Alexey
но это мало вероятно...
Alexey
а что с версией ядра на остальных серверах?
Free
какие ядра на остальных серверах?
Посмотрю попозже.
Хотя вот что:
Остальные я не перегружал - значит, у них сейчас покажет старое ядро ведь?
А перегружать сейчас я уже не рискну, чтобы не спровоцировать такие же проблемы, как на этом
Alexey
посмотрите какие ядра:
ls -l /boot
Alexey
текущее ядро
uname -a
Vladislav
Vladislav
Найти бы только эту ситуацию, у меня была такая на arm бордах после обновления ядра. Обычно это значит, что у тебя криво ядро/хедеры встали и dkms не смог нормально собрать
Free
посмотрите какие ядра:
ls -l /boot
На остальных серверах всё гораздо старше.
Где-то 6.1, а где-то даже 5.10.
Сейчас вспоминаю:
На днях то я везде только автоматом обнавлялся, а на этом сервере несколько месяцев назад, действительно, вручную собирал.
В связи с другой проблемой, связанной со storj.
Alexey
По умолчанию ядро для debian12.9 6.1.0
Alexey
Это может не сильно важно, но стоит наверное привести к стандарту
Free
Это может не сильно важно, но стоит наверное привести к стандарту
 Dexex
Dexex
Здорово всем. Ну вот и наступил у меня полный кринж. pool читаемый, но txg_sync просто фризится.
Dexex
 Dexex
Dexex
[Ср фев 19 13:15:35 2025] INFO: task zfs:7334 blocked for more than 1087 seconds.
[Ср фев 19 13:15:35 2025] Tainted: P IOE 6.1.0-31-amd64 #1 Debian 6.1.128-1
[Ср фев 19 13:15:35 2025] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[Ср фев 19 13:15:35 2025] task:zfs state:D stack:0 pid:7334 ppid:1 flags:0x00004002
[Ср фев 19 13:15:35 2025] Call Trace:
[Ср фев 19 13:15:35 2025] <TASK>
[Ср фев 19 13:15:35 2025] __schedule+0x34d/0x9e0
[Ср фев 19 13:15:35 2025] schedule+0x5a/0xd0
[Ср фев 19 13:15:35 2025] io_schedule+0x42/0x70
[Ср фев 19 13:15:35 2025] cv_wait_common+0xaa/0x130 [spl]
[Ср фев 19 13:15:35 2025] ? cpuusage_read+0x10/0x10
[Ср фев 19 13:15:35 2025] txg_wait_synced_impl+0xcb/0x110 [zfs]
[Ср фев 19 13:15:35 2025] txg_wait_synced+0xc/0x40 [zfs]
[Ср фев 19 13:15:35 2025] zil_replay+0x103/0x140 [zfs]
[Ср фев 19 13:15:35 2025] zfsvfs_setup+0x204/0x240 [zfs]
[Ср фев 19 13:15:35 2025] zfs_domount+0x425/0x570 [zfs]
[Ср фев 19 13:15:35 2025] ? register_shrinker_prepared+0x35/0x70
[Ср фев 19 13:15:35 2025] ? mutex_lock+0xe/0x30
[Ср фев 19 13:15:35 2025] zpl_mount+0x16d/0x1d0 [zfs]
[Ср фев 19 13:15:35 2025] legacy_get_tree+0x27/0x50
[Ср фев 19 13:15:35 2025] vfs_get_tree+0x25/0xc0
[Ср фев 19 13:15:35 2025] path_mount+0x47a/0xa90
[Ср фев 19 13:15:35 2025] __x64_sys_mount+0x116/0x150
[Ср фев 19 13:15:35 2025] do_syscall_64+0x55/0xb0
[Ср фев 19 13:15:35 2025] ? set_shrinker_bit+0x29/0x60
[Ср фев 19 13:15:35 2025] ? list_lru_add+0xf0/0x1a0
[Ср фев 19 13:15:35 2025] ? _copy_to_user+0x21/0x30
[Ср фев 19 13:15:35 2025] ? cp_new_stat+0x135/0x170
[Ср фев 19 13:15:35 2025] ? __rseq_handle_notify_resume+0xa9/0x4a0
[Ср фев 19 13:15:35 2025] ? __do_sys_newfstatat+0x4e/0x80
[Ср фев 19 13:15:35 2025] ? switch_fpu_return+0x4c/0xd0
[Ср фев 19 13:15:35 2025] ? exit_to_user_mode_prepare+0x14b/0x1e0
[Ср фев 19 13:15:35 2025] ? syscall_exit_to_user_mode+0x1e/0x40
[Ср фев 19 13:15:35 2025] ? do_syscall_64+0x61/0xb0
[Ср фев 19 13:15:35 2025] ? exit_to_user_mode_prepare+0x40/0x1e0
[Ср фев 19 13:15:35 2025] ? syscall_exit_to_user_mode+0x1e/0x40
[Ср фев 19 13:15:35 2025] ? do_syscall_64+0x61/0xb0
[Ср фев 19 13:15:35 2025] ? exit_to_user_mode_prepare+0x40/0x1e0
[Ср фев 19 13:15:35 2025] ? syscall_exit_to_user_mode+0x1e/0x40
[Ср фев 19 13:15:35 2025] ? do_syscall_64+0x61/0xb0
[Ср фев 19 13:15:35 2025] ? do_user_addr_fault+0x1b0/0x550
[Ср фев 19 13:15:35 2025] ? exit_to_user_mode_prepare+0x40/0x1e0
[Ср фев 19 13:15:35 2025] entry_SYSCALL_64_after_hwframe+0x6e/0xd8
Dexex
Такие вот сюрпризы^^
Dexex
Идет resilvering вообще. Заменяю два диска на ssd из массива на 4х RAIDZ2
Dexex
 Dexex
Dexex
И вот чешу репу, а че делать то?
Dexex
У меня фишка в том, что на моей матери многие диски постоянно меняют буквы.
Dexex
И еще проблема в том, что zfs собака такая грузится ДО networking. Я в import.service поставил грузится перед самбой. Надеюсь в случае перезагрузки оно загрузится. Если честно это полная шляпа которую не понятно кто так сделал, ведь это же тупо грузить импорт ДО появления управления.
Vladislav
И еще проблема в том, что zfs собака такая грузится ДО networking. Я в import.service поставил грузится перед самбой. Надеюсь в случае перезагрузки оно загрузится. Если честно это полная шляпа которую не понятно кто так сделал, ведь это же тупо грузить импорт ДО появления управления.
Самба к ZFS не имеет никакого отношения
Dexex
Я загружен сейчас из рековер
Vladislav
И еще проблема в том, что zfs собака такая грузится ДО networking. Я в import.service поставил грузится перед самбой. Надеюсь в случае перезагрузки оно загрузится. Если честно это полная шляпа которую не понятно кто так сделал, ведь это же тупо грузить импорт ДО появления управления.
Логично, потому что сперва надо импортнуть пулы
Vladislav
Ты же корень ФС не грузишь после сети?