 Vladislav
Vladislav


 Nikolay
Nikolay
Я боюсь не настолько хорошо знаком с проксом, но почему у тебя в гостевой ОС ТЕЖЕ диски, что в самом проксе?
это контейнер потому что, они там видны.
Nikolay
а контейнеры свою фс на датасетах располагают
Vladislav
это контейнер потому что, они там видны.
Я правильно сейчас понимаю, контейнер с БД располагается на ZFS и это всё работает на гипервизоре?
Nikolay
 Vladislav
Vladislav
Ладно, тогда действительно подход о котором я думал не сработает
Nikolay
Толлько я не знаю виновата тут БД или нет. просто предположение.
Vladislav
special vdev вы сами разбили на две партиции или он сам таким оказался?
Nikolay
special vdev вы сами разбили на две партиции или он сам таким оказался?
сам. там ещё лог лежит
Vladislav
Ну, два, но Вы меня поняли, логически один
Vladislav
Или ты кидал уже zpool status?
Vladislav
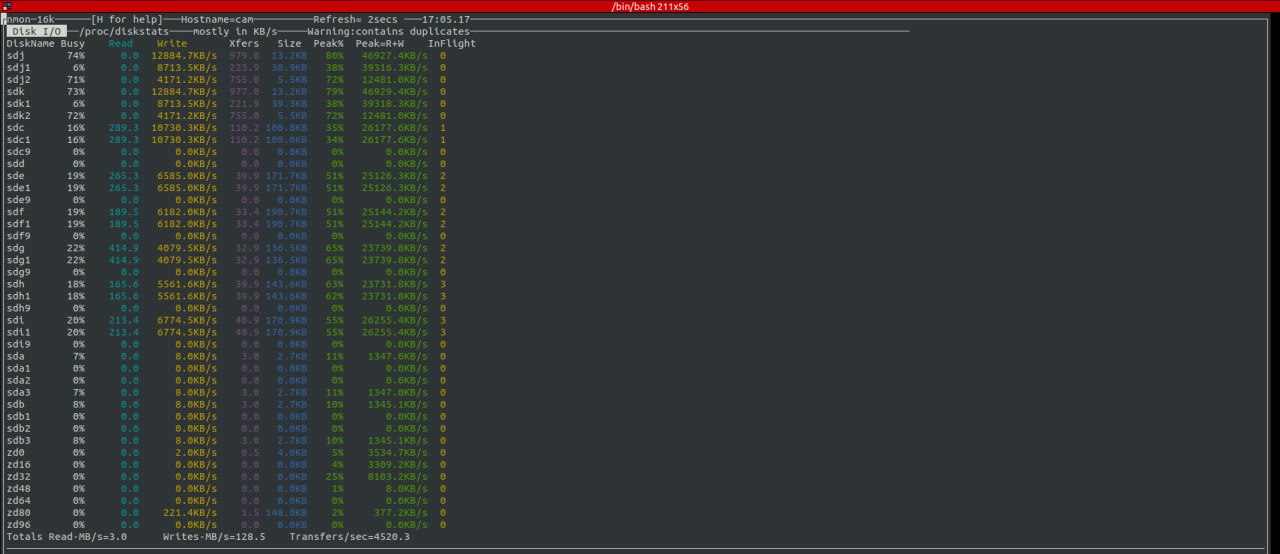
У тебя запись на сами диски идёт, поэтому логично, что slog и special vdev тоже страдают
Vladislav
slog в большой степени
Vladislav
55%
Vladislav
Ибо записи синхронные
Vladislav
Попробуй fatrace или blktrace
Vladislav
 Vladislav
Vladislav
https://sysadmin.pm/fatrace/
Nikolay
Ибо записи синхронные
там синхронных не больше 10 Мб/с , это же смешная нагрузка и кол-во операций 300-400, а на спешиал по 2000 падает на каждый =\
Vladislav
Nikolay
10МБ/с, блоками по 4к
т.е. если я перенесу базу данных (к примеру) которая пишет по 4к, на датасет 16к, а текущий был 128к, то нагрузка должна упасть на 128/16=8 раз ?
Nikolay
извиняюсь если туплю. Мозги уже парятся
 Станислав
Станислав
т.е. если я перенесу базу данных (к примеру) которая пишет по 4к, на датасет 16к, а текущий был 128к, то нагрузка должна упасть на 128/16=8 раз ?
Немного запутался во всем, что выше написано. Я правльно понимаю, что вы расположили БД в датасете с 128 рекордсайзом?
Nikolay
Немного запутался во всем, что выше написано. Я правльно понимаю, что вы расположили БД в датасете с 128 рекордсайзом?
Изначальная проблема: высокая нагрузка на спешиал, хотя вроде как никто не создаёт такой нагрузки.
Станислав
Nikolay
Немного запутался во всем, что выше написано. Я правльно понимаю, что вы расположили БД в датасете с 128 рекордсайзом?
да, штуки 3, но есть и большая база, под 600 Гб
Vladislav
#Вопрос: А правильно ли понимаю: Вот вывод команды: zpool iostat -r 5 https://pastebin.com/raw/af28ZRGF
Что по факту у меня гостевые ОС пишут в большинстве своём 4К и 8К блоками ? При ashift=13 у меня программный размер блока 4К и диски тоже по 4К.
Получается вмместо одного блока 4К записи на диск, при record_size=128K , пишется 128/4=32 блока на диск. Нагрузка на пул больше, НО влияет ли это кол-во записей в special vdev ? По идее же нет, туда пишется инфа про ОДИН 128К сектор, а не 32 раза про 4К сектора ? Т.е. неподходящий размер блока не будет же увеличивать нагрузку на special vdev ? Спасибо
1) у тебя нагрузка не на special vdev идёт, а на SLOG
2) recordsize определяет максимальный размер чтения и записи за раз, округляя до ahift, меньше чем ashift он считать не может.
Т.е. если система хочет считать 129КБ, она считает 128КБ и 128КБ двумя разными запросам. Но, если файлик 2КБ, то ZFS всё равно в итоге будет читать 4КБ, но использовать recordsize < ashift идея нездравая, поэтому мы не будем продолжать про это.
Теперь сложно (это вроде раньше обсуждалось)
Дальше
Чтение проще всего будет описать (ни одной части файла нет в ARC, потому что это ещё один уровень был бы)
Мы хотим прочитать Файл 1024КБ
Для этого ФС ZFS запрашивает 8 блоков по 128КБ у "виртуального диска" ZFS (тут есть умный термин, который я не знаю)
Виртуальный диск делит эти блоки по 128КБ на 32 запроса по 4к
Дальше каждый запрос по 4к бьётся уже самой ОС (при общении с блочным устройством) на блоки по 512
А уже контроллер диска считывает сектор на 4к и смотрит попадают ли туда все наши блоки по 512
Ещё от recordsize зависит размер меты, то есть чем они ниже, тем больше меты нужно (потому что мета идёт на recordsize)
А вот по записи...
ZFS всегда читает и пишет по размеру recordsize (исключение, если файл занимает меньше, чем 1 recordsize, но файл БД занимает однозначно больше), по этой причине рекомендуется ставить для Базы Данных recordsize = 1 IO БД
Таким образом одна запись со стороны БД на 4к, меняет весь блок на 128КБ и заставляет перезаписать его.
Но важно отметить, что это никак не связано с SLOG. SLOG хранит в себе группы транзакций, А не весь блок, то есть
Пришла транзакция (TX, I/O запрос) на запись 8КБ.
Она попадает в SLOG и оперативную память.
ZFS объединяет их скопом (транзакции TX) до TGX (транзакционная группа) и так пока не дойдёт до размера dirty_bytes_max или tgx_timeout (2с или 5с по умолчанию), потому начинает уже процесс записи с чтением и записью новых блоков, но если питание пропадёт, то при запуске ZFS увидит, что в SLOG всё ещё лежит эта синхронная запись и начнёт заново весь процесс
Vladislav
Вроде я нигде не проебался, но это не точно
Vladislav
#Вопрос: А правильно ли понимаю: Вот вывод команды: zpool iostat -r 5 https://pastebin.com/raw/af28ZRGF
Что по факту у меня гостевые ОС пишут в большинстве своём 4К и 8К блоками ? При ashift=13 у меня программный размер блока 4К и диски тоже по 4К.
Получается вмместо одного блока 4К записи на диск, при record_size=128K , пишется 128/4=32 блока на диск. Нагрузка на пул больше, НО влияет ли это кол-во записей в special vdev ? По идее же нет, туда пишется инфа про ОДИН 128К сектор, а не 32 раза про 4К сектора ? Т.е. неподходящий размер блока не будет же увеличивать нагрузку на special vdev ? Спасибо
Если tl;dr твоя проблема не должна быть связана с recordsize, потому что он создаёт нагрузку на диски и объём special vdev, но никак не на SLOG
Vladislav
Вроде я нигде не проебался, но это не точно
О, точно у нас же есть двое что читали книгу про ZFS
@ialebedev
Ты ведь сообщал, что дохуя теперь знаешь и читал книгу. Так приди и помоги коммьюнити, не только же пользоваться его услугами
Vladislav
Опиши человеку как работает запись + транзакции в зависимости от recordsize и ashift и как с этим связан SLOG и Special vdev
 Ivan
Ivan
О, точно у нас же есть двое что читали книгу про ZFS
@ialebedev
Ты ведь сообщал, что дохуя теперь знаешь и читал книгу. Так приди и помоги коммьюнити, не только же пользоваться его услугами
Шарик, а ты кто )) ? Давай каждый будет решать сам, когда и кто будет включаться. Это дело сугубо добровольное, и уж точно не тебе распределять роли тут.
Vladislav
Ну, я попытался, @morphoratorus, сорян, но люди которые читали умную книжку отказались помогать коммьюнити
Vladislav
Они предпочитают только пользоваться его услугами
 George
George
iostat https://pastebin.com/raw/zxqWkXFz
zpool iostat https://pastebin.com/raw/p7agyWN1
ну выглядит что синхронная запись идёт на special vdev вся
Nikita
Ну, я попытался, @morphoratorus, сорян, но люди которые читали умную книжку отказались помогать коммьюнити
у меня тоже есть эти умные книги, но я до них пока не добрался. могу дать почитать в Питере)
George
#Вопрос: А правильно ли понимаю: Вот вывод команды: zpool iostat -r 5 https://pastebin.com/raw/af28ZRGF
Что по факту у меня гостевые ОС пишут в большинстве своём 4К и 8К блоками ? При ashift=13 у меня программный размер блока 4К и диски тоже по 4К.
Получается вмместо одного блока 4К записи на диск, при record_size=128K , пишется 128/4=32 блока на диск. Нагрузка на пул больше, НО влияет ли это кол-во записей в special vdev ? По идее же нет, туда пишется инфа про ОДИН 128К сектор, а не 32 раза про 4К сектора ? Т.е. неподходящий размер блока не будет же увеличивать нагрузку на special vdev ? Спасибо
как раз хотел уточнить почему оно как вольюм по имени датасета выглядит. Да, внутри вмки 99% ФС юзает 8-16К блоки, плюс постгря сама пишет тоже много где 8-16к
Vladislav
George
если хочется немного улучшить жизнь - можно попробовать recordsize поменять на 16-32К и образ диска перекопировать (предварительно остановив контейнер), чтобы recordsize применился, но емнип zil итак должен дифф только писать и запись это не сильно уменьшит
Nikolay
ну выглядит что синхронная запись идёт на special vdev вся
Sync=standart, т.е. я ничего сделать с этим не могу ? Кроме как отдельные диски более производительные на лог поставить?
Vladislav
Sync=standart, т.е. я ничего сделать с этим не могу ? Кроме как отдельные диски более производительные на лог поставить?
Только понять, что у тебя делает sync запись в количестве 10МБ/с с блоком 4к
George
Sync=standart, т.е. я ничего сделать с этим не могу ? Кроме как отдельные диски более производительные на лог поставить?
попробовать исключить отдельную фс, потюнить под постгрю zfs https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/Workload%20Tuning.html#postgresql
George
но если хочется быструю постгрю, то да - slog
 Δαρθ
Δαρθ
если хочется немного улучшить жизнь - можно попробовать recordsize поменять на 16-32К и образ диска перекопировать (предварительно остановив контейнер), чтобы recordsize применился, но емнип zil итак должен дифф только писать и запись это не сильно уменьшит
В смысле, а что у зволов рекордсайз если поменять, то новые записи всё равно будут со старым?
 LordMerlin
LordMerlin
В смысле, а что у зволов рекордсайз если поменять, то новые записи всё равно будут со старым?
Новые с новым.
А старые надо переместить, чтобы с новым записались
George
В смысле, а что у зволов рекордсайз если поменять, то новые записи всё равно будут со старым?
у звола 1 блок = 1 запись грубо говоря, но емнип volblocksize и нельзя находу изменить.
У датасета рекордсайз статичен на файл, как только файл начал занимать больше 1 блока, то рекордсайз больше у него не изменится.
Δαρθ
Vladislav
В смысле, а что у зволов рекордсайз если поменять, то новые записи всё равно будут со старым?
zvol-м пофиг на recordsize
Vladislav
Я собственно был уверен в обратном, но тесты показали, что эти сущности независимы
 Sergey
Sergey
zvol-м пофиг на recordsize
блоки L0 zvol-а имеют размер volblocksize, это можно увидеть посредством zbd
Sergey
блоки L0 zvol-а имеют размер volblocksize, это можно увидеть посредством zbd
при записи в zvol блоком меньшим размера volblocksize попадаем на read-modify-write всего блока L0
Vladislav
Я же в своё время был уверен, что иерархия идёт как то, что zvol это часть датасета, и запись на zvol идёт как
zvolblocksize —> record size —> ashift
Сейчас я знаю, что это не так
 Алексей
Станислав
Алексей
Станислав
Нихрена себе ты проштрафился)))
Так ещё не верил, доказывал обратное и посылал проверить это))
Vladislav
Так и получил эти знания
 central
central
/report
 Vladislav
Vladislav
/report
 Free
Free
Не уследил - на одном пуле zfs данные всё место забили, 0B свободного.
Чтобы перенести датасет - снапшот не создается. Ну это понятно, его нужно записать куда-то.
Решил удалить что-нибудь ненужное, нашел такие файлы.
И тут вдруг:
rm /sea/320/storage/storage/garbage/ukf...
rm: cannot remove '/sea/320/storage/storage/garbage/ukf...': No space left on device
В интернетах советы не совсем подходящие, вроде увеличить квоту (у меня её нет) или добавить vdev (у меня raidz2, даже слотов для дополнительных 3+ дисков нет), есть совсем смешные вроде такой записи в файл, который хочешь удалить:
cat /dev/null > /file/to/delete
(естественно, для этого тоже no space left получается).
Говорят, проблема старая и известная.
Может, кто-то из старожилов знает решение? 🤔
Vladislav
А это уже интересно, ибо ZFS должен оставлять место на операции удаления файлов
Free
Вот я бы тоже от файловой системы резерв системный ожидал бы, ан нет 🤨
Free
А для букмарки место не потребуется 🤔?
Vladislav
dd if=/dev/null of='file path'