 Animal
Animal


и вообще когда делаю снап на таком системном пуле он их создает вообще или это "видимость" ? тк zfs lit -t snapshot в принципе показывает что снап существует
Станислав
и вообще когда делаю снап на таком системном пуле он их создает вообще или это "видимость" ? тк zfs lit -t snapshot в принципе показывает что снап существует
Импортируешь не раздел, а пул. Пул, вернее базовый датасет rpool, имеет точку монтирования по умолчанию, все датасеты отталкиваются от нее. Потому при загрузке с лайв сд импорт нужно сделать в другую исходную точку:
zpool import rpool -R /mnt
Иначе будет весело, так как монтирование пула в корень перекроет данные лайв сд.
Сейчас содержимое папки снепшотов можешь увидеть, если включишь видимость snapdir для rpool/ROOT/ubuntu
 LordMerlin
LordMerlin
А как же.. а как ... а ... ну ладно....
 Fedor
Fedor
Что в зфс нет стандартного механизма проверки и восстановления
потому как при соблюдении условий эксплуатации он там не нужен, наверное)
Fedor
все и так консистентно всегда
 George
George
Что в зфс нет стандартного механизма проверки и восстановления
а потом на ребуте 100+ТБ массива на каком-то ext4 сидим ждём fsck часами, который мало что может сам сделать
LordMerlin
Вы не понимаете. зато восстановить что-то можно))))))))))))))))))))))))))))
 Алексей
Алексей
Судя потому что у него на переднем плане wd green можно понять что у них за клиенты
Алексей
Какие 100тб вы о чём
LordMerlin
Как какие. Которые за нажатия в Рстудио платят десятки тыщщ
LordMerlin
У нас тут одно время кидалы акивничали. Компьютерные услуги.
Типа винда переустановить, продуть пыль, драйвера поставить...
ИТОГО с вас .... и рандом от 3 до 40 тыщ))))
 Вадим
Вадим
У нас тут одно время кидалы акивничали. Компьютерные услуги.
Типа винда переустановить, продуть пыль, драйвера поставить...
ИТОГО с вас .... и рандом от 3 до 40 тыщ))))
В сериале "Вампиры средней полосы" этот момент хорошо обыграли )
Вадим
Простите за оффтоп
https://www.youtube.com/watch?v=HMFHfbiOMGQ
Станислав
У нас тут одно время кидалы акивничали. Компьютерные услуги.
Типа винда переустановить, продуть пыль, драйвера поставить...
ИТОГО с вас .... и рандом от 3 до 40 тыщ))))
Почему одно время? Думаю ничего не изменилось.
Работал в этой сфере несколько лет, знаю как всё устроено😄 Зачастую я один таким кидаловом не занимался, а в некоторых организациях до 20 человек выездных было
LordMerlin
Вот и у нас оказалась организация такая.
Пока нормальные не собрались, не вызвали по вызову одного такого и не отпиздохали.
Потом в ментуру сдали и всю шайку накрыли.)))
Станислав
LordMerlin
Нет))
Pavel
добрый день, интересно мнение сообщества + пятничный холивар на тему https://www.youtube.com/watch?v=-_o7rjh6Co8
Так она же стандартная, и во FreeBSD по дефолту же, Денис совсем конфет объелся походу
Y
Как какие. Которые за нажатия в Рстудио платят десятки тыщщ
Как там Промакашка говорил? Этак и я так умею 😉
Y
Так она же стандартная, и во FreeBSD по дефолту же, Денис совсем конфет объелся походу
У него то что он не может ткнуть кнопку рековери в р-студио не стандартное
Y
Комрады, какие потери "на формат" у 10+2 против 8+2 (ashift=12)
George
Комрады, какие потери "на формат" у 10+2 против 8+2 (ashift=12)
https://openzfs.github.io/openzfs-docs/Basic%20Concepts/RAIDZ.html
см. таблицу ниже
 Art
Art
 Art
Art
 central
Art
Ivan
central
Art
Ivan
Один из уровней, производительный, объединяет 5 400 NVMe SSD, обеспечивающих ёмкость 11,5 Пбайт. Пиковые скорости чтения и записи информации достигают 10 Тбайт/с. Показатель IOPS (количество операций ввода/вывода в секунду) при произвольном чтении и записи превышает 2 млн. Второй уровень содержит 47 700 жёстких дисков (PMR). Их общая вместимость равна 679 Пбайт. Максимальная скорость чтения массива — 4,6 Тбайт/с, скорость записи — 5,5 Тбайт/с. В состав третьего уровня включены 480 устройств NVMe суммарной ёмкостью 10 Пбайт для работы с метаданными.
В целом, архитектура соответствует той, что была запланирована изначально. Однако теперь представитель ORNL подтвердил правильность выбранного гибридного подхода к хранению информации, отметив, что одна из выполняемых на суперкомпьютере задач генерирует 80 Пбайт в день и что ему не хотелось бы, чтобы из-за недостаточно быстрого хранилища столь мощная машина простаивала без дела.
интересно как посчитали максимальную скорость. это просто сумма каналов носителей или же то что реально может массив выдать ?
Art
интересно как посчитали максимальную скорость. это просто сумма каналов носителей или же то что реально может массив выдать ?
думаю второе, наверняка там целая команда тестами занимается
George
Самый мощный комп в мире использует ЗФС💪
Zfsonlinux появился когда-то с целью заменить под lustre ldiskfs, который являлся пропатченным ext3)
George
Ext4 многое из ldiskfs впитал)
George
интересно как посчитали максимальную скорость. это просто сумма каналов носителей или же то что реально может массив выдать ?
да, lustre умеет относительно горизонтально масштабироваться по хостам
George
Отсюда её плюсы и минусы)
Art
Zfsonlinux появился когда-то с целью заменить под lustre ldiskfs, который являлся пропатченным ext3)
я и слов таких не знаю), но сейчас гуглю - интересно
George
У lustre как раз надобность в больших пулах на одной ноде под нет, zfs оч много их проблем решает
George
и fsck на ребуте не будет часами фс восстанавливать
Art
У lustre как раз надобность в больших пулах на одной ноде под нет, zfs оч много их проблем решает
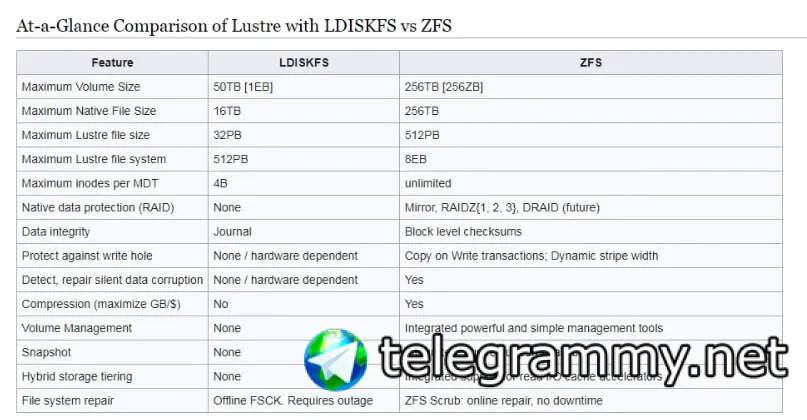 George
George
Draid тоже под люстру пилился с их большими пулами
 Alexander
Alexander
Главный минус lustre на zfs - оно медленнее, чем на ldiskfs. Особенно если приложение работает с маленькими блоками.
А про fsck (lfsck для lustre) правда, но в последних версиях его существенно ускорили, так что часами ждать не надо..
Y
в то время как гугл любит ехт4 без журналов
попробуй слей свой архив оттуда - у меня ошибка какая-то (от них) - типа не все данные могут быть восстановлены - проебали они моё
Fedor
 Михаил
Михаил
простой нубский вопрос
хочу в zfs raid10 добавить еще 2 диска
просто делаю zpool add %poolname% mirror sdX sdY
или еще какая магия нужна?
Ivan
интересно, а есть какие-то балансеры данных для случая когда к старому raid10 добавил дисков ?
Fedor
со временем распределится, если данные постоянно меняются
Fedor
если нет - только перезапись данных
George
простой нубский вопрос
хочу в zfs raid10 добавить еще 2 диска
просто делаю zpool add %poolname% mirror sdX sdY
или еще какая магия нужна?
проще всего поднять пул на файликах и поэкспериментировать, чтобы случайно ни в чём не ошибиться.
Технически да, raid10 расширяется добавлением мирроров
Михаил
George
даже виртуалка не обязательна, если что, но почему бы и нет
George
в тему non-ecc памяти с zfs - запостил несколько своих баек:) https://zfsonlinux.topicbox.com/groups/zfs-discuss/T7a9eefcf4ffcb321-Mc595bf3ea69d4369df0f5b53
 Artem
Artem
в тему non-ecc памяти с zfs - запостил несколько своих баек:) https://zfsonlinux.topicbox.com/groups/zfs-discuss/T7a9eefcf4ffcb321-Mc595bf3ea69d4369df0f5b53
Не fun "cases", а "fun" cases. Ну и сами проблемы с оверклокингом/недовольтажом - ну такое...
George
Не fun "cases", а "fun" cases. Ну и сами проблемы с оверклокингом/недовольтажом - ну такое...
Не, именно "cases", ибо да, дохлая память и издевательства над железом)
Y
R
простой нубский вопрос
хочу в zfs raid10 добавить еще 2 диска
просто делаю zpool add %poolname% mirror sdX sdY
или еще какая магия нужна?
Ничего больше не требуется для расширения
George
это типо выжила ZFSина ?
сам пул выживал, да, данные по понятным причинам новые ещё до zfs бились
Y
сам пул выживал, да, данные по понятным причинам новые ещё до zfs бились
хм... у меня таки данные записывались правильно, а вот читались нет , собственно я это заметил когда скопировал что-то нужно и решил хеш сверить - была ошибка, я даже файлы побайтово потом сравнивал - таки ошибка каждый раз в разных местах была...
только тогда решил на сам НАС лезть сомтреть что к чему...
плашку когда поменял - те файлы что записывал с битой таки оказались целыми (хеш сошелся)....
Y
Комрады, сколько в zfs-зеркале может быть максимум дисков ?
Y
Комрады, сколько в zfs-зеркале может быть максимум дисков ?
собственно почему спрашиваю - для special-vdev нужна избыточность не меньше чем у масива (иначе это будет точка отказа) - значит на RADIZ3 - надо зеркало из 4х дисков... такое можно ?
Fedor
собственно почему спрашиваю - для special-vdev нужна избыточность не меньше чем у масива (иначе это будет точка отказа) - значит на RADIZ3 - надо зеркало из 4х дисков... такое можно ?
Ты можешь проверить, создав тестовый пул на файлах.
Fedor
Там вроде куда больше двух можно
Алексей
Да куда уж больше
Alexandr
 Egor
Egor
подскажите, если мы создаём пул поверх gpt-раздела:
zpool create -o ashift=12
нам же не важно выравнен раздел для 4к или нет?
Egor
что-то только сейчас об этом задумался
central
Egor
Почему не должно быть важно?
https://groups.google.com/g/zfs-fuse/c/Dq5kZ6otWT8
здесь ответ нашёл (важно и смещение раздела и ashift zfs)
Egor
теперь вопрос: как я могу на линухе добавить к разделам gpt-метку и создать на них пул?
Egor
во FreeBSD и создание разделов и добавление метки делается с помощью gprart, в линухах какой-то бардак по-моему
 Shaker
Shaker
Да, некоторый бардак есть.
Shaker
Сам удивился, когда увидел, на разных хранилках, где-то есть разделы, а где-то нет.
Разные версии ZFS, и видно по команде
lsblk --output NAME,PARTUUID,FSTYPE,LABEL,UUID,SIZE,FSAVAIL,FSUSE%,MOUNTPOINT
что некоторые диски добавлены в zfs без разделов, хотя все делалось одним скриптом.
Fedor
Почти все современные фс выравнивание производят автоматом
Fedor
Вопрос, выровнен ли нижний слой, если диск виртуализирован
Shaker
Еще вопрос, какой он, идеальный cpu для 96 дисков в зеркале zfs + nfs ?
Ivan
Еще вопрос, какой он, идеальный cpu для 96 дисков в зеркале zfs + nfs ?
главное односокетную мать, производительность чем больше, тем лучше.
Shaker
Думаешь в частоте дело ?
Shaker
Все пишут , что нужно больше ядер
 Vladislav
Vladislav
Нет, односокетная мать потому что не нужно насиловать мозг с тем, что скорость падает из-за обращения памяти CPU2 к PCIe на CPU1
Georg🎞️🎥
Нет, односокетная мать потому что не нужно насиловать мозг с тем, что скорость падает из-за обращения памяти CPU2 к PCIe на CPU1
А на двух следовой 24 плашки ))