скорее там не ashift, а sector size другой, если конечно автор не задавал ashift явно
Ну не... секторсайз это атрибут файлосистемы, то бишь датасета, но никак не пула или вдева
 Art
Art


 Владимир
Владимир
Владимир
Владимир
 nikolay
nikolay
Именно ашифт
можно добавить диски с ss = 4к в пул где остальные диски с ss=512 , они добавятся в виде отдельного vdev, но удалить такой vdev не получится
Art
можно добавить диски с ss = 4к в пул где остальные диски с ss=512 , они добавятся в виде отдельного vdev, но удалить такой vdev не получится
Интересное кино... Как будто тупиковая ситуация?
@Wladimi ты как-нибудь выкрутился в итоге?)
Владимир
Интересное кино... Как будто тупиковая ситуация?
@Wladimi ты как-нибудь выкрутился в итоге?)
не, приспичит удалить прийдётся ОС переустанавливать))
nikolay
не, приспичит удалить прийдётся ОС переустанавливать))
ну ось переставлять это если системные разделы в таком пуле. пул надо разбирать, это факт
Владимир
ну ось переставлять это если системные разделы в таком пуле. пул надо разбирать, это факт
ну у меня там как раз системные разделы
Art
ну у меня там как раз системные разделы
Блин, попадос. Но что если:
Установить в сервер ещё дисков,
затем добавить их как зеркало (и с правильным ашифтом) к проблемному вдеву
Дождаться окончания ресильвера
Ну и выпилить диски плохого вдева из системы физически
Это наркомания, или я придумал дельное решение?
 Vladislav
Vladislav
Блин, попадос. Но что если:
Установить в сервер ещё дисков,
затем добавить их как зеркало (и с правильным ашифтом) к проблемному вдеву
Дождаться окончания ресильвера
Ну и выпилить диски плохого вдева из системы физически
Это наркомания, или я придумал дельное решение?
Мне приходилось пулы с неправильным ашифтом пересоздавать
Art
Мне приходилось пулы с неправильным ашифтом пересоздавать
Тут нестандартный кейс
Пул с системой был расширен зеркалом, но этот новый зеркальный вдев получился не с таким ашифтом, как у первого вдева
Vladislav
Тут нестандартный кейс
Пул с системой был расширен зеркалом, но этот новый зеркальный вдев получился не с таким ашифтом, как у первого вдева
Тут нет ничего нестандартного. Самый быстрый способ - пересоздать пул с правильными параметрами
Art
Тут нет ничего нестандартного. Самый быстрый способ - пересоздать пул с правильными параметрами
А если пул системный
или много данных содержит
или хочется без простоя выйти из положения...
По моему вариант с третьим вдевом таки прокатил бы... но просто боюсь дать вредный совет
Vladislav
Art
Тренируйся на файлах.
Имхо, не прокатит
О, кстати, это мысль, в стенде прогнать
@Wladimi скинь плз команду которой вдев добавил
 Aba
Aba
О, кстати, это мысль, в стенде прогнать
@Wladimi скинь плз команду которой вдев добавил
я ж выше скрин из мана кидал)
Владимир
О, кстати, это мысль, в стенде прогнать
@Wladimi скинь плз команду которой вдев добавил
через -o ашифт указал просто
 Александр
Станислав
Александр
Станислав
Привет всем, у меня тут снова глупый (теоретический) вопрос - имеем 2 корзины по 6 дисков, имеем два фуджиковских контроллера 9211-8i (по одному на корзину, IT режим), имеем raidz2 на обычных дисках (пока 6 штук, но планирую массив увеличить до 12 думаю), собственно вопрос - для ссд я понимаю ответ на него, а для обычных дисков - есть ли смысл раскидывать один пул из 6 дисков на 2 отдельных контроллера, или один вполне себе вытянет без проблем? (контроллеры подключены в PCI-e 2 x8, как положено) (я даже не столько про линейную пропускную способность, сколько про саму нагрузку на контроллер)
Art
Привет всем, у меня тут снова глупый (теоретический) вопрос - имеем 2 корзины по 6 дисков, имеем два фуджиковских контроллера 9211-8i (по одному на корзину, IT режим), имеем raidz2 на обычных дисках (пока 6 штук, но планирую массив увеличить до 12 думаю), собственно вопрос - для ссд я понимаю ответ на него, а для обычных дисков - есть ли смысл раскидывать один пул из 6 дисков на 2 отдельных контроллера, или один вполне себе вытянет без проблем? (контроллеры подключены в PCI-e 2 x8, как положено) (я даже не столько про линейную пропускную способность, сколько про саму нагрузку на контроллер)
У нас 9200-8e (проц у них тот же самый) тянут по 18 дисков вообще без проблем, причём там вперемешку SAS и SATA
Вытянуть HDD по нагрузке это вкдь изи задача. У этих контроллеров в спеках же вообщи сотни дисков указаны по моему)
Станислав
У нас 9200-8e (проц у них тот же самый) тянут по 18 дисков вообще без проблем, причём там вперемешку SAS и SATA
Вытянуть HDD по нагрузке это вкдь изи задача. У этих контроллеров в спеках же вообщи сотни дисков указаны по моему)
Да, там через рейзеры 256 указано, я тут реально малость лоханулся в цифрах) и понял уже после того как спросил) в спеках у него указано 600мб на порт, соответственно 4800мб на 8 прямых каналов, а псие 2 х8 даёт нам 4гб в секунду, но конкретно в моем случае даже теоретически выходит 3.6гб в секунду, это при использовании хороших ссд, условно - можно не париться)
Art
Да, там через рейзеры 256 указано, я тут реально малость лоханулся в цифрах) и понял уже после того как спросил) в спеках у него указано 600мб на порт, соответственно 4800мб на 8 прямых каналов, а псие 2 х8 даёт нам 4гб в секунду, но конкретно в моем случае даже теоретически выходит 3.6гб в секунду, это при использовании хороших ссд, условно - можно не париться)
Ага, получается узким местом HBA не станет👌 А если когда-нибудь ссд станет много, то уж тогда поменяешь на более современный, под псие 3.0
Станислав
Ага, получается узким местом HBA не станет👌 А если когда-нибудь ссд станет много, то уж тогда поменяешь на более современный, под псие 3.0
Я думаю мне раньше придётся поменять сервер) но жаба задушит меня тратить пару сотен тысяч рублей на новый, пока этот пашет) это все таки домашняя тестовая лаба, и файлопомойка в одном лице)
Art
Привет всем, у меня тут снова глупый (теоретический) вопрос - имеем 2 корзины по 6 дисков, имеем два фуджиковских контроллера 9211-8i (по одному на корзину, IT режим), имеем raidz2 на обычных дисках (пока 6 штук, но планирую массив увеличить до 12 думаю), собственно вопрос - для ссд я понимаю ответ на него, а для обычных дисков - есть ли смысл раскидывать один пул из 6 дисков на 2 отдельных контроллера, или один вполне себе вытянет без проблем? (контроллеры подключены в PCI-e 2 x8, как положено) (я даже не столько про линейную пропускную способность, сколько про саму нагрузку на контроллер)
Ну я и бы не стал раскидывать диски для пула по разным HBA... Не вижу смысла, один вред: падает контроллер, падает часть дисков пула, от чего пул может помереть навсегда, в теории
Хотя если вот делать зеркальные массивы, то вот тогда в принципе в двух контроллерах есть некоторый смысл
Станислав
Ну я вот тоже думал, что как раз когда все 12 дисков будут уже в массиве (я думаю сделать 2 raidz2 в страйпе), и как раз там раскидать каждую группу по 6 дисков на свой контроллер
Aba
Я думаю мне раньше придётся поменять сервер) но жаба задушит меня тратить пару сотен тысяч рублей на новый, пока этот пашет) это все таки домашняя тестовая лаба, и файлопомойка в одном лице)
Ну это ты загнул конечно) даже тримод можно за 20к взять
Станислав
Ну это ты загнул конечно) даже тримод можно за 20к взять
Просто у меня сейчас стоит supermicro x8 с парой x5675 и 96 оперативки (288макс)) я вот думаю, если менять, то уже на что-то современное, и цены там ппц просто) я оооочень дёшево утараканил эту материнскую плату, новую) а остальное уже бу кроме дисков и блока питания (насчёт контроллеров не уверен конечно, но не думаю что они прям новые)
Станислав
Мне этого то сейчас за глаза, но руки ведь чешутся)
Ivan
это первый снапшот забираешь ?
 Алексей
Алексей
ну может быть у тебя под этим снапшотом еще херова гора других снапшотов а параметр -R их льёт тоже
Алексей
вот именно
Алексей
что раз он последний значит под ним еще другие снапшоты
Алексей
почитай про параметр -R
Алексей
а он и не должен промежуточные забирать
Алексей
он забирает все что ниже
 Evgenii
Evgenii
а как ты понял что снаршот на 10 гб? это не тривиальная задача, used - совсем не это отображает, а освободится если снапшот удалить, то есть сколько уникальных данных в снимке. чтобы узнать разницу между соседними снимками, нужно смотреть свойство writen, а если снимки не соседние, то х знает как узнать
Алексей
а как ты понял что снаршот на 10 гб? это не тривиальная задача, used - совсем не это отображает, а освободится если снапшот удалить, то есть сколько уникальных данных в снимке. чтобы узнать разницу между соседними снимками, нужно смотреть свойство writen, а если снимки не соседние, то х знает как узнать
параметр written примерно равен объему данных
Алексей
мне кажется что да. параметр -R именно это и делает
Evgenii
если это первая отправка, то он отправит все данные, связанные со снимком, конечно
Evgenii
ну тогда разницу отправит
Evgenii
чтобы примерно понять сколько это, прочти свойство writen у снимка, в нем будет количество байт записанное с момента предыдущего состояния до текущего снимка
Evgenii
но это в случае если отправляешь соседние снимки, если между ними есть еще, то хз как определить точно. если отправляешь все последовательно через большую I, то надо все writen сежду начальным и конечным снимком сложить
Evgenii
used? это уникальные данные
 Maksim
Maksim
https://github.com/mafm/zfs-snapshot-disk-usage-matrix вот тут какой-то скрипт который делает dry run и показывает сколько всего между снепшотами
Maksim
If you use "zfs destroy -nv filesystem@snap1%snap2" ZFS will actually tell you how much space the sequence of snapshots between snap1 and snap2 is using.
Evgenii
если в текущем представлении есть почти все блоки из твоих снимков то used будет крошечным во всех снимках, но это не значит что при передачи они ничего не будут весить, каждый снимок мог добавлять по 100 новых гб, это надо смотреть через writen
Evgenii
короче used зависит от других снимков и от текущего состояния и НЕ отражает разницу между снимками
Evgenii
zfs get all
Evgenii
либо конкретно:
zfs get written
Evgenii
можно у всех снимков посмотреть:
zfs list -t snapshot -o name,written
Evgenii
used, это размер уникальных для снимка блоков, этих блоков не должно быть в текущем состоянии или других снимках
Evgenii
столько освободится если снимок удалить
Evgenii
эээ, это бессмысленно
Evgenii
у тебя нет текущего состояния
Evgenii
в снимке полно блоков, которые появились в его время и дожили до текущего состояния, а ты предлагаешь их не передавать
 Δαρθ
Δαρθ
[боян] virtio-blk в кему проканает чтоб дискарды шли до zvol'а, или обязательно virtio-scsi-blk ?
Юрий
Art
[боян] virtio-blk в кему проканает чтоб дискарды шли до zvol'а, или обязательно virtio-scsi-blk ?
Я юзаю только virtio-scsi, но насколько я знаю в virtio-blk уже давно дискард впилили, года два-три как
 Arseniy
Arseniy
При установке ВМ на трунасе (debian based) на миррор из двух ssd samsung 870 evo и 870 qvo (sata), словил деплой всех приложений (они также на этом мирроре). При этом, установка ВМ не прекращалась. Образ ВМ лежал на этом пуле, и устанавливалась она на этот же пул. Есть мысли, почему так произошло? ashift стандартный стоит, 12. recordsize 128кб. Но я не думаю, что дело в этом ..
Да, диски по разным технологиям немножко сделаны, и после записи некоторого объема файлов (когда кончился супербыстрый кэш), скорость записи у них отличается в два раза..
 Fedor
Fedor
Что означает деплой всех приложений?
Aba
При установке ВМ на трунасе (debian based) на миррор из двух ssd samsung 870 evo и 870 qvo (sata), словил деплой всех приложений (они также на этом мирроре). При этом, установка ВМ не прекращалась. Образ ВМ лежал на этом пуле, и устанавливалась она на этот же пул. Есть мысли, почему так произошло? ashift стандартный стоит, 12. recordsize 128кб. Но я не думаю, что дело в этом ..
Да, диски по разным технологиям немножко сделаны, и после записи некоторого объема файлов (когда кончился супербыстрый кэш), скорость записи у них отличается в два раза..
Словил деплой? Кажется ты оговорился. В любом случае без логов тут разговаривать не о чем.
Andrey
Все приложения на этом пуле (k8s) перезапустились
у куба условие - отсутствие свопфайла, поэтому упавшее и быстро поднятое не считается упавшим
я думаю oom killer просто пришел
Arseniy
у куба условие - отсутствие свопфайла, поэтому упавшее и быстро поднятое не считается упавшим
я думаю oom killer просто пришел
Интересная риторика) но у меня 64Гб памяти... Не думаю, что это было возможно. В момент этого события, занято было лишь 18Гб ОЗУ...
Владимир
 Volodymyr
Volodymyr
После непредусмотренного ребута 2а из 3 пулов отвалились Лог. Диски все в живом состоянии. Я правильно понимаю типичная проблема с Multipathing ?
Volodymyr
pool: tank
id: 5675463863221306964
state: FAULTED
status: The pool was last accessed by another system.
action: The pool cannot be imported due to damaged devices or data.
The pool may be active on another system, but can be imported using
the '-f' flag.
config:
tank FAULTED corrupted data
mirror-31 ONLINE
gptid/51068bed-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/514da65f-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-32 DEGRADED
gptid/5156f30c-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
gptid/510fcb8e-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-33 DEGRADED
gptid/52165c9b-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
gptid/530ec35f-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-34 ONLINE
gptid/530c703c-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/52cdc595-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-35 DEGRADED
gptid/52d5ee7b-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/52d36c09-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-37 ONLINE
gptid/5313a59a-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/53057245-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-38 DEGRADED
gptid/53032a15-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
gptid/5311233f-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-39 ONLINE
gptid/52c8db55-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/52d1461c-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-40 DEGRADED
gptid/52c0ed18-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/5307d4d4-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-43 ONLINE
gptid/54dcc641-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/54d6a6c5-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-44 DEGRADED
gptid/54d5ad9f-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
gptid/54d22d19-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-45 DEGRADED
gptid/54c40893-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/54e11fca-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-46 DEGRADED
gptid/54da00cf-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/54ddc984-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-48 DEGRADED
gptid/5536beb6-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/55347a18-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-49 ONLINE
gptid/559ecbf8-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/55f1500b-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-50 DEGRADED
gptid/56bffb54-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/56c997bf-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-51 ONLINE
gptid/5707e196-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/570ee104-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-55 DEGRADED
gptid/5713a37f-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/57161731-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-56 DEGRADED
gptid/570c4bef-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
gptid/56c8947e-61d4-11ed-ba6c-3cecef601d98 ONLINE
mirror-57 DEGRADED
gptid/577eaeeb-61d4-11ed-ba6c-3cecef601d98 ONLINE
gptid/57f294e4-61d4-11ed-ba6c-3cecef601d98 UNAVAIL cannot open
mirror-58 DEGRADED
gptid/57f93807-61d4-11ed-ba6c-3cecef601d98 ONLINE
Volodymyr
pool: HDD-Raid-90TB-Z2
id: 4798018631360395580
state: UNAVAIL
status: One or more devices are missing from the system.
action: The pool cannot be imported. Attach the missing
devices and try again.
see:
config:
HDD-Raid-90TB-Z2 UNAVAIL insufficient replicas
raidz2-0 ONLINE
gptid/5496dc39-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/55318d4f-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/55e9a5c4-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/5614754c-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/56119f38-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/567e8c4c-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/56a7eddd-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/56c61ff6-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/56de5809-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/57359f23-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/576e46a0-d6ee-11ea-9df6-002590eb5670 ONLINE
gptid/578ab4e2-d6ee-11ea-9df6-002590eb5670 ONLINE
raidz2-2 UNAVAIL insufficient replicas
gptid/5b330fdc-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/5d97e25e-7fcd-11ed-ad90-002590eb5670 ONLINE
gptid/5f4c5755-7fcd-11ed-ad90-002590eb5670 ONLINE
gptid/5f558ece-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/5f49c760-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/5fbec96f-7fcd-11ed-ad90-002590eb5670 ONLINE
gptid/5fb6adde-7fcd-11ed-ad90-002590eb5670 ONLINE
gptid/60c17e01-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/612c73b7-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/61064a1c-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/61835365-7fcd-11ed-ad90-002590eb5670 UNAVAIL cannot open
gptid/61922dd4-7fcd-11ed-ad90-002590eb5670 ONLINE
Владимир
у куба условие - отсутствие свопфайла, поэтому упавшее и быстро поднятое не считается упавшим
я думаю oom killer просто пришел
как связано отсутствие своп файла с тем что вы написали), Вы что решили что если свапа нет то обязательно должен быть ООМ килл?)), смешно)
Владимир
Все приложения на этом пуле (k8s) перезапустились
так там будет написана причина перезапуска
Владимир
посмотрите что там написано
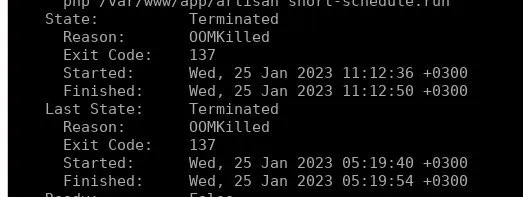 Владимир
Владимир
например вот я зарезал ОЗУ на под
Владимир
и он киляется и в его дескрайб это видно, только это вопрос не чата зфс, а чата кубер
Arseniy
Я новичок, поэтому хз где смотреть именно этот лог... У меня трунас, в штатных средствах нет. Видимо, какой то файл в системной директории?