Имена дисков могут сменится
В zfs это не влияет, он всегда на содержимое смотрит
 George
George


 Vladislav
Vladislav
Чуть практичнее ответа "Да"
 Oleg
Oleg
Всем спасибо за ответы. Пошел выбирать новый райд контроллер
 Aba
Aba
Да так будет правельнее, а если точнее то рейд перешиваемый в хба
Не всегда это возможно простыми способами. Так что бери сразу hba
Oleg
Не всегда это возможно простыми способами. Так что бери сразу hba
Попробую поискать hba в чистом виде, в прошлый раз с нескольких раз прошил успешно
Aba
Да и в целом, зачем брать рейд и перепрошивать его, когда тебе нужен hba
Oleg
Тоже логично
 Fedor
Fedor
Не ломай человеку обучение
Обучение - это чтение документации и проверка приведенных в ней методов.
Наводящие вопросы, тем более, в такой форме - это не обучение.
Не надо так.
Vladislav
Vladislav
Вы в универе когда последний раз были?
Vladislav
С преподом не времён СССР
Fedor
Вполне серьёзно)
Нападать на человека с вопросами в агрессивной форме обучением точно нельзя назвать.
Fedor
Про переезд пула в доке все что надо описано.
Fedor
Если были соблюдены общие рекомендации, проблем не будет.
Vladislav
Vladislav
Ок, whatever, троллинг оценил
George
Каким образом имя диска влияет на его GPT id?
Каким образом этот вопрос исключает возможность в реализации менеджера томов завязаться на имена дисков?
Попытался в конструктивном виде показать, что всё же без опыта вопрос бы такой человека без опыта в тупик заведёт. Ну и скрин гугла)))
George
Так я сам люблю наводящие вопросы, но с ними надо быть аккуратным, сам иногда ими людей сжигаю))
Vladislav
Каким образом этот вопрос исключает возможность в реализации менеджера томов завязаться на имена дисков?
Попытался в конструктивном виде показать, что всё же без опыта вопрос бы такой человека без опыта в тупик заведёт. Ну и скрин гугла)))
В полете фантазии - никаким, но в реальности я не застал взаимосвязи между менеджером томов, именами и zfs/madm/lvm
Ilya
С переездом стоит уделить внимание на рейдконтроллер на исходном сервере - несколько раз после переезда нарвался на проблемы с запоротыми транзакциями из последних. Пул был на дисках под lsi 9271-4i, диски в режиме jbod, но есть гипотеза, что даже в этом режиме контроллер что-то где-то кеширует и при переносе на другой сервер/другой контроллер часть "записанных" данных теряется
Alexander
Вопрос чайника
Какие есть минусы если делать в системе всего один пул?
Смотрю на структуру zfs где может быть любое число storage vdevs. Вроде как если я все разные диски и массивы добавлю в один пул то ничего не теряю. Особенно если мне не нужны отдельные настройки., cache и тд
 Vladislav
Vladislav
Для системы очень не желателен первый(единственный) пул размером более 2ТБ. Будут проблемы с загрузкой
Alexander
Для системы очень не желателен первый(единственный) пул размером более 2ТБ. Будут проблемы с загрузкой
То есть как минимум стоит иметь два пула? Один системный второй пользовательский?
Ivan
Vladislav
Если у вас размер более 2ТБ, то да, разделить системный пул от данных
Alexander
Понял, спасибо
Ivan
проблема 2тб свзяна же с легаси загрузкой и пул тут ничем не поможет
Alexander
проблема 2тб свзяна же с легаси загрузкой и пул тут ничем не поможет
Это чтобы случайно какой то файл нужный во время загрузки не вывалился в область выше 2тб?
Ivan
а то у меня один пул на 120 теров, начинаю беспокоиться
Vladislav
Я пока не перехожу на OpenZFS, остаюсь на старой версии ZFS для FreeBSD.
Ivan
zettabyte file system уперлась в 2 терабайта 😂
Vladislav
Это чтобы случайно какой то файл нужный во время загрузки не вывалился в область выше 2тб?
Кратко, 32 битные ограничения BIOS ( legacy). И соответственно проблемы с загрузчиком.
И насколько помню, не все UEFI 64 битные
Alexander
Пул из 8 жестких дисков что лучше два vdev raidz1 или один raidz2?
В обоих случаях получается два избыточных диска и доступное место размером Х6
Alexander
Читаю статьи, не однозначно
Georg🎞️🎥
Пул из 8 жестких дисков что лучше два vdev raidz1 или один raidz2?
В обоих случаях получается два избыточных диска и доступное место размером Х6
Второе
Если вылетит второй диск из ведева, то хана
Vladislav
Зависит от типа носителя и ёмкости. На больших дисках иногда raidz2 недостаточно
 Shaker
Shaker
Кто-то озадачивался ускорением zfs log ?
Сранивали optane 100, optane 200, optane 5800x и примерно одинаковые результаты. Основная нагрузка на массив - запись мелких файлов. Сейчас примерно 200K iops и 16 Gbps, хочется больше.
Shaker
https://icesquare.com/wordpress/how-to-improve-zfs-performance/
Вот конечно хорошая статья, и по ней тюнили. Но вопрос конечно про железо, и можно-ли добиться большего, и делал-ли кто-то тесты на большой нагрузке в зяпись.
 The Join Captcha Bot
The Join Captcha Bot
@EvgenlEvgenl не удалось разгадать капчу. "пользователя" выгнали.
Fedor
можно попробовать посмотреть в zpool get all
Fedor
это просто компресс, судя по всему.
Fedor
на какой-нибудь тестовой тачке можно попробовать втащить новейший зфс и посмотреть там.
посмотреть версию своего пула и полностью ли он обновлен - но без нужды не обновлять.
Fedor
а вообще - посмотреть ченджлог)
 Art
Art
Кто-то озадачивался ускорением zfs log ?
Сранивали optane 100, optane 200, optane 5800x и примерно одинаковые результаты. Основная нагрузка на массив - запись мелких файлов. Сейчас примерно 200K iops и 16 Gbps, хочется больше.
спешиал-девайс тоже по идее должен ускорить запись в пул
nikolay
по моему компрессия включается ключом
nikolay
посмотреть параметры запуска sent|recv
nikolay
тогда в чем вопрос?)
nikolay
если этого ключа нет - не поддерживает, если есть - поддерживает
nikolay
если вы реплицируете уже сжатые данные - эффекта не будет
 Алексей
Алексей
это тебе параметр надо ставить -Lec. Тогда объем переданного будет примерно равен значению written в снапшоте
Алексей
в новых версиях починили
nikolay
Алексей
а на основании чего так происходит?
У меня нет технически точного и верного ответа на этот вопрос.
nikolay
У меня нет технически точного и верного ответа на этот вопрос.
это особенность конретной версии? я с таким не сталкивался
 Δαρθ
Δαρθ
это тебе параметр надо ставить -Lec. Тогда объем переданного будет примерно равен значению written в снапшоте
а может тупо в пайп вставить zstd -zc | ... | zstd -dc ?
George
а на основании чего так происходит?
на основании того, что по дефолту zfs send отправляет данные в оригинальном виде, а не в сыром как они на диске (сжатые) лежат
George
и -L фраг по факту сжатые данные начинает передавать в виде сырых данных аля напрямую с диска
George
там ещё подобные флаги были, например для больших recordsize
George
а может тупо в пайп вставить zstd -zc | ... | zstd -dc ?
тогда с обоих сторон будет разжатие/сжатие, и выигрыш будет только в количестве переданного
George
и -L фраг по факту сжатые данные начинает передавать в виде сырых данных аля напрямую с диска
-L в данном случае ещё и меньше проца съест, т.к. данные как есть идут
nikolay
на основании того, что по дефолту zfs send отправляет данные в оригинальном виде, а не в сыром как они на диске (сжатые) лежат
расжимает перед отправкой? зачем?
George
расжимает перед отправкой? зачем?
я же написал - потому что по дефолту стрим данные в оригинальном виде отправляет
George
у send разные режимы есть, не на последнем месте совместимость, опять же
George
я кстати наврал, -L это large_blocks, а comressed это -c
George
но у них есть определённые завязки друг на друга
nikolay
я же написал - потому что по дефолту стрим данные в оригинальном виде отправляет
интересное поведение, видимо это сделано для совместимости между версиями
Artem
Всем здравствуйте. Нужна помощь. Дома стоит сервачок с ubuntu с двумя дисками по 2 тб в зеркальном пуле с minidlna. Вчера сдох 1 диск (8 лет отслужил). Сегодня купил замену, отправил подохший диск в офлайн, произвёл замену физически, сделал replace, пошёл процесс копирования. Процесс успешно закончился, на zpool list оба диска online. Вот только папки пустые, и пишет, что занято 94КБ, но свободно из 2 тб осталось 964 гигов. Что я мог упустить?
Artem
На zfs mount пишет, что "cannot open "pool/pool": dataset does not exist "
Artem
Но на zfs get выдаёт путь до пула
Art
На zfs mount пишет, что "cannot open "pool/pool": dataset does not exist "
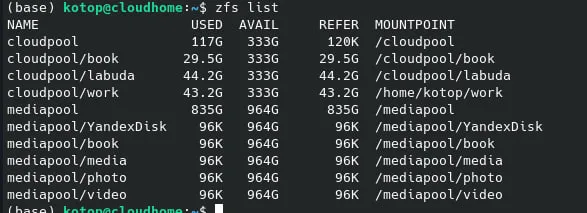
вывод zfs list покажите-ка