Всем доброго дня. Подскажите. Делаю массив raidz из 7 дисков 1,2тб. Создаю на нем диск ВМ(проксмокс). Только диск почему то отбирает почти все пространство зфс, хотя диск создаю на 3,5тб.
Raid-z1 лучше делать из 3х или из 5-ти дисков.
 riv
riv

 riv
riv
Всем доброго дня. Подскажите. Делаю массив raidz из 7 дисков 1,2тб. Создаю на нем диск ВМ(проксмокс). Только диск почему то отбирает почти все пространство зфс, хотя диск создаю на 3,5тб.
Какол volblocksize у созданных proxmox дисков? По умолчанию 8к, тогда каждые 8k займут не 8к в пуле а значительно больше!
 Sergey
Sergey
Какол volblocksize у созданных proxmox дисков? По умолчанию 8к, тогда каждые 8k займут не 8к в пуле а значительно больше!
ashift = 12. Подскажите какой лучше выставить, хранилище будет использоваться для дисков ВМ, ВМ медиатека, возможно еще чтото... С zfs только знакомлюсь, раньше всегда пользовался железными решениями.
riv
ashift = 12. Подскажите какой лучше выставить, хранилище будет использоваться для дисков ВМ, ВМ медиатека, возможно еще чтото... С zfs только знакомлюсь, раньше всегда пользовался железными решениями.
Речь не про ashit. Я постил тут таблицу потери пространства в зависимости от количества дисков в vdev для raid-z1, z2 и z3 и разных volblocksize или recordsize. Не могу найти. Может сохранилось у кого-нибудь? Я бы её вообще в закреп добавил.
Общее плавило такое. При ashift=12 и volblocksize 8k вы без потери места можно использовать только 3 диска для z1. Для ashit=9 уже можно 3, 5 или 9 дисков для z1, 4, 6 или 10 дисков для z2; и 5, 7 или 11 для z3.
Смотрите: 8к - это 2х4к. Значит если у вас, например 7 дисков, каждые 8к займут (7-1=6)х4к полезного места + диск для отказоусточивости.
Не знаю получилось ли навести вас на верную мысль.
riv
Sergey
нет, hdd sas
 Владимир
Владимир
 riv
riv
 riv
riv
Попробую пояснить логику. Я использую 16K volblocksize (в проксмокс указывается в storage типа zfs) именно по этой причине, по умолчанию proxmox создает 8К zvol для виртуальных машин. Но если вы переопределили на 16К, то новые zvol будут с новым volblocsize. Volblocksize - это аналог recordsize но для zvol.
И так если у вас дефолтные 8К, а ashist=12, то zfs буде выравнивать все на 2^12=4K, т.е. ваш 8К диск займет два сектора по 4К. А сектов vdev для 7-ми дисков в raidz1 - это 4K - паритет + 6х4K оставшиеся диски. Он сможет занять только 8К, а следующие 8К он вынужден положить в следующий сектор vdev, т.е. вы бы могли использовать не 7, а 5 дисков и результат был бы тот же.
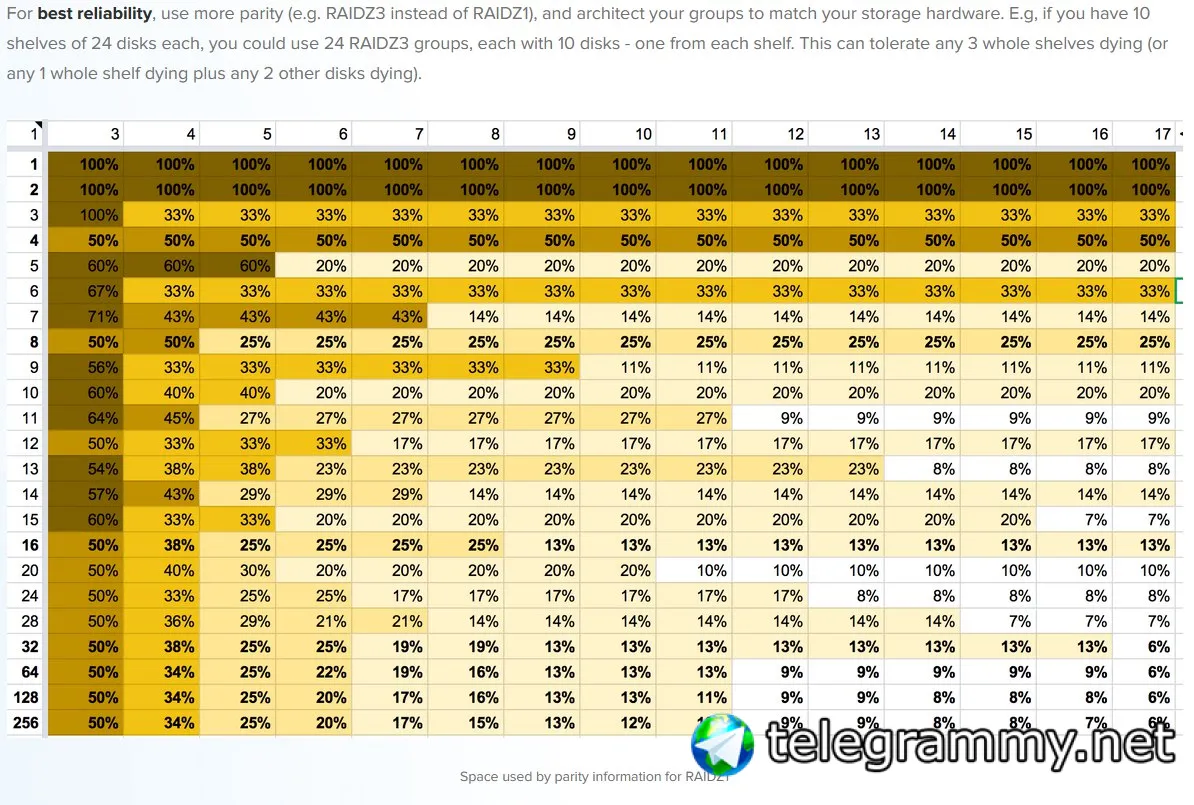
Если у вас только 7 дисков, лучше всего купить ещё 3 диска и собрать пул из двух vdev по 5 дисков или же использорвать raidz3 и радовать супернадежности :-) Но места больше не станет.
Давайте с другой стороны, для z1 и ashift=12:
для 3-х дисков, сектор vdev=8k
для 5-ти дисков, сектор vdev=(5-1)*4K=16K (если у вас volblocksize=8K, это не для вас)
для 9-ти дисков, сектор vdev=(9-1)*4K=32K
для z1 и ashift=9:
для 3-х дисков, сектор vdev=0.5К*(3-1 дисков)=1К
для 5-ти дисков, сектор vdev=(5-1)*0.5K=2K
для 9-ти дисков, сектор vdev=(9-1)*0.5K=8K (всё ещё ваш вариант)
для z2 и ashift=9:
для 6-ти дисков, сектор vdev=(6-2)*0.5K=2K
для 10-ти дисков, сектор vdev=(10-2)*0.5K=8K (всё ещё ваш вариант)
для z2 и ashift=12:
для 6-ти дисков, сектор vdev=(6-2)*4K=16K (вам надо использовать volblocksize 16K)
для 10-ти дисков, сектор vdev=(10-2)*4K=32K
Если вы переопределили volblocksize, например на 16К, вам надо учитывать что, по умолчанию венда форматирует NTFS с параментром unit=8K а 1С например, использует recordsize=8K их тоже надо изменить: форматировать ntfs c параметром unit=16K а для файловой 1С специальной утититой переформатировать базу данных (гуглить по 1C recordsize) ну и для остального всего. Это нужно сделать для того чтобы не было бесполезной потери производительности.
riv
нет, hdd sas
Но ещё попробуйте включить любое сжатие, например compress=zstd-fast, или даже просто zstd - возможно вы сильно повысите производительность дисковой подсистемы и проблема с местом уйдёт.
riv
Интересно)
Я имел в виду, что кроме ashift который как правило задаётся диском, надо манипулировать volblocksize - это уже зависит от нас.
Но для SSD я бы проигнориовал аппаратный размер блока в 4К и споставил ashift=9, по тому что SSD, а в особенности NVME дают больше IOPS на операциях с 512b секторами несмотря на заявления производителя )
 George
George
кстати, в будущем релизе дефолтный volblocksize будет уже 16k
George
как и сжатие будет включено по дефолту, а так же relatime=on
George
в общем обратите внимание на поменявшиеся дефолты в будущем мажорном релизе
 central
central
 Δαρθ
Δαρθ
как и сжатие будет включено по дефолту, а так же relatime=on
блин ну сколько можно? атайм нужен 0.01% юзеров (оценка сверху), почему он везде со своими костылями упорно включен по умолчанию??? доколе??? :)
Δαρθ
думаю через полгода, но это не точно
надеюсь это шутка? скоро уже 5.19 или 6.0 станет ЛТСом а зфс все еще будет поддерживать только древнеядра
George
George
минорная 2.1.6 на днях уже выйдет
George
много патчей вошло, на неделю точно задержали по этой причине
Владимир
надеюсь это шутка? скоро уже 5.19 или 6.0 станет ЛТСом а зфс все еще будет поддерживать только древнеядра
я глянул в первый попавшийся дедик, там 5.15 стоит и есть зфс
Владимир
я бы не сказал что это прям древнее ядро
Владимир
в дебиан тестинг где zfs 2.1.5-1, как раз ядро 5.19
Владимир
так и в чём проблема?
George
надеюсь это шутка? скоро уже 5.19 или 6.0 станет ЛТСом а зфс все еще будет поддерживать только древнеядра
вообще в мастере поддержка последнего ядра всегда через несколько дней уже доступна, если не до релиза даже, минорной версией в стейбл обычно через недели 2-месяц приезжает
Владимир
George
любители bleeding edge ядра либо ждут до месяца либо сами патчи берут всего лишь)
Δαρθ
в дебиан тестинг где zfs 2.1.5-1, как раз ядро 5.19
в том что 2.1.5 официально не поддерживает 5.19
Δαρθ
вообще в мастере поддержка последнего ядра всегда через несколько дней уже доступна, если не до релиза даже, минорной версией в стейбл обычно через недели 2-месяц приезжает
ну вот в некоторых дистрибах смотрят на то релиз или не релиз и если не релиз -- гуй вам а не 5.19... :(
Владимир
Значит они его пропатчили
Владимир
ну вот в некоторых дистрибах смотрят на то релиз или не релиз и если не релиз -- гуй вам а не 5.19... :(
я у дебиан 5.19 даже в стабильной ветке юзаю), ну там где успел обновить конечно
Владимир
стабильном дебиан в смысле
Владимир
Debian 11 короче, чтобы не было двусмысленности)
Ivan
я у дебиан 5.19 даже в стабильной ветке юзаю), ну там где успел обновить конечно
не заметил что оно тормознее ?
Владимир
или вообще
Владимир
Поясню к чему вопрос, там где у меня 5.19, там НЕ ZFS)))
Ivan
с ZFS конкретно?
сложно сказать. у меня на домашнем ноуте с амд и зфс на 5.19 лаги проявляются в обычной мышевозной деятельности.
Владимир
сложно сказать. у меня на домашнем ноуте с амд и зфс на 5.19 лаги проявляются в обычной мышевозной деятельности.
$ uname -a
Linux workpc 5.18.0-0.deb11.4-amd64 #1 SMP PREEMPT_DYNAMIC Debian 5.18.16-1~bpo11+1 (2022-08-12) x86_64 GNU/Linux
Владимир
на домашнем у меня 5.18
Ivan
больше нигде не тыкал 5.19
Владимир
пока не обновлялся
Владимир
а гуя у меня больше нигде нет))
Владимир
и кстати у меня AMD
Владимир
сложно сказать. у меня на домашнем ноуте с амд и зфс на 5.19 лаги проявляются в обычной мышевозной деятельности.
чиркани мне после 19.00, если не буду занят могу ради тебя до 5.19 обновиться проверить))
Fedor
не посоветуете, как лучше разбить 10 дисков по 4Тб?)
3+3+3 raidz и 1 в резерв
Владимир
Владимир
Производительности?
Надёжности?
Удобства дальнейшей работы с пулом?
Владимир
или доступного места?)
Fedor
производительности и надёжности
Fedor
и места)
Владимир
твой путь mirror
Fedor
гыгы
Fedor
чем плох предложенный вариант?)
Fedor
2xdraid1 4 диска + 1 hot spare
тоже не рассматривать?)
Владимир
чем плох предложенный вариант?)
ну киллерантифича твоего варианта для меня является то что если так собрать пул, удалить vdev из пула ты не сможешь))
Владимир
к примеру тебе захочется поменять диски и поставить более объёмные, если у тебя mirror, то ты добавил новый vdev, удалил старый vdev дождался пока данные перераспределятся убрал диски, а вот на raidz штатной процедуры нет))
Владимир
собирай новый пул и перекачивай в него данные
Владимир
или пробуй заменить в существующем не нужном тебе vdev диски на больший размер и вроде говорят что это реально, но явно сложнее на порядок и опаснее
Владимир
Тебе этого достаточно?) или продолжать?)
 Алексей
Алексей
продолжай
Алексей
нет я сам собираю raidz2 из 10 блинов
Алексей
я слышал что раидз можно только кратно расширять
Владимир
и кстати вроде обещают когда-то завести возможность удаления vdev с raidz, но когда это сделают....., там вроде как архитектурные проблемы, но я прям не вникал
Fedor
Тебе этого достаточно?) или продолжать?)
весомый аргумент
честно говоря про расширение пока трудно сказать
Алексей
у меня уже два таких
Владимир
и вообще, что такое кратное?
Владимир
может я не верно понял смысл?