 Andrey
Andrey


smartctl -x /dev/nvme1n1
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.13.19-6-pve] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: KINGSTON SEDC1500M1920G
Serial Number: 50026B72829B8E6A
Firmware Version: S67F0103
PCI Vendor/Subsystem ID: 0x2646
IEEE OUI Identifier: 0x0026b7
Total NVM Capacity: 1,920,383,410,176 [1.92 TB]
Unallocated NVM Capacity: 0
Controller ID: 1
NVMe Version: 1.3
Number of Namespaces: 64
Namespace 1 Size/Capacity: 1,920,383,410,176 [1.92 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 0026b7 20029b8e6a
Local Time is: Fri Sep 16 15:06:10 2022 +07
Firmware Updates (0x18): 4 Slots, no Reset required
Optional Admin Commands (0x000e): Format Frmw_DL NS_Mngmt
Optional NVM Commands (0x0054): DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x0a): Cmd_Eff_Lg Telmtry_Lg
Maximum Data Transfer Size: 64 Pages
Warning Comp. Temp. Threshold: 68 Celsius
Critical Comp. Temp. Threshold: 90 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 25.00W - - 0 0 0 0 0 0
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 24 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 2,510,989 [1.28 TB]
Data Units Written: 538,189 [275 GB]
Host Read Commands: 86,065,429
Host Write Commands: 2,125,981
Controller Busy Time: 23
Power Cycles: 3
Power On Hours: 376
Unsafe Shutdowns: 1
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
Andrey
вот вам и ответ на вопрос
а откуда взялся 128К, прокс по умолчанию так нарезает? 8к поставить надо?
 Dmitriy
Dmitriy
у вас fio генерирует запросы на чтение блоками по 8K - датасет zfs по умолчанию имеет размер recordsize 128k - т.е. меньшей итерацией читать невозможно
Dmitriy
вы даете запрос прочитать 8к - а ядро считывает 8к+120к оверхеда
Dmitriy
и так на каждую IO
Dmitriy
в выводе zio - это наглядно видно
Dmitriy
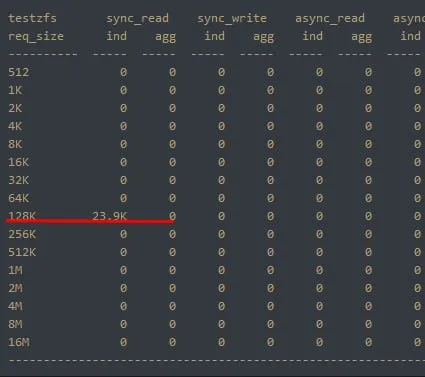 Dmitriy
Dmitriy
дальше чего то подсказать не могу - не знаю ashift пула, не знаю размер блока на vdev - нет информации для расчета агрегации чтения
Dmitriy
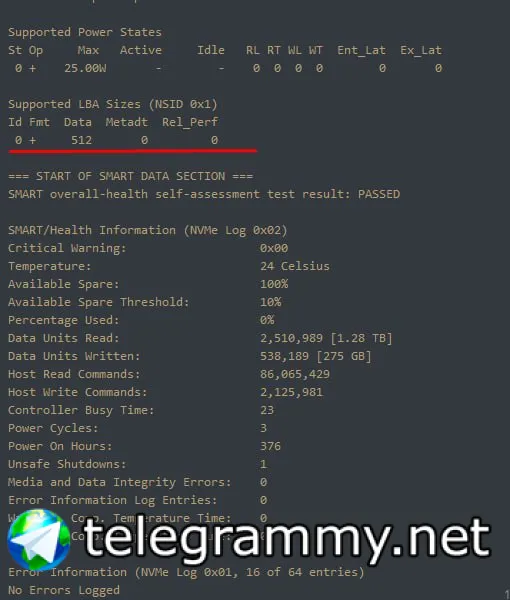 Dmitriy
Dmitriy
жаль
Dmitriy
у физ.устройства интерфейс u.2?
Andrey
а что бы это дало?
Dmitriy
ну или увеличение IO - как посмотреть
Dmitriy
за интерфейсом контроллер один хрен блоками по 512 байт не работает - 8к использует
Dmitriy
512 для совместимости с ОС используется
Andrey
понятно, больше Киннгстон не покупаем
Dmitriy
общая стратегия для не механических пулов
1. пул создавать с ashift по возможности с 4к или 8к сектором
2. включать опцию autotrim - если ssd не имеют фоновой сборки мусора или не на 3d xpoint
3. запрещать опцию датасета zfs_trim_metaslab_skip
4. датасеты размечать с recordsize под конкретный сценарий
5. настроить агрегацию чтения
6. для ssd без фоновой сборки мусора настроить cron на часы простоя пула /var/spool/cron/crontabs/root
Dmitriy
ща все будет работать
Dmitriy
0. проверить выравнивание границ раздела - если zfs использует не физ.устройство
Dmitriy
должно быть с 256 сектора для 4к или с 2048 для 512
Andrey
как с п.4. быть. Вот по умолчанию рекордсайз 128к. Это норм для файлохранилки, а для ВМ на ZVOL получается не очень, если нагрузка это докер?
Dmitriy
как с п.4. быть. Вот по умолчанию рекордсайз 128к. Это норм для файлохранилки, а для ВМ на ZVOL получается не очень, если нагрузка это докер?
что у вас за сценарий? дефолт 128к это некий средний по больнице
Dmitriy
с zvol тоже нужно понимать что сам proxmox не может их под конкретную вм делать с нужными параметрами
Dmitriy
только руками
Dmitriy
можно для всего пула задать в gui - но это тоже нужно вдумчиво делать
Andrey
в основном девсреда на кубере, немного БД постгреса, кликхауса
 Fedor
Fedor
общая стратегия для не механических пулов
1. пул создавать с ashift по возможности с 4к или 8к сектором
2. включать опцию autotrim - если ssd не имеют фоновой сборки мусора или не на 3d xpoint
3. запрещать опцию датасета zfs_trim_metaslab_skip
4. датасеты размечать с recordsize под конкретный сценарий
5. настроить агрегацию чтения
6. для ssd без фоновой сборки мусора настроить cron на часы простоя пула /var/spool/cron/crontabs/root
если это выведенные и аргументированные рекомендации, я бы их добавил в советы.
Dmitriy
есть нужно затюнить датасет/zvol под конкретный инстанс - никто не мешает создать его из cli с нужными параметрами и ручками добавить созданный диск в конфигурацию ВМ
Dmitriy
если это выведенные и аргументированные рекомендации, я бы их добавил в советы.
очень сложно давать универсальные советы - делюсь своими практическими наработками
Dmitriy
здесь очень подробно все объясняется - я так не смогу
Andrey
т.е. если я захочу постгрес разместить на zvol надо будет recorsize до ashift/volblocksize уменьшить?
 Vladislav
Vladislav
понятно, больше Киннгстон не покупаем
На самом деле, KC2500, к примеру, имеет 4к LBA
Поэтому корректнее будет сказать, что не стоит покупать диски не найдя их smartctl
Dmitriy
очень обобщенно - можно указать ФС считать синхронные операции чтения (которые все такие) - ассинхронными в пределах окна равного произведению физ блока на размер рекордсайз и коэффициэнта
 Maksim
Maksim
общая стратегия для не механических пулов
1. пул создавать с ashift по возможности с 4к или 8к сектором
2. включать опцию autotrim - если ssd не имеют фоновой сборки мусора или не на 3d xpoint
3. запрещать опцию датасета zfs_trim_metaslab_skip
4. датасеты размечать с recordsize под конкретный сценарий
5. настроить агрегацию чтения
6. для ssd без фоновой сборки мусора настроить cron на часы простоя пула /var/spool/cron/crontabs/root
можно про 3 подробнее? я такую опцию даже нагуглить не могу
Dmitriy
можно про 3 подробнее? я такую опцию даже нагуглить не могу
прошу прощения - писал по смыслу не по названию
zfs_trim_metaslab_skip
Dmitriy
коллеги
у текущей версии zfs есть фундаментальная проблема с кэшем на сверхбыстрых vdev
если объединить в зеркало несколько nvme устройств - производительность упрется в скорость ARC
и это не обойти
как это проявляется на одном устройстве vdev - например pcie4 - я не знаю
кто в курсе - разъясните
Dmitriy
изменения запланированы в третью ветку zfs
 central
central
а каким образом nvme могут быть быстрее arc?
Dmitriy
у меня никакими - только pcie3 - а в реальных сетапах проблема есть
Dmitriy
а каким образом nvme могут быть быстрее arc?
arc это не только RAM - это расчет контрольных сумм, индексация и мета
 Georg🎞️🎥
Georg🎞️🎥
Немного офф топа:
Правильно ли я понимаю, если суммарное колличесто iops моих дисков сильно меньше iops максимума hba, то никакой мультипас скоростей и отзывчивости не добавит? Речь о hdd… спасибо 👋
Georg🎞️🎥
а каким образом nvme могут быть быстрее arc?
Думаю, линейно несколько быстрых nvme могут🤔 если например как я сидеть на ddr3 каком нибудь
central
да не РАМ спокойно выходят на пропускную способность сотни гигабайт в секунду, но как отметили выше ARC Это не только RAM
Georg🎞️🎥
да не РАМ спокойно выходят на пропускную способность сотни гигабайт в секунду, но как отметили выше ARC Это не только RAM
За счёт чего ? Я не тролю, может не понимаю механизм до конца. Вот ddr3 1600 - это 12 гигов в секунду , откуда берутся сотни ? 👋
central
сотни было слишком оптиимистично, хотя ddr5 скорее может и дойдет до этого значения
 Art
Art
коллеги
у текущей версии zfs есть фундаментальная проблема с кэшем на сверхбыстрых vdev
если объединить в зеркало несколько nvme устройств - производительность упрется в скорость ARC
и это не обойти
как это проявляется на одном устройстве vdev - например pcie4 - я не знаю
кто в курсе - разъясните
Так патч DirectIO разве не для этого как раз?
Vladislav
За счёт чего ? Я не тролю, может не понимаю механизм до конца. Вот ddr3 1600 - это 12 гигов в секунду , откуда берутся сотни ? 👋
"в одноканальном режиме"
В серверах даже самых старых на v1\v2 канала 4, это уже 48ГБайт/с
central
Так патч DirectIO разве не для этого как раз?
Ну вроде да как, но до него видимо как до Луны пешком
Georg🎞️🎥
"в одноканальном режиме"
В серверах даже самых старых на v1\v2 канала 4, это уже 48ГБайт/с
Ага благодарю, ведь можете без отправки чтения мануала 👋👋
 Vladislav
Vladislav
Ага благодарю, ведь можете без отправки чтения мануала 👋👋
Потому что это первая ссылка гугла, даже не ссылка, а написано на самой странице при запросе
Dmitriy
"в одноканальном режиме"
В серверах даже самых старых на v1\v2 канала 4, это уже 48ГБайт/с
еще раз - производительность АRC != скорости RAM
Dmitriy
и да патч DirectIO - должен эту проблему решить
Georg🎞️🎥
Потому что это первая ссылка гугла, даже не ссылка, а написано на самой странице при запросе
Моя позиция такова: если я знаю ответ - по времени ответить или написать про гугл одинаково👋спасибо ещё раз
Dmitriy
я спросил о частном случае - без raidz/mirror - насколько деградирует производительность пула zfs состоящего из одинарного nvme vdev относительно производительности ФС с фикс блоком или LVM - с равной разметкой в обоих случаях
Georg🎞️🎥
я спросил о частном случае - без raidz/mirror - насколько деградирует производительность пула zfs состоящего из одинарного nvme vdev относительно производительности ФС с фикс блоком или LVM - с равной разметкой в обоих случаях
У меня тестовое зеркало из двух u2, при моих задачах прироста не увидел при тех же задачах на блинах 🤦♂️🤣🤣мож старая версия zfs, у меня 11 фри нас ))
Vladislav
еще раз - производительность АRC != скорости RAM
Знаю, знаю, сама суть что вызовы к памяти и поиск добавляют задержку
Andrey
Dmitriy подскажите пожалуйста, если смотреть на этот срез, то я правильно понимаю что надо recordsize уменьшать до 64к, или даже 32к?
datapool sync_read sync_write async_read async_write scrub trim
req_size ind agg ind agg ind agg ind agg ind agg ind agg
---------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
512 0 0 0 0 0 0 0 0 0 0 0 0
1K 0 0 0 0 0 0 0 0 0 0 0 0
2K 0 0 0 0 0 0 0 0 0 0 0 0
4K 1 0 7 0 0 0 156 0 0 0 0 0
8K 0 0 17 0 0 0 24 95 0 0 0 0
16K 0 0 5 0 0 0 1 60 0 0 0 0
32K 0 0 0 0 0 0 37 14 0 0 0 0
64K 0 0 0 0 0 0 0 16 0 0 0 0
128K 0 0 0 0 0 0 0 0 0 0 0 0
256K 0 0 0 0 0 0 0 0 0 0 0 0
512K 0 0 0 0 0 0 0 0 0 0 0 0
1M 0 0 0 0 0 0 0 0 0 0 0 0
2M 0 0 0 0 0 0 0 0 0 0 0 0
4M 0 0 0 0 0 0 0 0 0 0 0 0
8M 0 0 0 0 0 0 0 0 0 0 0 0
16M 0 0 0 0 0 0 0 0 0 0 0 0
----------------------------------------------------------------------------------------------
Dmitriy
вопрос 1 - какую цель вы хотите достигнуть
вопрос 2 - нужны все исходные данные. я просил выше параметры пула
Andrey
цель - чтобы ВМ меньше мешали друг другу
Dmitriy
критерии нагрузки - постоянная запись, постоянное случайно чтение, микс, холодные данные или что то еще
Dmitriy
я же не смогу угадать что делают ваши ВМ на данном пуле
Andrey
а какие параметры пула необходимы? ashift=12, recordsize=128 (proxmox default) volblocksize=8k
Andrey
критерии нагрузки - постоянная запись, постоянное случайно чтение, микс, холодные данные или что то еще
ну вот из той таблицы можно понять характер нагрузки?
Dmitriy
мы так чат зафлудим - проще вам подготовить вывод конфигураций и положить один архивом или файлами
Dmitriy
а какие параметры пула необходимы? ashift=12, recordsize=128 (proxmox default) volblocksize=8k
к сожалению универсальных рецептов не будет - но подстроиться можно под любые сценарии - и что менять в настройках ядра будет зависеть от понимания задач
Dmitriy
Dmitriy
для ПРИМЕРА конфиг ядра одной ноды в кластере с двумя пулами - механика и ssd.
Dmitriy
zil на p4801x
 Владислав
Владислав
Всем привет! Нужен совет
Решил все же не разводить самодеятельность - при наличии 8 дисков по 8 Tb остановиться на пуле raidz2 из 6 шт.
Оставшиеся 2 диска пойдут на замену 2*4Tb в стареньком synology 219j - который останется для холодного резервного бэкапа самых важных разделов с осинового хранилища.
Вопрос - стали бы вы зеркалировать диски холодного бэкапа при наличии основного пула raidz2?
Я пока склоняюсь к мысли, что зеркалирование холодного бэкапа будет уже избыточно - 16 Tb в этом случае гораздо лучше 8.