А робот на такие ленты сколько стоит? Нам их надо штук 20-30, чтобы бэкапы 100ТБ массива хранить.
Ну, да, в яблочко) Сами ленты дешёвые, а вот стримеры и библиотеки...😞
 Art
Art


 Василий
Василий
Да, робот окупится, если таких массивов надо десяток окучивать и лент будет сотня-две. А так дешевле еще 2-3 массива в репликацию.
 central
central
у pbs есть live restore. данные доступны почти моментально, но очень медленный доступ к ним.
Пробовал на домашнем сервере и, быстрее была подождать пока восстановится по старинке, чем live restore но когда ВМ все равно невозможно пользоваться а время на восстановление вырастет в раза 3
 Egor V
Egor V
средний срок жизни 3ТБ дисков 2-3 года. очень сильно зависит от условий эксплуатации и нагрузки на блины
У меня 10к дисков WD Red NAS edition. 5 лет полет нормальный. Всё 3 Тб. И все под zfs.
 Vladislav
Vladislav
У меня 10к дисков WD Red NAS edition. 5 лет полет нормальный. Всё 3 Тб. И все под zfs.
а нагружать пробовали?
Egor V
Так в работе все
Egor V
Бекапы, файлы, jail
Egor V
Сайты
Vladislav
и какия у них в среднем нагрузка в IOPS ?
Egor V
Не более 50%
Egor V
От макс
Vladislav
в числах
Egor V
Они либо в mirror, либо в stripe
Egor V
В числах не смотрел, сужу по gstat
Egor V
Все под FreeBSD
Vladislav
я ряд, что фряха, но iops подразумевает не % отношение, а количественное
Vladislav
вторая колонка - ops/s
Egor V
Гляну попозже
Egor V
Но нагрузка эпизодическая
Egor V
Пошёл бекап, залился, отдыхаем
Egor V
Так же и с файлами
Egor V
Нет постоянной
Egor V
24 на 7
Egor V
Через smart смотрю их в мониторинге, все число в счетчиках
Egor V
Все таки 2-3 года как то маловато) учитывая базовую гарантию в 3 года от wd
Vladislav
У меня 10к дисков WD Red NAS edition. 5 лет полет нормальный. Всё 3 Тб. И все под zfs.
на них сейчас гарантия 36 месяцев
Vladislav
+ у WD30EFAX разных годов выпуска разный размер буфера
Egor V
Я допускаю что под постоянной 100% нагрузкой они намного быстрее выходят из строя. Но у меня пока другой экспириенс при эксплуатации
 Egor
Egor
Гугл где-то писал что важен только перегрев (и его отсутствие) и даже графики приводил
Egor
Но думаю и так понятно что влажность, вибрации, перепады напряжения и пр. в условиях гугловых дц исключены
 Aleksei
Aleksei
https://itnan.ru/post.php?c=2&p=294455
Aleksei
Про влияние звуковых волн на жесткие диски
 nikolay
nikolay
столкнулся со странной проблемой. есть сервер с jbod, развернул на нем zpool объемом 136 Тб, нарезаю два zvol 50 Tb и 80 Tb и выдаю их по scst iscsi на виндоус 2012r2. оба луна под виндой определяются как диски размером 50 Тб, пытался пересоздавать zvol, удалял и добавлял в конфиг scst zvol на 80 Тб с разными номерами лунов и как разные устройства, перезагружал виндоус - не помогает( вроде у win2012r2 лимит на размер луна выше чем 50 Тб..
nikolay
интересно, а какой максимальный размер блочного луна поддерживает 2012r2?
nikolay
точнее 2019
Egor V
На 2016 работают у меня 4 луна по 146 Тб. Так что явно больше поддерживает
nikolay
На 2016 работают у меня 4 луна по 146 Тб. Так что явно больше поддерживает
да, лимит вроде 256 Тб
nikolay
тогда в чем прикол, не могу понять. это же явно не лимит scst iscsi драйвера..
Aleksei
тогда в чем прикол, не могу понять. это же явно не лимит scst iscsi драйвера..
Может отдаешь один и тот же zvol под разными лунами?
nikolay
Может отдаешь один и тот же zvol под разными лунами?
забавно, но нет, до маразма еще не дошел
nikolay
о как.. scst почему то определяет размер девайса /dev/zvol/backup/lun4 равным 54975581388800 и записывает его в конфиг.. а fdisk и parted показывает размер в 87960930222080 как и должно быть..
nikolay
релоад scst не помогает.. и лун я удалял и добавлял два раза как и zvol..
nikolay
только полная выгрузка модулей vdisk_blockio и scst iscsi_scst и перезаливка конфига помогла. очень интересный кейс..
Василий
 Василий
Василий
Если кому интересно. Завершился ресильвер одного 6ТБ диска из 24, организованных как два массива draid1 по 12. Заменялся диск во втором массиве, заполненный к моменту выхода примерно на эти 2,55ТБ. Нагрузка на время ресильвера была полностью снята.
Василий
Полтора суток конечно не радуют.
Василий
За это время я уже раз 5 полностью прогнал вышедший диск викторией, чтобы посмотреть в каком месте у него посыпалось.
 Δαρθ
Aleksei
Δαρθ
Aleksei
У нас 140 тб из 12 дисков draid2 полностью синкается около 3 суток. Упирается в скорость записи одного диска
 George
Василий
George
Василий
Ну диск показывает в виктории от 170Мб/с в начале до 60Мб/с в конце. Не знаю почему так долго ресильвер.
George
ресильвер сам в диск упрётся в любом случае, а вот ребилд должен быть сильно быстрее
Василий
а ребилд то за сколько прошёл?
Массив без начальной проверки создавался просто zpool create, пара секунд наверное.
George
Массив без начальной проверки создавался просто zpool create, пара секунд наверное.
draid создаётся со встроенным spare пространством, когда вылетает диск на это пространство происходит rebuild, этот процесс отличается от ресильвера диска
George
я про ребилд именно
Василий
У меня без spare массив. Т.е. просто вынул один диск, вставил второй, запустил ресильвер.
George
У меня без spare массив. Т.е. просто вынул один диск, вставил второй, запустил ресильвер.
а, ну смысла от draid тогда нет
Василий
Так а если на spare точно также будет сутками еще и под нагрузкой, какой смысл?
George
Так а если на spare точно также будет сутками еще и под нагрузкой, какой смысл?
так в том и смысл, что этот spare размазан ПО НЕСКОЛЬКИМ дискам, избыточность восстановится очень быстро а уже потом на фоне диск можно ресильверить без опасений
George
https://openzfs.github.io/openzfs-docs/Basic%20Concepts/dRAID%20Howto.html
George
надо было без spare позволять только форсом создавать)))
George
By default, no spares are created.
о, я прохлопал когда они позволили такое, тогда регулярно будут на такое люди наталкиваться
Δαρθ
так в том и смысл, что этот spare размазан ПО НЕСКОЛЬКИМ дискам, избыточность восстановится очень быстро а уже потом на фоне диск можно ресильверить без опасений
в смысле если из массива с избыточностью +1 вышел диск то через время оно и на оставшихся дисках станет с такой же избыточностью? и еще 1 диск сможет сдохнуть?
 Vladimir
Vladimir
здОрово.
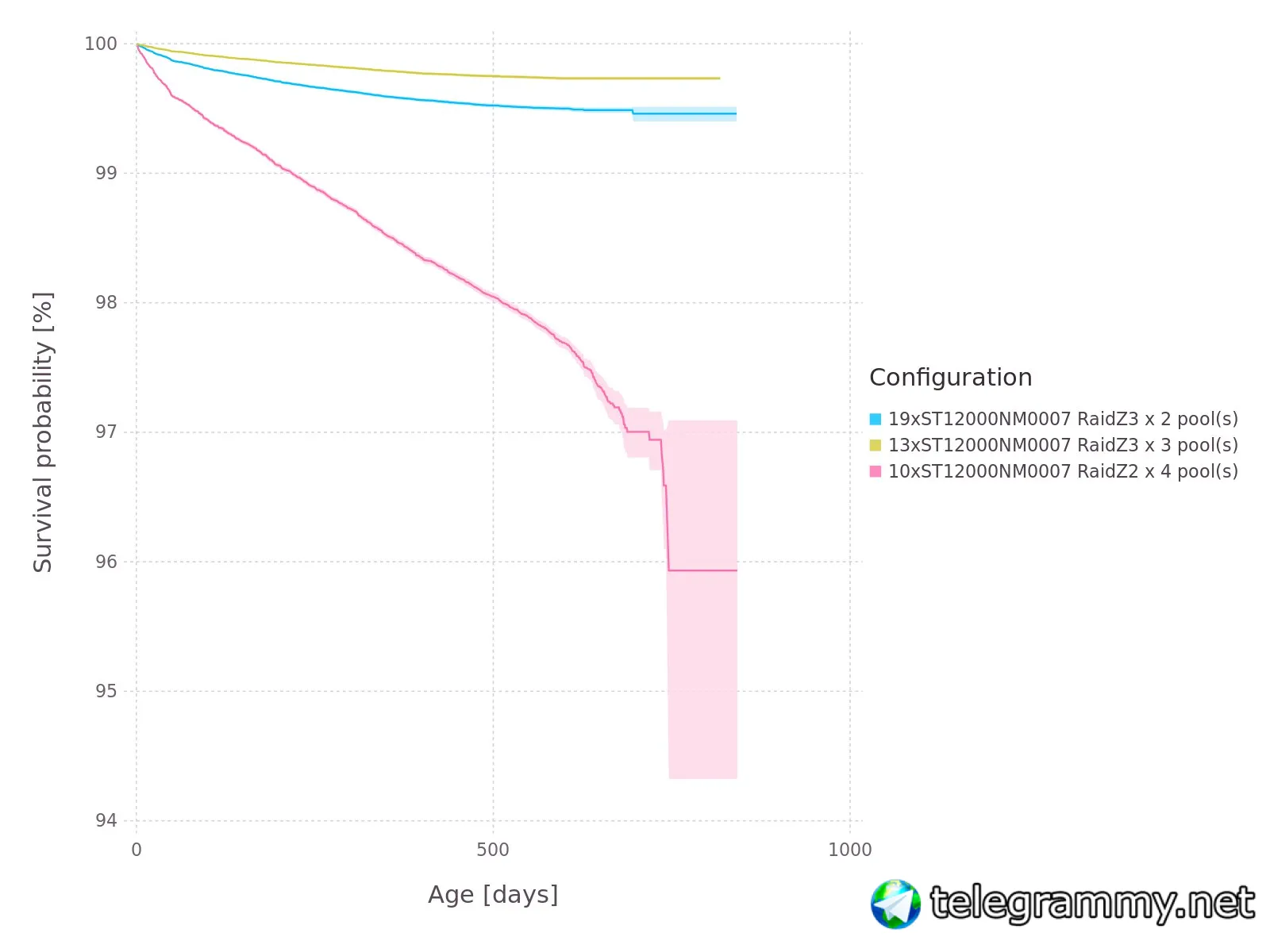 George
George
в смысле если из массива с избыточностью +1 вышел диск то через время оно и на оставшихся дисках станет с такой же избыточностью? и еще 1 диск сможет сдохнуть?
за этот счёт ещё бонус - что spare не простаивает а используется и повышает иопсы
 Vladislav
Vladislav
Здравствуйте, коллеги, у меня вопрос (можете смело посылать в Гугл, если там есть ответ на него),связанный с NVMe буфером. NVMe не в виде быстрого кэша, а в виде стораджа Вопрос следующий, "знает"/"понимает" ли ZFS наличие быстрого буфера в NVMe дисках или отношение к NVMe такое как к sata ssd? Есть ли у кого-то положительный/отрицательный опыт перехода с sata ssd на nvme?
central
Здравствуйте, коллеги, у меня вопрос (можете смело посылать в Гугл, если там есть ответ на него),связанный с NVMe буфером. NVMe не в виде быстрого кэша, а в виде стораджа Вопрос следующий, "знает"/"понимает" ли ZFS наличие быстрого буфера в NVMe дисках или отношение к NVMe такое как к sata ssd? Есть ли у кого-то положительный/отрицательный опыт перехода с sata ssd на nvme?
Ему и не надо ничего понимать больше iops == лучше, но именно nvme zfs полностью утилизировать не может, уже есть патч который решает эту проблему, но он будет выпущен только в следующем мажорном релизе, где то в пределах следующее года
Vladislav
DOK ꧁꧂
В убунте zfs наштамповал кучу снапшотов. Можно это пофиксить?
central
В убунте zfs наштамповал кучу снапшотов. Можно это пофиксить?
Удалить их, они сами по себе не создаются
Vladislav
Ему и не надо ничего понимать больше iops == лучше, но именно nvme zfs полностью утилизировать не может, уже есть патч который решает эту проблему, но он будет выпущен только в следующем мажорном релизе, где то в пределах следующее года
Понял, спасибо, это я как понимаю патч о котором шла речь с приростом x3 к скорости?
 Александр
Александр
Раньше бэкапы делались на более дешевый носитель. Например на ленту. И это имело явный смысл, т.к. серьезно дешевле чем поставить рядом второй такой массив и между ними онлайн репликацию. Но сейчас сети быстрые дешевые. Лент такого объема дешевых уже нет.
Я считал, ленты все равно получаются дешевле, но там бюджет в сотни тысяч, чтобы начало играть
Александр🇷🇺
!ban
Александр🇷🇺
А, тут нет комбота?
 Nick
Art
Nick
Art
Коллеги, посоветуйте. Стали бы вы менять диски в пуле, получившие статус DEGRADED и too many errors ? При условии, что диски новые и пробег у них небольшой. Ниже данные пула, и смарт одного из дисков. Сервер домашний.
pool: cpool
state: DEGRADED
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 9.17M in 1 days 05:41:33 with 0 errors on Mon Jan 10 06:05:40 2022
config:
NAME STATE READ WRITE CKSUM
cpool DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
ata-TOSHIBA_MG07ACA12TE_60G0A073F95G ONLINE 3 0 0
ata-TOSHIBA_MG07ACA12TE_60D0A029F95G ONLINE 0 0 0
mirror-1 DEGRADED 0 0 0
ata-TOSHIBA_MG07ACA12TE_60G0A06XF95G DEGRADED 3 0 48 too many errors
ata-TOSHIBA_MG07ACA12TE_60D0A05GF95G DEGRADED 6 0 97 too many errors
errors: No known data errors
———
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0
2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0
3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always - 7046
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 11
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline - 0
9 Power_On_Hours 0x0032 073 073 000 Old_age Always - 11118
10 Spin_Retry_Count 0x0033 100 100 030 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 11
23 Helium_Condition_Lower 0x0023 100 100 075 Pre-fail Always - 0
24 Helium_Condition_Upper 0x0023 100 100 075 Pre-fail Always - 0
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 10
193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 2565
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 24 (Min/Max 14/32)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
220 Disk_Shift 0x0002 100 100 000 Old_age Always - 35651585
222 Loaded_Hours 0x0032 084 078 000 Old_age Always - 6495
223 Load_Retry_Count 0x0032 100 100 000 Old_age Always - 0
224 Load_Friction 0x0022 100 100 000 Old_age Always - 0
226 Load-in_Time 0x0026 100 100 000 Old_age Always - 536
240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline - 0
SMART Error Log Version: 1
No Errors Logged