 Egor
Egor


Опытные, подскажите, под датасет с фильмами есть смысл выставлять recordsize 1M? Какие возможны грабли?
FreeBSD 12.2 версия пула 5000
 Evgenii
Evgenii
Опытные, подскажите, под датасет с фильмами есть смысл выставлять recordsize 1M? Какие возможны грабли?
FreeBSD 12.2 версия пула 5000
если только под фильмы, то скорее всего толк будет
 Ярослав
Ярослав
 Vladislav
Vladislav
Опытные, подскажите, под датасет с фильмами есть смысл выставлять recordsize 1M? Какие возможны грабли?
FreeBSD 12.2 версия пула 5000
Загрузочный пул может не загрузиться. Проверяйте сначала в виртуалке
 LordMerlin
LordMerlin
Не надо раскладывать перед собой грабли и пытаться не наступить.
Неужели там будет сотни подключений?
Делайте по дефолту, не усложняйте себе жизнь.
 Δαρθ
Δαρθ
я думаю там речь об экономии на размере меты и меньшей фрагментации
 central
central
я думаю там речь об экономии на размере меты и меньшей фрагментации
В контексте пары Тб на фильмы не похоже что игра стоит свеч
 Maksym
Maksym
Привет! Хорошо, что вы есть!
 Fedor
Fedor
👍👍
Δαρθ
а вот подскажите. как правильно собирать сабж из сорцов если сорцы ядра в левом месте и проинсталлить нужно только модули ядра?
Δαρθ
с наскоку --prefix=/tmp --with-linux-kernel=путьксорцам не вышло
Δαρθ
и что такое --with-linux-kernel-obj не вкурил. это /lib/modules/ что ли?
 Vladimir
Vladimir
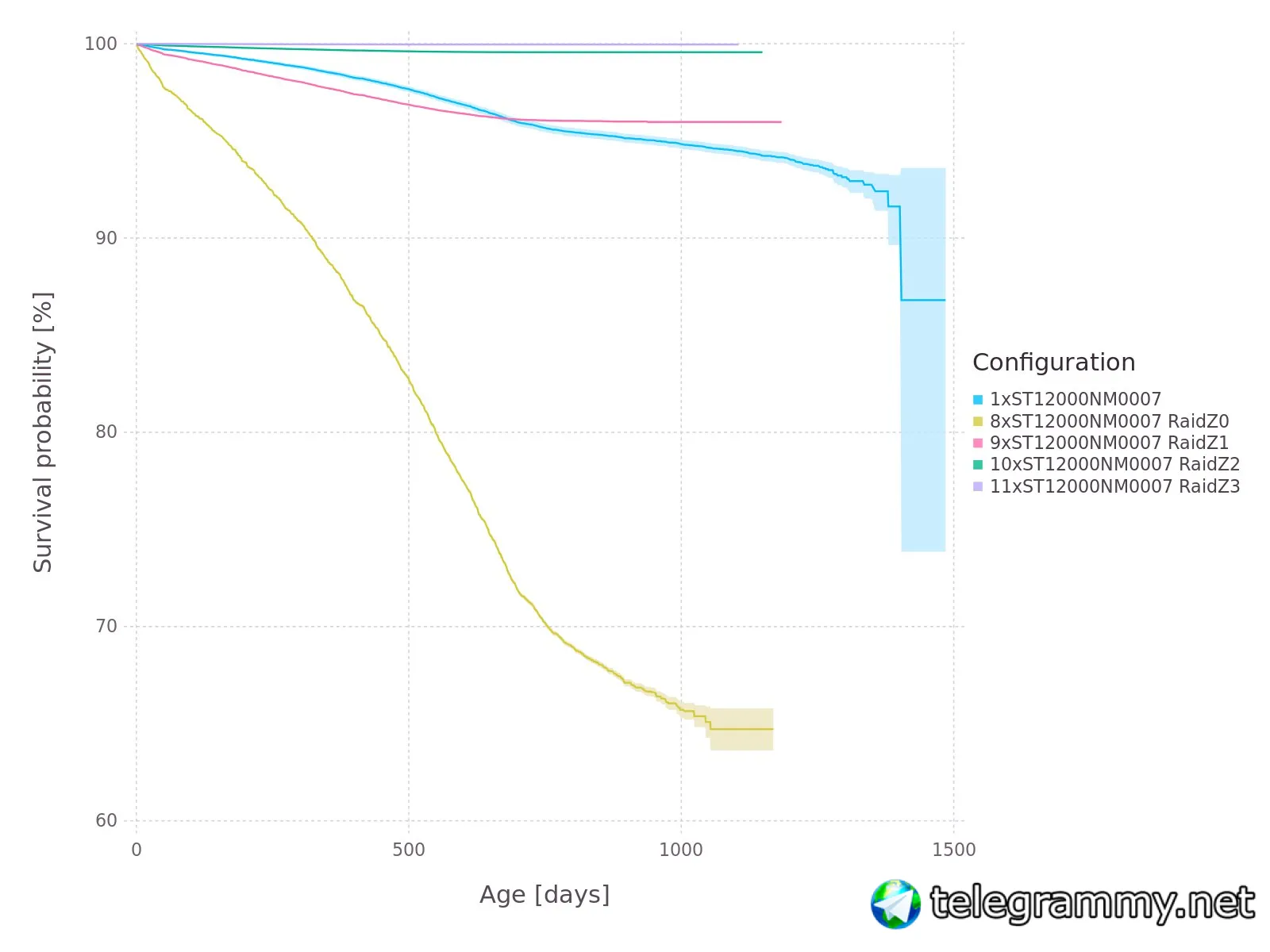
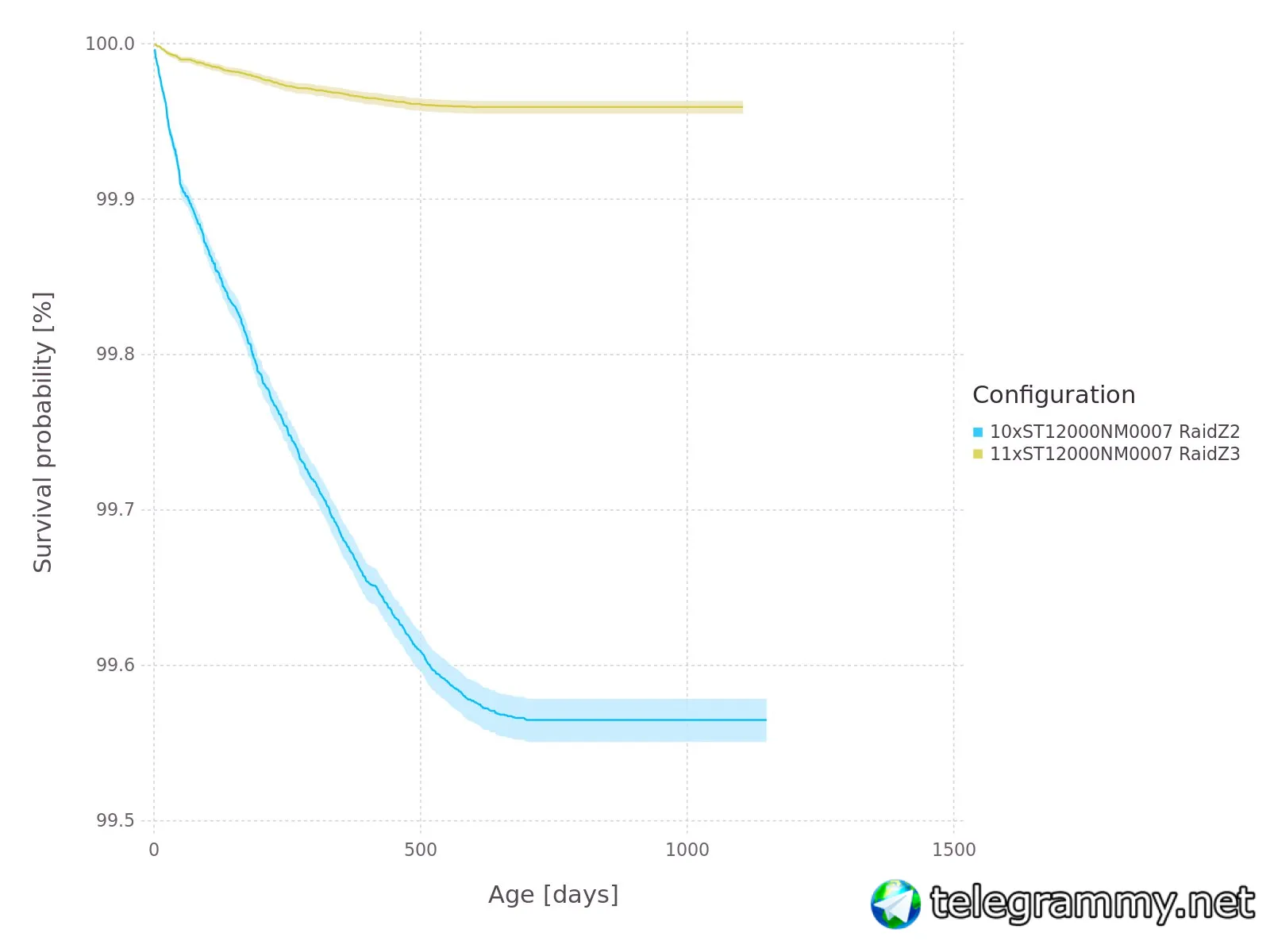
Я тут решил сделать симуляцию надёжности разных конфигураций RaidZ , на основе данных от backblaze - есть интерес?
central
 Egor V
Egor V
Разве надежность это не бекапы по схеме 3-2-1 ? ;)
Egor V
Disaster Recovery и т.д.
Vladimir
ну если интереса нет, то писать не буду
Egor V
просто непонятна цель если честно....в RAIDZ1 можно потерять 1 диск...надежность самих винтов тоже такое, не 100%
Vladimir
просто непонятна цель если честно....в RAIDZ1 можно потерять 1 диск...надежность самих винтов тоже такое, не 100%
ну так сколько шансов потерять RAID-Z1 из 9 дисков в течении года?
 Art
Art
Я тут решил сделать симуляцию надёжности разных конфигураций RaidZ , на основе данных от backblaze - есть интерес?
Интерес есть конечно! Только непонятно, как можно выполнить такую симуляцию
 Andrew
Andrew
Симуляцию, имхо, нет, но вероятность отказа — да.
 Александр
Александр
Интерес есть конечно! Только непонятно, как можно выполнить такую симуляцию
Я вот тоже не очень понимаю, о чем речь. Есть вероятность выхода диска из строя, для невыхода 8 дисков из 9 считается по совсем банальной формуле
Andrew
Вероятность потери данных на диске с e-16 и e-18 и типа рейда считается несложно, в ёкселе.
Andrew
ну если интереса нет, то писать не буду
Интерес есть. Рисовать формулу, имхо, стоит. Как минимум для себя и для критики оной формулы.
Vladimir
Я вот тоже не очень понимаю, о чем речь. Есть вероятность выхода диска из строя, для невыхода 8 дисков из 9 считается по совсем банальной формуле
ну формулу приведите и дело с концом.
Vladimir
мне-то с формулой тоже проще
Александр
Если диск выходит из строя за период с вероятностью N, то не выходит он из строя с вероятностью (1-N). Соответственно, вероятность того, что все диски отработают срок, равна (1-N)^9, выйдет из строя ровно 1 - (1-N)^8. Суммируем, получаем вероятность того, что все отработает
Александр
Средняя наработка на отказ 2.5 миллиона часов.
Vladislav
вы еще не подсчитали вероятность выхода из строя второго диска из пула
Александр
Сейчас соображу, как MTBF перевести в вероятность выхода из строя в течение года
Vladislav
а также вероятность счастливого ребилда пула
Александр
вы еще не подсчитали вероятность выхода из строя второго диска из пула
Я посчитал вероятности выхода 0 и 1 дисков. При выходе 2 диска из RAIDZ1 RAID валится.
Vladislav
да
Александр
Считать вероятность счастливого восстановления - задача очень неблагодарная.
Vladislav
почему? чем больше дисков и больше данных - снижается вероятность счастливого исхода
Александр
Но вообще в 285 лет до отказа диска я не особо... хм...
Александр
почему? чем больше дисков и больше данных - снижается вероятность счастливого исхода
но там получается очень много параметров
Александр
Итак, считаем, что вероятность выхода из строя одного диска в год - 1/285. Кстати, да, похоже
Andrew
https://www.ibm.com/support/pages/re-evaluating-raid-5-and-raid-6-slower-larger-drives
Vladislav
средний срок жизни 3ТБ дисков 2-3 года. очень сильно зависит от условий эксплуатации и нагрузки на блины
Александр
То есть, вероятность невыхода диска из строя - 0.996
Andrew
имхо, нуно считать не вероятность выхода диска из строя, а вероятность прочитать некорректную инфо с кластера диска.
Vladimir
чтобы raid сдох надо чтобы два (или сколько там надо) диска вышли из строя во время rebuild'a
Vladimir
ну и ещё у вас есть предположение, что вероятность выхода из строя не зависит от возраста диска
 Василий
Василий
Все эти вероятности довольно бестолковая вещь. Потому что в палате у больных 42, в морге около 0, а в среднем 36,5 вроде бы. Но больным все равно больно, а в тем кто в морге уже все равно.
Александр
Все эти вероятности довольно бестолковая вещь. Потому что в палате у больных 42, в морге около 0, а в среднем 36,5 вроде бы. Но больным все равно больно, а в тем кто в морге уже все равно.
Только в руках тех, кто ими пользоваться не умеет
Vladislav
в чате объявляется перепись людей прослушавших предмет "Теория вероятности и мат статистики" более 1 семестра :)
Василий
 Andrew
Василий
Andrew
Василий
Имеем такую картину. Это свежесобранный массив из 24 дисков по 6Тб. Один из них перешел в Faulty на 217-м часу жизни.
Василий
Сутки прошли, а оно все еще 6 часов до конца показывает. Поначалу я радовался, когда пара часов была. О думаю какой волшебный DRAID.
Vladislav
понять и простить. Диски небось все из одной бочки партии
Andrew
Имеем такую картину. Это свежесобранный массив из 24 дисков по 6Тб. Один из них перешел в Faulty на 217-м часу жизни.
- есть две новости, хорошая и плохая, с какой начинать?
- с хорошей, конечно.
- сервер был на гарантии
Василий
Диск смотрю викторией. Судя по всему один блин посередине сразу был битый. Когда запись до него дошла, диск кончился.
Andrew
Сутки прошли, а оно все еще 6 часов до конца показывает. Поначалу я радовался, когда пара часов была. О думаю какой волшебный DRAID.
Дурной вопрос, а если принудительно отнять из массива?
Andrew
*конечно, делать так я не советую.
Василий
Так я его заменил уже, это ресильвер идет.
Andrew
Нагрузка есть, иопсов не хватает.
Василий
Нагрузку снял почти сразу, т.к. вообще стояло. Диски понятно небыстрые, но как-то все равно там он заполнен был не больше 3ТБ уже можно было и закончить.
Andrew
Пустое место проверил, осталось данные перелить :p
Василий
Там 2 массива по 12, т.е. он 66ТБ быстро пробежал из первого и вот на втором ресильвер делает неторопливо.
Василий
Это все к чему. А к тому что все эти ваши вероятности годятся для случая, что диски были исправны. А если сразу был дефект, который вылез не сразу?
Василий
Т.е. по хорошему диск это не единый объект с одним MTBF, а там внутри еще много чего, каждый со своим.
Vladimir
 Vladimir
Vladimir
 Vladimir
Vladimir
в планах - сделать симуляцию для массива из нескольких пулов .
длина графика по времени ограничена временем наблюдения в базе backblaze
Andrew
Это все к чему. А к тому что все эти ваши вероятности годятся для случая, что диски были исправны. А если сразу был дефект, который вылез не сразу?
Ну как... в аппаратных массивах для этого идёт предварительная иницализация
Andrew
А для хоуммейд, имхо, диск прочесть стОит перед использованием.
Andrew
Но да, это сила "заднего ума".
Василий
В таких масштабах еще вопрос надежды на бэкап несколько в другом свете предстает. Допустим у нас массив на 100Тб и есть от него свежий бэкап всегда. Но если он развалится, время на полное восстановление измеряется неделями. Т.е. надо либо массив дробить, либо только ha кластеры делать и бэкапом не страдать.
Ivan
В таких масштабах еще вопрос надежды на бэкап несколько в другом свете предстает. Допустим у нас массив на 100Тб и есть от него свежий бэкап всегда. Но если он развалится, время на полное восстановление измеряется неделями. Т.е. надо либо массив дробить, либо только ha кластеры делать и бэкапом не страдать.
у pbs есть live restore. данные доступны почти моментально, но очень медленный доступ к ним.
Ivan
т.е. в первую очередь из бэкапа поднимается то что требуется в данный момент времени.
Василий
Раньше бэкапы делались на более дешевый носитель. Например на ленту. И это имело явный смысл, т.к. серьезно дешевле чем поставить рядом второй такой массив и между ними онлайн репликацию. Но сейчас сети быстрые дешевые. Лент такого объема дешевых уже нет.
Andrew
отчуждаемые РК?
Art
Раньше бэкапы делались на более дешевый носитель. Например на ленту. И это имело явный смысл, т.к. серьезно дешевле чем поставить рядом второй такой массив и между ними онлайн репликацию. Но сейчас сети быстрые дешевые. Лент такого объема дешевых уже нет.
Почему нет-то, вон картридж LTO-8 вмещает 12 тб, и стоит 6 тыс
Василий
А робот на такие ленты сколько стоит? Нам их надо штук 20-30, чтобы бэкапы 100ТБ массива хранить.
Василий
К тому же эти 12Тб не вполне честные, только если данные жмутся.
Art
К тому же эти 12Тб не вполне честные, только если данные жмутся.
Не-не, 12 чистые, а со сжатием уже до 30