А по мне так какая разница кто раздел создаёт))
ZFS has its own IO scheduler, and is built on the assumption that it gets a spinning disk to itself. If you partition a disk with other partitions, there may be a negative impact on performance. With SSDs this should be less of an issue.
 Art
Art

 Art
Art
С нуля легко - при установке системы сделаешь зфс-миррор из двух дисков, и установишь туда систему.
Для этого ставь Проксмокс (изи) или вручную накатывай Дебиан с зфс по тем огромным инструкциям (факинг хард).
Интерфейс Прокса можешь никогда не открывать после установки, и пользовать систему как обычный Дебиан
Но если в живую систему вкорячить, то можно конечно как ты уже сделал, на разделы, но моё мнение, что сие неправильно есть
 f1gar0
f1gar0
Доброй ночи прошу прощения за офф топ но ппц время уже поджимает Терминальная ферма на Win2019 не могу сделать отказоустойчивый кластер материтсья на SQL
f1gar0
готов заплатить за помощь
Art
Конечно, заюзай fio - оч популярный бенчмарк для тестирования производительности стораджа
Она не зфс-специфична, а универсальна, может тестировать любые файловые системы, тома, разделы, диски. Полезно освоить
 Anatoly
Anatoly
ну да) если серьёзно, то да, ОпенЗФС всегда создаёт разделы, но это не то же самое, чем вручную ЗФС отдать раздел. Скажу честно, сам эту тему глубоко не копал, но просто пришёл к выводу, что так делать плохо
>ОпенЗФС всегда создаёт разделы, но это не то же самое, чем вручную ЗФС отдать раздел.
тоже самое
Art
Главное, хороший адекватный тест подобрать. Тут в чате как-то выкладывали профили для фио, или можно погуглить. Там важно, чтобы кэши линукса игнорировались, и таким образом не мешали оценить производительность именно самого стораджа
И ещё осторожно с объектом теста. Если отдашь фио потестировать диск или раздел, то массив в которой этот диск/раздел задействован логичным образом пострадает. Если ещё не задействован, то но проблемо
Art
>ОпенЗФС всегда создаёт разделы, но это не то же самое, чем вручную ЗФС отдать раздел.
тоже самое
Блин, я уже сам не знаю во что верить😑
Но рекомендации отдавать диск целиком ведь не с потолка взяты? Вон я выше запостил цитату с r/zfs про шедулер
Anatoly
Блин, я уже сам не знаю во что верить😑
Но рекомендации отдавать диск целиком ведь не с потолка взяты? Вон я выше запостил цитату с r/zfs про шедулер
Если я делаю партишон в 128 мегабайт для бута и остальное отдаю zfs никакой разницы не будет с тем, если бы я весь диск отдал
Anatoly
когда говорят про "отдавать целый диск" имеется ввиду что диск должен использоватся только zfs
Anatoly
а сколько там партишенов и какого размера это уже каждый сам себе решает. Есть такая штука как overprovision дисков например.
Art
когда говорят про "отдавать целый диск" имеется ввиду что диск должен использоватся только zfs
Возможно... Но тогда вопрос, а какой в принципе смысл разбивать диски самому, если ЗФС сама это делает?
Вот @ivan0biwan свои диски поделил между мдадм и зфс. В этом есть практический смысл, но эта практика идёт жёстко вразрез с гайдлайном. Я вот о чём толкую.
Anatoly
Возможно... Но тогда вопрос, а какой в принципе смысл разбивать диски самому, если ЗФС сама это делает?
Вот @ivan0biwan свои диски поделил между мдадм и зфс. В этом есть практический смысл, но эта практика идёт жёстко вразрез с гайдлайном. Я вот о чём толкую.
boot партишон, overprovision дисков
если под мдадм сидит бут партишон, то это вообще прекрасная схема, сам так хочу сделать
Art
boot партишон, overprovision дисков
если под мдадм сидит бут партишон, то это вообще прекрасная схема, сам так хочу сделать
Оверпровижен он как работает? Не врубаюсь(
Anatoly
https://en.wikipedia.org/wiki/Write_amplification#Over-provisioning
Art
https://en.wikipedia.org/wiki/Write_amplification#Over-provisioning
Не понимаю, как это связано с зфс на разделах
Anatoly
Не понимаю, как это связано с зфс на разделах
Если zfs отдать весь диск overprovision не получится сделать
riv
Блин, я уже сам не знаю во что верить😑
Но рекомендации отдавать диск целиком ведь не с потолка взяты? Вон я выше запостил цитату с r/zfs про шедулер
Важно не чтоб целиком, можно часть диска использовать под систему, а часть (раздел) отдать под zfs.
Когда говорят отдать диски напрямую zfs имеется в виду не городить из дисков ни raid-1 ни raid-0 ни контроллером, ни софр рейдом и не использовать никакие формы writeback-кэшировпний ни програмных ни аппаратных, а вместо этого, не мудорствуя лукаво, отдать эти несчастные разделы в zfs (по одному разделу с каждого диска, не по нескольку, один диск - один zfs раздел).
А в zfs сделать из разделрв отказоустойчивый zvol: mirror, raidz1, raidz2 или несколько таких zvol.
riv
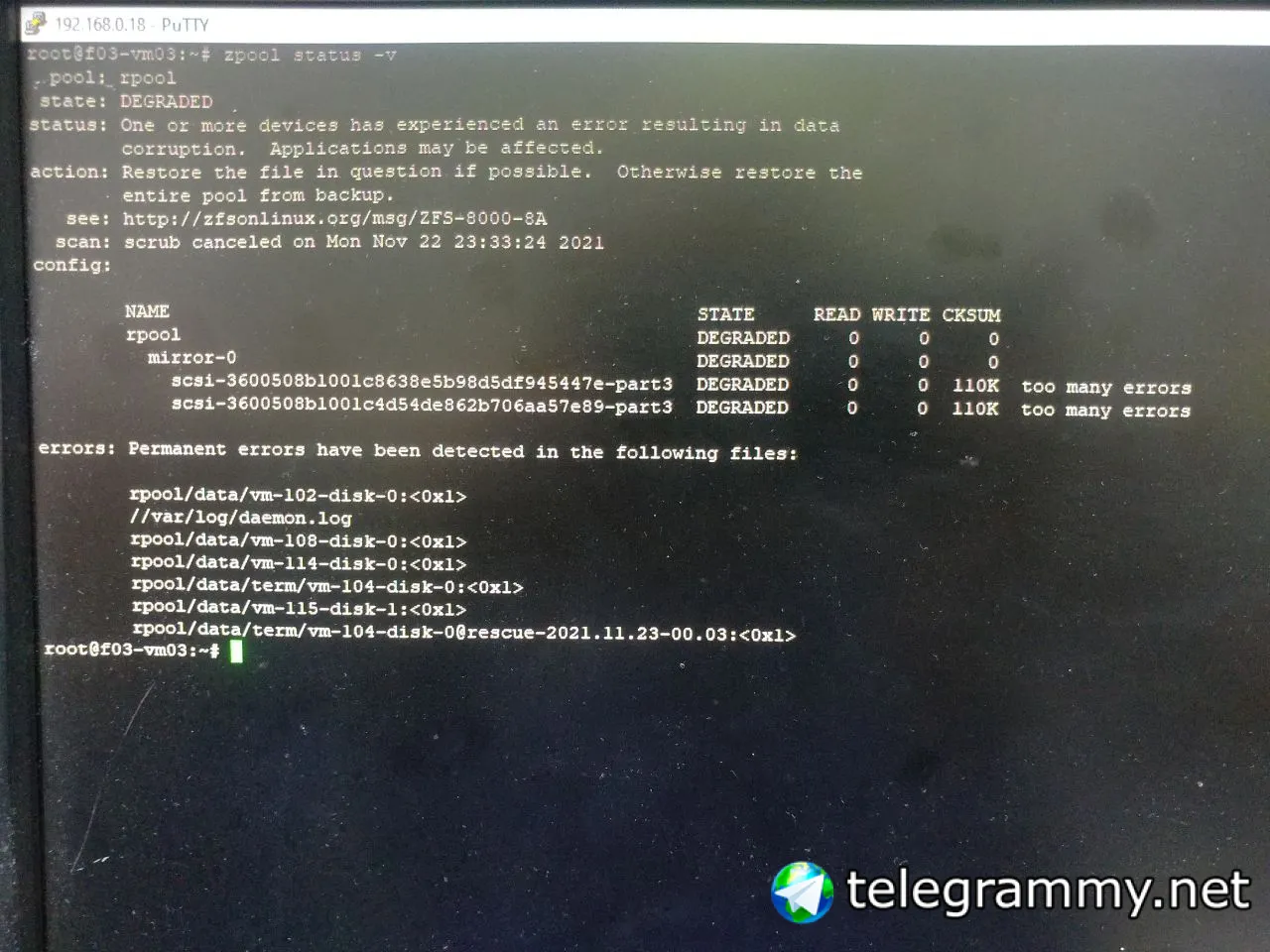 riv
riv
Если zfs отдать весь диск overprovision не получится сделать
Эм поподробнее. Почему не получится?
Anatoly
Потому что zfs скушает весь диск нет?
riv
Не понимаю, как это связано с зфс на разделах
Выравнивайте разделы на границу минимум 4к, а лучше 1м и дальше как в статье. В чем проблема. Все современные утилиты сами выравнимают на 1М.
Anatoly
Я про это и говорю
riv
https://en.wikipedia.org/wiki/Write_amplification#Over-provisioning
Там имеется в виду (не читал, но жогадыааюсь о чем речь) что если у вас не миррор, а raidz2, например из 6 дисков, то 2 димка избыточность а 4 данные. Впши данные записываются сразу на 4 диска, по этому, volblocksize и recordsize не могут быть меньше 16К и должны быть кратны 16К доя 4к- дисков или не могу быть меньше 2к и должны быть кратны 2к если диски имеют 512б сектор
Anatoly
У меня никаких проблем нет. Не понимаю вообще о чём ты и к чему говоришь
Anatoly
Промахнулся что ли цитатой
riv
Прошупрощения за опечатки. Поздно очень )
riv
Промахнулся что ли цитатой
Да нет просто не врубился о какой проблеме речь идет, но теперь вижу и вы тоже гадаете о чем собственно речь
Art
Важно не чтоб целиком, можно часть диска использовать под систему, а часть (раздел) отдать под zfs.
Когда говорят отдать диски напрямую zfs имеется в виду не городить из дисков ни raid-1 ни raid-0 ни контроллером, ни софр рейдом и не использовать никакие формы writeback-кэшировпний ни програмных ни аппаратных, а вместо этого, не мудорствуя лукаво, отдать эти несчастные разделы в zfs (по одному разделу с каждого диска, не по нескольку, один диск - один zfs раздел).
А в zfs сделать из разделрв отказоустойчивый zvol: mirror, raidz1, raidz2 или несколько таких zvol.
Хорошо, я готов согласиться, что так можно, и это не вредит или вредит незначительно. Хотя про шедулер никто так и не прокомментировал.
Но я не понимаю зачем) Не вижу смысла так делать.
Art
Важно не чтоб целиком, можно часть диска использовать под систему, а часть (раздел) отдать под zfs.
Когда говорят отдать диски напрямую zfs имеется в виду не городить из дисков ни raid-1 ни raid-0 ни контроллером, ни софр рейдом и не использовать никакие формы writeback-кэшировпний ни програмных ни аппаратных, а вместо этого, не мудорствуя лукаво, отдать эти несчастные разделы в zfs (по одному разделу с каждого диска, не по нескольку, один диск - один zfs раздел).
А в zfs сделать из разделрв отказоустойчивый zvol: mirror, raidz1, raidz2 или несколько таких zvol.
На сайте ОпенЗФС смотрите, что нашёл:
ZFS will also attempt minor tweaks on various platforms when whole disks are provided. On Illumos, ZFS will enable the disk cache for performance. It will not do this when given partitions to protect other filesystems sharing the disks that might not be tolerant of the disk cache, such as UFS. On Linux, the IO elevator will be set to noop to reduce CPU overhead. ZFS has its own internal IO elevator, which renders the Linux elevator redundant. The Performance Tuning page explains this behavior in more detail.
@nahsi_at_tg а ты говоришь, разницы нет вообще никакой.
Щас ещё глянул сайты Оракла и Илюмоса, там тоже рекомендуют отдавать диск целиком. Так прямо и пишут whole disks, not slices
Anatoly
Нет разницы, на линуксе давно нет noop шедулера вообще
Art
Нет разницы, на линуксе давно нет noop шедулера вообще
Ладно, спорить больше не буду, но пока официальные гайды говорят нет разделам, лично я их использовать не буду. Тем более непонятно чего ради. Это ведь ещё и комплексность системы увеличивает
Anatoly
Чего ради уже писали выше. Разобраться надо, прежде чем пользоваться
Anatoly
А не слепо верить документации без мейнтенера
Anatoly
И даже эти устаревшие гайды никаких Нет разделам не говорят, а лишь рекомендуют отдавать диски и при всем при этом zfs will attempt minor tweaks
Art
И даже эти устаревшие гайды никаких Нет разделам не говорят, а лишь рекомендуют отдавать диски и при всем при этом zfs will attempt minor tweaks
Это уже игра в слова - ты либо следуешь рекомендациям, либо нет.
Мне кажется, половина всех вопросов в айти чатах исходит от любителей троллейбусов из буханки (это не вам лично)
Anatoly
Софт меняется постоянно, если где-то в 2010 в интернете кто-то что-то написал и ты прочитал не разобравшись, то не нужно учить других что правильно, а что нет
Anatoly
За опытом и гайдлайнами на гитхаб и в прод
Anatoly
А не на сайты оракла хех
Anatoly
Если есть сомнения можно в ишьюсах спросить
Anatoly
Или поискать
Art
Софт меняется постоянно, если где-то в 2010 в интернете кто-то что-то написал и ты прочитал не разобравшись, то не нужно учить других что правильно, а что нет
Не учу я никого... Сто раз подчеркнул, что это моя личная позиция
Art
Неа. Только через убийство оного
Art
Ага, zpool destroy и по новой
Art
Да, девятка нынче оч редко нужна, хотя как недавно я узнал в этом самом чате, ещё производятся диски с сектором 512 байт
Art
9 как раз. 2 в 9 степени = 512
2 в 12 = 4096
Блок ЗФС должен быть равен блоку HDD
С SSD сложнее немного
Art
Один и тот же кто?
Art
В смысле в датацентрах разные диски?
Art
Понял. Смотри. Диски нынче бывают:
4K native - реально у диска блок 4К
512 native - реально у диска блок 512б
512 emulated - реально у диска 4К, но он врёт, что 512. Таких больше всего
Для ЗФС важно что на самом деле. Очень важно. Поэтому надо узнать точную модель диска, и смотреть спеки
Art
Главное в один пул не сувать диски с разным блоком, просадка по производительности будет
Art
диск 512 с ашифтом 9
по идее
не будет медленнее чем диск 4к с ашифтом 12
Главное диски 512 native не смешивать остальными в одном пуле
Art
ls -l /dev/disk/by-id/ - можно тут посмотреть
или
hdparm -I /dev/sda
Art
просте тестируй на файлах. Вот пример теста fio на случайную запись:
fio \
--name RWRITE \
--rw=randwrite \
--filename=/apool/rwrite-fio \
--size=16g \
--blocksize=4k \
--iodepth=32 \
--numjobs=16 \
--direct=1 \
--buffered=0 \
--end_fsync=1 \
--ioengine=posixaio \
/
Art
без него не взлетит
Art
ну да, 512 native ... Капец, оказывается много таких дисков. Я ещё недавно думал, что их перестали выпускать
Art
ну да, случайная запись это самый тяжкий тест для жестких дисков, в этом отношении они больше всего сливают перед ССД.
До конца не обязательно доводить, уже вон видны скорость и айопсы. В выводе ещё задержку надо глянуть.
Art
да, параметр clat - complete latency, у тебя в среднем 112 милисекунд
только вообще странно, что вывод в миллисекундах (msec), у меня вот в микросекундах (usec).
У тебя какая версия фио? fio -version
Art
видать поменяли, у меня 3.12, там микросекунды по умолчанию
Art
многовато. Я сейчас собрал на стенде пул типа страйп как у тебя из двух HDD, получил в этом тесте задержку ~50 мс, скорость 40 мебибайт и 10к айопс. У тебя всё в два раза хуже. Где-то затык.
Art
сжатие и у меня, а вот завышенный рекордсайз кстати как раз и бьёт по задержке, тем самым ухудшая и все остальное
Вообще, рекордсайз нужно подбирать под нагрузку. В данном случае нагрузка у нас этот конкретный тест фио и это 4к
Удали тестовый файл, поставь рекордсайз 128к (как у меня) и запусти тест по новой
Art
zfs set recordsize=128k mypool
riv
Понял. Смотри. Диски нынче бывают:
4K native - реально у диска блок 4К
512 native - реально у диска блок 512б
512 emulated - реально у диска 4К, но он врёт, что 512. Таких больше всего
Для ЗФС важно что на самом деле. Очень важно. Поэтому надо узнать точную модель диска, и смотреть спеки
4к проти 512 не так важны, т.к механика у дисков одного класса одинаковая и пофакту можно сразу использовать их как 4к - это в любом случае будет самый быстрый вариант с точностью до ошибки измеррения.
Есть другая, более важная причина отдавать под пул носители целиком - удобство обслуживания. Вы можете, например менять носитель, не задумываясь о том что на нем окажется ОС или ещё что-то. Я стараюсь по этой причине, по возможности выдавать весь накопитель. Но если нет возможности, отдаю раздел.
riv
сжатие и у меня, а вот завышенный рекордсайз кстати как раз и бьёт по задержке, тем самым ухудшая и все остальное
Вообще, рекордсайз нужно подбирать под нагрузку. В данном случае нагрузка у нас этот конкретный тест фио и это 4к
Удали тестовый файл, поставь рекордсайз 128к (как у меня) и запусти тест по новой
По ситнетическим тестам zfs часто сильно про 6рывает или вы получаете производительность буфера, что не информативно.
В реальности, на зфс множество вирт машин будут работать на много лучше, чем на обогнавшем его по скорочти в fio LVM
 Δαρθ
Δαρθ
Нет разницы, на линуксе давно нет noop шедулера вообще
$ cat /sys/block/sda/queue/scheduler
mq-deadline kyber [bfq] none
$ uname -r
5.14.18
none разве не тот же noop?
Anatoly
Тот же, просто называется он не noop
Anatoly
И все автомагические автоматизации фейлятся из-за этого (хотя может и пофиксили уже). И говорит о том, что дока не актуальная
Δαρθ
похорошему конечно можно протестить zfs с разными шедулерами )
для чистоты экспертмента -- на одном и том же разделе, созданном зфс когда ей отдали целый диск
Anatoly
https://github.com/openzfs/zfs/issues/9778
>Would you recommend not touching default scheduler?
That's right, these days the default scheduler works well for most common configurations and hardware. Unless you're encountering a specific problem, or have clearly measured a performance improvement for your workload, my recommendation would be to leave the default scheduler.
There were suspicions that implicated mq-deadline when the kernel first introduced multiqueue support. However, the upstream kernel appears to have sorted this out and it's no longer and issue with modern kernels.
Речь о mq-deadline
Art
https://github.com/openzfs/zfs/issues/9778
>Would you recommend not touching default scheduler?
That's right, these days the default scheduler works well for most common configurations and hardware. Unless you're encountering a specific problem, or have clearly measured a performance improvement for your workload, my recommendation would be to leave the default scheduler.
There were suspicions that implicated mq-deadline when the kernel first introduced multiqueue support. However, the upstream kernel appears to have sorted this out and it's no longer and issue with modern kernels.
Речь о mq-deadline
а не получается так, что запросы ввода-вывода проходят через два шедулера? Сначала системный, потом зфсный
Anatoly
Ну и пусть проходят? performance impact есть? Я не видел
Art
4к проти 512 не так важны, т.к механика у дисков одного класса одинаковая и пофакту можно сразу использовать их как 4к - это в любом случае будет самый быстрый вариант с точностью до ошибки измеррения.
Есть другая, более важная причина отдавать под пул носители целиком - удобство обслуживания. Вы можете, например менять носитель, не задумываясь о том что на нем окажется ОС или ещё что-то. Я стараюсь по этой причине, по возможности выдавать весь накопитель. Но если нет возможности, отдаю раздел.
я знаю, что превышение ашифта не так страшно как занижение, но разве не будет пенальти по производительности если зфс будет оперировать блоками по 4к, тогда как диск оперирует 512б?
Всё-таки иногда возможны записи меньше 4к, та же метадата. И ещё сжатие получается несколько потеряет в эффективности.
Art
Ну и пусть проходят? performance impact есть? Я не видел
да вот фз, есть они или нет, нужны тесты. Может их нет, просто ЦПУ лишнюю работу делает, вопрос насколько значительную.
 George
George
я знаю, что превышение ашифта не так страшно как занижение, но разве не будет пенальти по производительности если зфс будет оперировать блоками по 4к, тогда как диск оперирует 512б?
Всё-таки иногда возможны записи меньше 4к, та же метадата. И ещё сжатие получается несколько потеряет в эффективности.
> тогда как диск оперирует 512б
нынче это редкость, плюс ограничивает возможность без потерь перформанса менять диски (сейчас при этом ashift изменить нельзя)
George
так что надо явно понимать минусы ashift=9
Art
так что надо явно понимать минусы ashift=9
у @ivan0biwan диски как раз 512n, причём это новые серверные сигейты... Не знаю, зачем их делают, но делают.
Ivan
у @ivan0biwan диски как раз 512n, причём это новые серверные сигейты... Не знаю, зачем их делают, но делают.
много приложений хотят писать такими мелкими блоками ?
George
у @ivan0biwan диски как раз 512n, причём это новые серверные сигейты... Не знаю, зачем их делают, но делают.
подавляющее большинство дисков обычно врёт в этом месте, мб это то самое исключение но я давно таким дискам не верю
Art
подавляющее большинство дисков обычно врёт в этом месте, мб это то самое исключение но я давно таким дискам не верю
а мы именно спеки смотрели, на сайте