https://t.me/ru_zfs/15588
да, спасибо! Помню что кто-то делал, тоже буду тестировать будет ли реплика поверх ZFS на сетевых дисках успевать за моим мастером.
 Сергей
Сергей


 nikolay
nikolay
изменили размер очереди на /dev/sdb и скорость изменилась на zfs
гм.. ну смотрю я на цифры и вижу что ничего не поменялось)) конфигурацию вашего пула хотя бы выложите для начала. а так - если есть желание подискутировать далее - сделайте два теста с помощью fio - в одном случае создайте пул с настройками на уровне /dev/sd* /sys/block/sdb/queue/scheduler = noop. во втором - поменяйте настройки по умолчанию на deadline. и выложите результаты. тесты делайте на пуле из хотя бы пары дисков, причем именно физ. дисков. я делал такие тесты на zol 0.7 и zol 0.8. ничего не менялось.
 Fedor
Fedor
Я? Речь шла про иопсы диска. Hdd сейчас около 200+ выдают, если современные
Это какие? Дай пример плз.
nikolay
Я? Речь шла про иопсы диска. Hdd сейчас около 200+ выдают, если современные
200+ разве что FC scsi модели выдавали. SAS ~ 150, NL-SAS ~75-100 при вменяемых показателях latency
Fedor
200+ разве что FC scsi модели выдавали. SAS ~ 150, NL-SAS ~75-100 при вменяемых показателях latency
Нл сас это вообще сова на глобус- сата с интерфейсом скази 😁
nikolay
Нл сас это вообще сова на глобус- сата с интерфейсом скази 😁
ну как бы глубина очереди, multipath.. но механика одинаковая, поэтому чудес не бывает, да)
nikolay
цитата "In short, an NL-SAS disk is a bunch of spinning SATA platters with the native command set of SAS. While these disks will never perform as well as SAS thanks to their lower rotational rate, they do provide all of the enterprise features that come with SAS, including enterprise command queuing, concurrent data channels, and multiple host support
 Василий
Василий
Это какие? Дай пример плз.
Seagate's Exos 2X14 boasts a 524MB/s sustained transfer rate (outer diameter) of 304/384 random read/write IOPS, and a 4.16 ms average latency. The Exos 2X14 is even faster than Seagate's 15K RPM Exos 15E900, so it is indeed the fastest HDD ever.
Fedor
Seagate's Exos 2X14 boasts a 524MB/s sustained transfer rate (outer diameter) of 304/384 random read/write IOPS, and a 4.16 ms average latency. The Exos 2X14 is even faster than Seagate's 15K RPM Exos 15E900, so it is indeed the fastest HDD ever.
Интересненько.
Но это скорее исключение из правил
Fedor
Взял модельку на заметку
nikolay
Seagate's Exos 2X14 boasts a 524MB/s sustained transfer rate (outer diameter) of 304/384 random read/write IOPS, and a 4.16 ms average latency. The Exos 2X14 is even faster than Seagate's 15K RPM Exos 15E900, so it is indeed the fastest HDD ever.
их же сняли с производства? вы бы еще гибридные hdd с SLC кэшем вспомнили))
Василий
их же сняли с производства? вы бы еще гибридные hdd с SLC кэшем вспомнили))
при чем тут гибридные хдд?
Василий
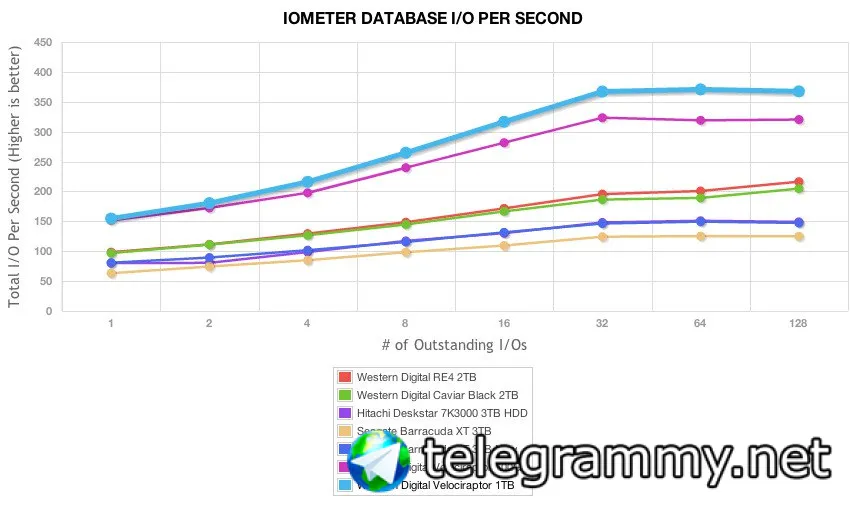
https://www.storagereview.com/review/western-digital-velociraptor-1tb-review
Василий
Random 4K read speeds from the new 1TB VelociRaptor stayed the same as the previous 600GB mode, but write speeds picked up from 300 IOPS to 371 IOPS.
Василий
 Владимир
Владимир
https://www.storagereview.com/review/western-digital-velociraptor-1tb-review
у меня на моём ПК такой. Хороший
Владимир
служит с 2012 или 2011... в общем давно)), уже всё в ПК поменялось, только он остался))
nikolay
Random 4K read speeds from the new 1TB VelociRaptor stayed the same as the previous 600GB mode, but write speeds picked up from 300 IOPS to 371 IOPS.
не, я помню что они были. они продаются сейчас?
Владимир
не, я помню что они были. они продаются сейчас?
последний раз когда видел их в продаже такой на 256Гб стоил 12к))
Василий
не, я помню что они были. они продаются сейчас?
без руля. речь была, что ипсы на дисках тоже растут. и не факт что облачное решение по иопсам будет быстрее диска (при равных условиях)
nikolay
по моему их никто уже не делает, они дороже чем десктопные ssd)
Владимир
а я вроде в районе 2к покупал ещё тогда
Владимир
самое лучшее капиталовложение))
Василий
по моему их никто уже не делает, они дороже чем десктопные ssd)
любой ент диск дороже десктопного ссд.
Владимир
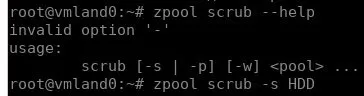
Ребят, а можно как-то остановить запущенный скраб?
nikolay
без руля. речь была, что ипсы на дисках тоже растут. и не факт что облачное решение по иопсам будет быстрее диска (при равных условиях)
ничего не растет, не выгодно и не оправдано. nl-sas на 7200 rpm наше все, забудьте про все эти поделки..
Василий
-с кажется
Владимир
Я запустил и понял что погорячился))), так как пул медленный, а сейчас ещё нагрузка на него дневная
Владимир
такой синтаксис?
Василий
ошибся -s
Василий
да
Владимир
 Andrey
Andrey
гм.. ну смотрю я на цифры и вижу что ничего не поменялось)) конфигурацию вашего пула хотя бы выложите для начала. а так - если есть желание подискутировать далее - сделайте два теста с помощью fio - в одном случае создайте пул с настройками на уровне /dev/sd* /sys/block/sdb/queue/scheduler = noop. во втором - поменяйте настройки по умолчанию на deadline. и выложите результаты. тесты делайте на пуле из хотя бы пары дисков, причем именно физ. дисков. я делал такие тесты на zol 0.7 и zol 0.8. ничего не менялось.
Можно собрать пул из /dev/sdX устройств, можно из loop, можно из файлов и т п - это просто говорит о том, что ZFS для доступа к устройствам использует интерфейс block layer linux. Они же не сумашедшие переписывать всю эту подсистему. Т е синтетические тесты в общем случае ничего не доказывают. Просто можно например затюнить на уровне vdev , чтобы не положить конкретное железо, но можно и на уровне block layer тоже подтюнить. Просто это скорее всего быстрее увидишь на медленных дисках.
nikolay
Можно собрать пул из /dev/sdX устройств, можно из loop, можно из файлов и т п - это просто говорит о том, что ZFS для доступа к устройствам использует интерфейс block layer linux. Они же не сумашедшие переписывать всю эту подсистему. Т е синтетические тесты в общем случае ничего не доказывают. Просто можно например затюнить на уровне vdev , чтобы не положить конкретное железо, но можно и на уровне block layer тоже подтюнить. Просто это скорее всего быстрее увидишь на медленных дисках.
синтетические тесты при правильной конфигурации дадут нужный уровень нагрузки при котором будет понятно какие параметры и где именно влияют на производительность пула. я привел вам пару ссылок про zfs io sched от первоисточников так сказать. вы кроме невнятной ссылки на картинку и совсем левой на форум прокса - ничего аргументированного не написали. ок, останемся при своих)
Andrey
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
zfs 1,09T 105G 1007G - - 19% 9% 1.00x ONLINE -
mirror 556G 51,8G 504G - - 19% 9,31% - ONLINE··
sdb - - - - - - - - ONLINE··
sdc - - - - - - - - ONLINE··
mirror 556G 53,3G 503G - - 19% 9,58% - ONLINE··
sdd - - - - - - - - ONLINE··
sde - - - - - - - - ONLINE··
recordsize=128K sync=standard primarycache=all secondarycache=none ram=96Gb cpu=32 arc=64Gb
fio --filename=test --size=100GB --rw=randrw --bs=256k --ioengine=posixaio \
--iodepth=1024 --runtime=120 --numjobs=64 --time_based --group_reporting --name=iops-test-job --eta-newline=1
noop nr_requests=10000
sync; echo 3 > /proc/sys/vm/drop_caches
Run status group 0 (all jobs):
READ: bw=196MiB/s (206MB/s), 196MiB/s-196MiB/s (206MB/s-206MB/s), io=32.2GiB (34.6GB), run=167910-167910msec
WRITE: bw=196MiB/s (206MB/s), 196MiB/s-196MiB/s (206MB/s-206MB/s), io=32.1GiB (34.5GB), run=167910-167910msec
sync; echo 3 > /proc/sys/vm/drop_caches
Run status group 0 (all jobs):
READ: bw=164MiB/s (172MB/s), 164MiB/s-164MiB/s (172MB/s-172MB/s), io=26.9GiB (28.9GB), run=168478-168478msec
WRITE: bw=164MiB/s (171MB/s), 164MiB/s-164MiB/s (171MB/s-171MB/s), io=26.9GiB (28.9GB), run=168478-168478msec
nr_requests=1
sync; echo 3 > /proc/sys/vm/drop_caches
Run status group 0 (all jobs):
READ: bw=113MiB/s (118MB/s), 113MiB/s-113MiB/s (118MB/s-118MB/s), io=16.5GiB (17.8GB), run=149993-149993msec
WRITE: bw=113MiB/s (118MB/s), 113MiB/s-113MiB/s (118MB/s-118MB/s), io=16.5GiB (17.7GB), run=149993-149993msec
sync; echo 3 > /proc/sys/vm/drop_caches
Run status group 0 (all jobs):
READ: bw=123MiB/s (129MB/s), 123MiB/s-123MiB/s (129MB/s-129MB/s), io=24.1GiB (25.9GB), run=200343-200343msec
WRITE: bw=123MiB/s (129MB/s), 123MiB/s-123MiB/s (129MB/s-129MB/s), io=24.0GiB (25.8GB), run=200343-200343msec
Andrey
менял только размер очереди у /dev/sdX в пуле
команда fio повторялась одна и та же
nikolay
вы принципиально не хотите поменять планировщик?) и не трогать nr_request?
nikolay
ну и информацию о пуле было бы неплохо увидеть
nikolay
инфо по latency, которую выводит fio покажите тоже
Andrey
я к тому, что у планировщика linux есть еще куча параметров и одна смена планировщика ничего в принципе не даст. Например для noop мы можем установить размер очереди 10000, а для deadline только 128 максимум
Andrey
read: IOPS=492, BW=123MiB/s (129MB/s)(24.1GiB/200343msec)
slat (nsec): min=102, max=13027k, avg=3872.37, stdev=43576.69
clat (msec): min=10, max=125001, avg=61809.15, stdev=26264.99
lat (msec): min=10, max=125001, avg=61809.15, stdev=26264.99
clat percentiles (msec):
| 1.00th=[16174], 5.00th=[17113], 10.00th=[17113], 20.00th=[17113],
| 30.00th=[17113], 40.00th=[17113], 50.00th=[17113], 60.00th=[17113],
| 70.00th=[17113], 80.00th=[17113], 90.00th=[17113], 95.00th=[17113],
| 99.00th=[17113], 99.50th=[17113], 99.90th=[17113], 99.95th=[17113],
| 99.99th=[17113]
bw ( KiB/s): min= 512, max=284160, per=100.00%, avg=171460.12, stdev=120707.95, samples=252
iops : min= 2, max= 1110, avg=669.67, stdev=471.48, samples=252
write: IOPS=491, BW=123MiB/s (129MB/s)(24.0GiB/200343msec)
slat (usec): min=3, max=18208, avg=36.71, stdev=165.16
clat (msec): min=10, max=118744, avg=61744.85, stdev=26294.25
lat (msec): min=10, max=118744, avg=61744.88, stdev=26294.26
clat percentiles (msec):
| 1.00th=[16174], 5.00th=[17113], 10.00th=[17113], 20.00th=[17113],
| 30.00th=[17113], 40.00th=[17113], 50.00th=[17113], 60.00th=[17113],
| 70.00th=[17113], 80.00th=[17113], 90.00th=[17113], 95.00th=[17113],
| 99.00th=[17113], 99.50th=[17113], 99.90th=[17113], 99.95th=[17113],
| 99.99th=[17113]
bw ( KiB/s): min= 510, max=289280, per=100.00%, avg=153097.29, stdev=124981.90, samples=281
iops : min= 1, max= 1130, avg=597.94, stdev=488.19, samples=281
lat (msec) : 20=0.27%, 50=0.05%, 100=0.02%
cpu : usr=0.03%, sys=0.00%, ctx=1903, majf=0, minf=2202
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.6%, 16=1.5%, 32=3.0%, >=64=94.6%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.8%, 8=0.1%, 16=0.1%, 32=0.1%, 64=0.1%, >=64=0.1%
issued rwts: total=98685,98463,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1024
Run status group 0 (all jobs):
READ: bw=123MiB/s (129MB/s), 123MiB/s-123MiB/s (129MB/s-129MB/s), io=24.1GiB (25.9GB), run=200343-200343msec
WRITE: bw=123MiB/s (129MB/s), 123MiB/s-123MiB/s (129MB/s-129MB/s), io=24.0GiB (25.8GB), run=200343-200343msec
Andrey
-------
Andrey
read: IOPS=654, BW=164MiB/s (172MB/s)(26.9GiB/168478msec)
slat (nsec): min=110, max=22183k, avg=3986.31, stdev=78604.71
clat (msec): min=11, max=119495, avg=44448.88, stdev=22851.08
lat (msec): min=11, max=119495, avg=44448.89, stdev=22851.08
clat percentiles (msec):
| 1.00th=[ 3205], 5.00th=[ 6544], 10.00th=[10402], 20.00th=[17113],
| 30.00th=[17113], 40.00th=[17113], 50.00th=[17113], 60.00th=[17113],
| 70.00th=[17113], 80.00th=[17113], 90.00th=[17113], 95.00th=[17113],
| 99.00th=[17113], 99.50th=[17113], 99.90th=[17113], 99.95th=[17113],
| 99.99th=[17113]
bw ( KiB/s): min= 510, max=285696, per=91.74%, avg=153827.20, stdev=126659.43, samples=274
iops : min= 1, max= 1116, avg=600.80, stdev=494.77, samples=274
write: IOPS=654, BW=164MiB/s (171MB/s)(26.9GiB/168478msec)
slat (usec): min=2, max=27660, avg=37.54, stdev=269.13
clat (msec): min=11, max=137070, avg=44371.82, stdev=22840.56
lat (msec): min=11, max=137070, avg=44371.86, stdev=22840.57
clat percentiles (msec):
| 1.00th=[ 3205], 5.00th=[ 6477], 10.00th=[10402], 20.00th=[17113],
| 30.00th=[17113], 40.00th=[17113], 50.00th=[17113], 60.00th=[17113],
| 70.00th=[17113], 80.00th=[17113], 90.00th=[17113], 95.00th=[17113],
| 99.00th=[17113], 99.50th=[17113], 99.90th=[17113], 99.95th=[17113],
| 99.99th=[17113]
bw ( KiB/s): min= 510, max=289792, per=92.42%, avg=154773.98, stdev=126739.59, samples=273
iops : min= 1, max= 1132, avg=604.51, stdev=495.07, samples=273
lat (msec) : 20=0.19%, 50=0.03%, 100=0.03%, 250=0.01%
cpu : usr=0.04%, sys=0.00%, ctx=1842, majf=0, minf=2290
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.7%, 16=1.5%, 32=3.1%, >=64=94.5%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.8%, 8=0.1%, 16=0.1%, 32=0.1%, 64=0.1%, >=64=0.1%
issued rwts: total=110352,110213,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1024
Run status group 0 (all jobs):
READ: bw=164MiB/s (172MB/s), 164MiB/s-164MiB/s (172MB/s-172MB/s), io=26.9GiB (28.9GB), run=168478-168478msec
WRITE: bw=164MiB/s (171MB/s), 164MiB/s-164MiB/s (171MB/s-171MB/s), io=26.9GiB (28.9GB), run=168478-168478msec
Andrey
Насколько я понимаю vdev* работают поверх планировщика linux и последний тоже может оказывать значение на производительность. Вопрос вроде в этом был?
nikolay
вы меня конечно извините, но у вас и в одном и в другом случае latency измеряется десятками секунд. может вернемся к реальности? например numjobs сделаем 2-4-8 и посмотрим как поменяются iops в этом случае? в общем случае смена планировщика может дать рост производительности в разы, без подкручивания каких-либо доп. параметров (того же nr_request), например для базы данных смена планировщика с cfq на deadline спокойно даст такой эффект при использовании обычного раздела на ext4. а вот в случае с zfs - не дает. по крайней мере в моих тестах. диски у вас кстати какие, sata или nl-sas?
nikolay
Насколько я понимаю vdev* работают поверх планировщика linux и последний тоже может оказывать значение на производительность. Вопрос вроде в этом был?
неправильно понимаете, почитайте внимательно вторую ссылку с пояснениями Matt Ahrens
Andrey
диски и тесты уже завтра, но наверное nl sas на блейде внутренние
Так тесты интересны как раз не когда система справляется, а когда у нее не хватает ресурсов, как она себя вести будет
nikolay
диски и тесты уже завтра, но наверное nl sas на блейде внутренние
Так тесты интересны как раз не когда система справляется, а когда у нее не хватает ресурсов, как она себя вести будет
вы сами то не видите разве что у вас цифры не отличаются почти. разница в 150 iops при латенси 60 и 40 сек.))) у вас и в одном и в другом случае весь ввод/вывод на сервере пардон раком стоит - так что изменение параметра nr_request ничего вам НЕ дает, абсолютно ничего))
nikolay
вот когда у вас, например, при планировщике =noop и numjobs=8 тест выдает 1000 iops при latency=50 ms, а при планировщике =deadline, 1500 iops при latency=30 ms - вот тут эффект на лице, как говориться. кстати цифры по iops могут и не поменяться кардинально, например при высоком disk saturation IOPS расти не будут, но за счет алгоритма работы планировщика может упасть latency, это тоже эффект. понимаете о чем я?
nikolay
диски и тесты уже завтра, но наверное nl sas на блейде внутренние
Так тесты интересны как раз не когда система справляется, а когда у нее не хватает ресурсов, как она себя вести будет
модели дисков можно посмотреть же, nl-sas обычно 3.5", вряд ли их в лезвие засунули, думаю у вас sas диски стоят, в принципе для них изменение параметра nr_request имеет смысл, при условии что они справляются с нагрузкой.
nikolay
у меня кстати есть сервер на котором можно сделать аналогичные тесты, прогоню сегодня вечером.
Andrey
я не могу подойти и посмотреть - сервер за 300 км от меня
Andrey
завтра через ilo гляну
 Δαρθ
Δαρθ
что еще раз показывает что выбор одного из штатных планировщиков linux для дисков, которые входят в пул, не имеет смысла
что же получается, если пул собран не на целиковых дисках а на ихних разделах, то это зфс мне шедулеры всё равно сносит?
nikolay
что же получается, если пул собран не на целиковых дисках а на ихних разделах, то это зфс мне шедулеры всё равно сносит?
мм. как я понял наоборот, если на whole disk - то задаст при создании пула в noop (хотя меня сомнения берут, надо проверить), если на партициях - то останется as is
Δαρθ
мм. как я понял наоборот, если на whole disk - то задаст при создании пула в noop (хотя меня сомнения берут, надо проверить), если на партициях - то останется as is
а, ок )
то есть если хотите сабжу засунуть свой шедулер — достаточно сдлеать раздел на весь диск и скормить его zfsу :)
nikolay
а, ок )
то есть если хотите сабжу засунуть свой шедулер — достаточно сдлеать раздел на весь диск и скормить его zfsу :)
вот у меня есть убеждение что не надо ничего никуда засовывать), правда гуру в чате молчат..
Fedor
а, ок )
то есть если хотите сабжу засунуть свой шедулер — достаточно сдлеать раздел на весь диск и скормить его zfsу :)
Вроде как это только к дисковому кешу относится
Fedor
И не раздел, а весь диск
Fedor
На разделах вообще работать фу
Ivan
На разделах вообще работать фу
в линуксе при подсовывании всего диска zfs создает раздел почти на весь диск
Fedor
нутк под решения бюджеты надо уметь выбивать)
Δαρθ
под моё решение и на разделах ок )
Василий
хорошо так рассуждать когда деньги на железо даёт дядя
Э... А что не так с весь диск без раздела?
Δαρθ
все ок. если дисков дофуя )
hrhi gsci has been banned! Reason: CAS ban.
Ivan
https://github.com/openzfs/zfs/releases
тут 2.0.5 вышел
Δαρθ
https://github.com/openzfs/zfs/releases
тут 2.0.5 вышел
https://packages.gentoo.org/packages/sys-fs/zfs тут уже есть )