LA это просто число в очереди в среднем за минуту, 5 минут и 15 минут
И если эта очередь скапливается в сторону ключевых ресурсов, которые важны для работы, то всё ляжет. Доступно объяснил?
Не так) la вычисляемый параметр, динамический. На телефоне нет ссылки на хорошую статью с описанием, завтра скину если интересно
 nikolay
nikolay


 Владимир
Владимир
Не так) la вычисляемый параметр, динамический. На телефоне нет ссылки на хорошую статью с описанием, завтра скину если интересно
я понимаю что я поясняю это топорно, я читал хорошие статьи, но чтобы нормлаьно объёснить нужно сначала докинуть много вводных данных)), это целая статья))
Владимир
скинь конечно, если не мне, то кому-то другому пригодится)
Владимир
LA это не то параметр который можно объяснить в двух словах))

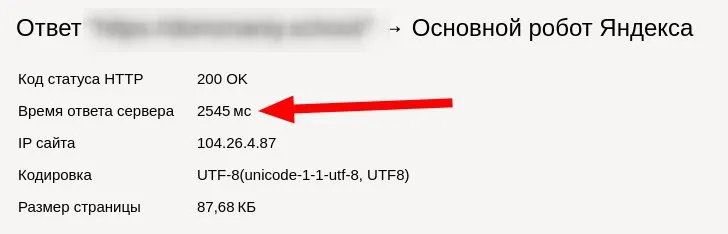 Владимир
Владимир
а вот вернул синхронную запись на принудительной основе)
Владимир
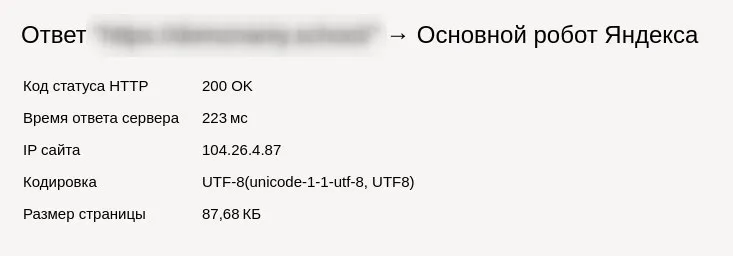 Владимир
Владимир
причём прикол ещё в том что место куда я пишу данные, а именно медленный пул HDD, никак не участвует в работе сайта.то есть очереди к одному пулу влияют и на другие...
Владимир
пока думаю без него, а там дальше если совсем печалить будет, дозакажу NVME и на них сделаю Slog
Andrey
У вас linux? Планировщик вв/выв какой?
Andrey
Насколько я представляю-да
Вы же собираете пул из блочных устройств,драйвер которых обслуживает ядро.
nikolay
Насколько я представляю-да
Вы же собираете пул из блочных устройств,драйвер которых обслуживает ядро.
Я делал тесты меняя настройки для дисков из которых собирал пул - в моем случае ничего не менялось совсем
nikolay
Как я помню zfs использует свой встроенный скедулер
Andrey
Я делал тесты меняя настройки для дисков из которых собирал пул - в моем случае ничего не менялось совсем
https://wiki.archlinux.org/title/Improving_performance#Changing_I/O_scheduler
https://wiki.archlinux.org/title/ZFS#I/O_Scheduler
Вот для размышлений
Andrey
И вот картинка https://www.thomas-krenn.com/de/wikiDE/images/e/e0/Linux-storage-stack-diagram_v4.10.png
ZFS находится там же, где device mapper/LVM
Andrey
И с форума proxmox
"If yours storage have anothers layers between the storage layers(who will use an unknown or others disk queue like ssd) then the best bet is noop. But if you use let say rotational disks, is better to use deadline (who have 2 differnst queue for writes 40% and for reads 60%).
Any of them noop/dedline will have 0% impact if you do not saturate the I/O disk capacity. Also many others details can impact on this (cache, iops, latency, etc)
As a side note, you can use in OS let say noop, but for zfs you can use dedline."
Т е нужно смотреть в каждом конкретном случае профиля нагрузки
 Fedor
Fedor
Занятная картинка, утащил к себе, спасибо.
nikolay
скинь конечно, если не мне, то кому-то другому пригодится)
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html - наверное самое вменяемое пояснение за этот параметр
Fedor
Fedor
Поэтому у многих, привыкших к первичным метрикам типа цпу или рамы крыша от неё и едет 😁
nikolay
И вот картинка https://www.thomas-krenn.com/de/wikiDE/images/e/e0/Linux-storage-stack-diagram_v4.10.png
ZFS находится там же, где device mapper/LVM
эту картинку я видел не раз. не вижу в ней zfs, но это не суть, эта картинка не дает никакого представления об используемом самим zfs io sched, даже если им используется системный.
nikolay
И с форума proxmox
"If yours storage have anothers layers between the storage layers(who will use an unknown or others disk queue like ssd) then the best bet is noop. But if you use let say rotational disks, is better to use deadline (who have 2 differnst queue for writes 40% and for reads 60%).
Any of them noop/dedline will have 0% impact if you do not saturate the I/O disk capacity. Also many others details can impact on this (cache, iops, latency, etc)
As a side note, you can use in OS let say noop, but for zfs you can use dedline."
Т е нужно смотреть в каждом конкретном случае профиля нагрузки
я бы обратился к библии так сказать) например, вот тут https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/ZIO%20Scheduler.html
nikolay
а если говорить про настройки на уровне /dev/sd*, то "ZFS automatically sets the io scheduler to noop on any drives in a zpool."
nikolay
параметры, которые отвечают за тюнинг io sched для zfs выглядят примерно так
nikolay
vfs.zfs.vdev.max_active
vfs.zfs.vdev.sync_read_min_active
vfs.zfs.vdev.sync_read_max_active
vfs.zfs.vdev.sync_write_min_active
vfs.zfs.vdev.sync_write_max_active
vfs.zfs.vdev.async_read_min_active
vfs.zfs.vdev.async_read_max_active
vfs.zfs.vdev.async_write_min_active
vfs.zfs.vdev.async_write_max_active
vfs.zfs.vdev.scrub_min_active
vfs.zfs.vdev.scrub_max_active
nikolay
что еще раз показывает что выбор одного из штатных планировщиков linux для дисков, которые входят в пул, не имеет смысла
nikolay
я бы обратился к библии так сказать) например, вот тут https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/ZIO%20Scheduler.html
или тут https://gist.github.com/szaydel/6244302
nikolay
статье 8 лет, и очень интересно читать вот этот абзац
nikolay
APPENDIX: problems with the current i/o scheduler
The current ZFS i/o scheduler (vdev_queue.c) is deadline based. The problem with this is that if there are always i/os pending, then certain classes of i/os can see very long delays.
For example, if there are always synchronous reads outstanding, then no async writes will be serviced until they become "past due". One symptom of this situation is that each pass of the txg sync takes at least several seconds (typically 3 seconds).
If many i/os become "past due" (their deadline is in the past), then we must service all of these overdue i/os before any new i/os. This happens when we enqueue a batch of async writes for the txg sync, with deadlines 2.5 seconds in the future. If we can't complete all the i/os in 2.5 seconds (e.g. because there were always reads pending), then these i/os will become past due. Now we must service all the "async" writes (which could be hundreds of megabytes) before we service any reads, introducing considerable latency to synchronous i/os (reads or ZIL writes).
Andrey
Ну на картинке zfs нет т к ее не хотят брать в ядро
vfs - это выше /dev/sda и т п, насколько я понимаю для работы с физическим устройством используется стандартный механизм linux. В zfs не пилят же прямой доступ к дискам, были бы проблемы при работе в виртуальных средах по типу как в ASM от Oracle, где для работы в vmware требуется проброс и монопольный доступ к диску
nikolay
а если говорить про настройки на уровне /dev/sd*, то "ZFS automatically sets the io scheduler to noop on any drives in a zpool."
еще раз вдумчиво прочитайте фразу. потом подумайте почему)
nikolay
Ну на картинке zfs нет т к ее не хотят брать в ядро
vfs - это выше /dev/sda и т п, насколько я понимаю для работы с физическим устройством используется стандартный механизм linux. В zfs не пилят же прямой доступ к дискам, были бы проблемы при работе в виртуальных средах по типу как в ASM от Oracle, где для работы в vmware требуется проброс и монопольный доступ к диску
интересно, какая ОС сейчас предоставляет "прямой" доступ к дискам?))) это как вообще - напрямую минуя scsi-mid layer отправлять scsi|ata команды в контроллер диска что-ли?)))
Fedor
Вроде бы никто. Ну либо свой модуль.
Все низкоуровневые обращения так и так идут через ядро.
 Сергей
Сергей
Всем привет!
Есть у кого-то опыт по сборке ZFS на сетевых дисках? В первую очередь интересует GCP (Perstistent SSD), возможно кто-то делал на S3. @gmelikov, вы вроде писали что S3 даже хотят добавить в исходники. Или может у вас в компании есть опыт и кто-то собирал такие пулы?
p.s. Конечно я знаю что для ZFS нужны физические устройства)) В данном случае речь идёт о тестовом сервере с некритическими данными. И к огромному сожалению условия именно такие, что ничего - кроме сетевых дисков в наличии нет
Fedor
Тут кто-то делал такое. Но в отношении надёжности и стабильности - большие вопросы
 Василий
Василий
Сделай на файлах
Сергей
Тебе для поиграться?
почти. Нужно https://postgres.ai поднять в GCP облаке на их сетевых дисках
 George
George
Всем привет!
Есть у кого-то опыт по сборке ZFS на сетевых дисках? В первую очередь интересует GCP (Perstistent SSD), возможно кто-то делал на S3. @gmelikov, вы вроде писали что S3 даже хотят добавить в исходники. Или может у вас в компании есть опыт и кто-то собирал такие пулы?
p.s. Конечно я знаю что для ZFS нужны физические устройства)) В данном случае речь идёт о тестовом сервере с некритическими данными. И к огромному сожалению условия именно такие, что ничего - кроме сетевых дисков в наличии нет
про s3 на проде пока рано думать, оно только концептуально обсуждается.
Технически для zfs без разницы, избыточность может не понадобиться, если она уже есть уровнем ниже
Василий
Не уверен, но можно пробовать опять же создать там файлы и их уже собрать в пул
Василий
Только это изврат
Василий
ИХВРАТИЩЕЕЕ
Сергей
Не уверен, но можно пробовать опять же создать там файлы и их уже собрать в пул
если выбирать между файлами или гугловыми сетевыми дисками (которые они как блочные устройства выдают), то наверное уж лучше второе делать.
Fedor
Проблемы ещё и в доступных иопсах- тут это тоже обсуждали
Fedor
Ой не факт.
Andrey
echo 10000 > /sys/block/sdb/queue/nr_requests
zpool iostat 1 -l
capacity operations bandwidth total_wait disk_wait syncq_wait asyncq_wait scrub trim
pool alloc free read write read write read write read write read write read write wait wait
---------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
zfs 1,35T 662G 457 387 11,7M 17,0M 27ms 36ms 17ms 2ms 1ms 7us 165ms 57ms 285ms -
zfs 1,35T 662G 653 561 27,1M 14,1M 15ms 20ms 15ms 2ms 11us 886ns - 18ms - -
zfs 1,35T 662G 672 110 28,1M 11,0M 15ms 406us 15ms 386us 8us 2us - 110us - -
zfs 1,35T 662G 875 38 34,5M 3,45M 14ms 329us 14ms 320us 19us 2us - 39us - -
zfs 1,35T 662G 886 0 32,1M 19,9K 14ms 98us 14ms 98us 3us 3us - - - -
zfs 1,35T 662G 1,14K 54 29,8M 6,03M 11ms 378us 11ms 359us 44us 1us - 83us - -
zfs 1,35T 662G 1K 623 25,3M 14,0M 11ms 13ms 11ms 2ms 12us 2us - 11ms - -
zfs 1,35T 662G 640 506 14,3M 58,7M 17ms 661us 17ms 301us 36us 1us - 614us - -
zfs 1,35T 662G 400 1,12K 10,3M 60,3M 24ms 178us 24ms 145us 6us 1us - 199us - -
zfs 1,35T 662G 238 990 4,94M 89,3M 46ms 208us 46ms 181us 8us 1us - 93us - -
zfs 1,35T 662G 134 1,95K 3,39M 105M 63ms 146ms 63ms 4ms 2us 1us - 146ms - -
zfs 1,35T 662G 544 202 12,5M 4,77M 20ms 78us 20ms 75us 2us 1us - 2us - -
zfs 1,35T 662G 1020 129 30,7M 5,10M 11ms 121us 11ms 117us 37us 2us - 44us - -
zfs 1,35T 662G 967 0 22,9M 20,0K 10ms 98us 10ms 98us 24us 3us - - - -
zfs 1,35T 662G 1,07K 93 34,0M 4,76M 12ms 134us 12ms 124us 61us 1us - 59us - -
zfs 1,35T 662G 656 847 22,6M 27,1M 19ms 38ms 19ms 4ms 91us 1us - 37ms - -
echo 1 > /sys/block/sdb/queue/nr_requests
zpool iostat 1 -l
capacity operations bandwidth total_wait disk_wait syncq_wait asyncq_wait scrub trim
pool alloc free read write read write read write read write read write read write wait wait
---------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
zfs 1,35T 662G 457 387 11,7M 17,0M 27ms 36ms 17ms 2ms 1ms 7us 165ms 57ms 285ms -
zfs 1,35T 662G 510 155 14,8M 12,3M 14ms 142us 14ms 132us 2us 1us - 33us - -
zfs 1,35T 662G 420 574 16,0M 10,1M 16ms 28ms 16ms 3ms 2us 1us - 24ms - -
zfs 1,35T 662G 551 47 18,3M 3,56M 12ms 122us 12ms 116us 2us 2us - 36us - -
zfs 1,35T 662G 550 140 18,7M 11,1M 13ms 141us 13ms 131us 2us 1us - 41us - -
zfs 1,35T 662G 562 0 16,9M 20,0K 12ms 98us 12ms 98us 2us 3us - - - -
zfs 1,35T 662G 540 38 18,2M 3,28M 12ms 159us 12ms 158us 2us 1us - 9us - -
zfs 1,35T 662G 455 564 16,4M 14,1M 15ms 15ms 15ms 2ms 2us 1us - 15ms - -
zfs 1,35T 662G 353 1 13,1M 55,9K 20ms 98us 20ms 98us 2us 3us - - - -
zfs 1,35T 662G 562 34 16,2M 3,14M 12ms 105us 12ms 98us 1us 1us - 18us - -
zfs 1,35T 662G 571
Andrey
изменили размер очереди на /dev/sdb и скорость изменилась на zfs
Василий
всяко будет больше, чем на hdd
Ну один обычный хдд. 200-400 иопсов даёт. Какой пинг у тебя на гугл?
Andrey
nr_requests как раз там, где планировщики выбираются для устройств
nikolay
почти. Нужно https://postgres.ai поднять в GCP облаке на их сетевых дисках
поищи по чату, точно обсуждалась такая схема..
Fedor
7200 ~=100
Fedor
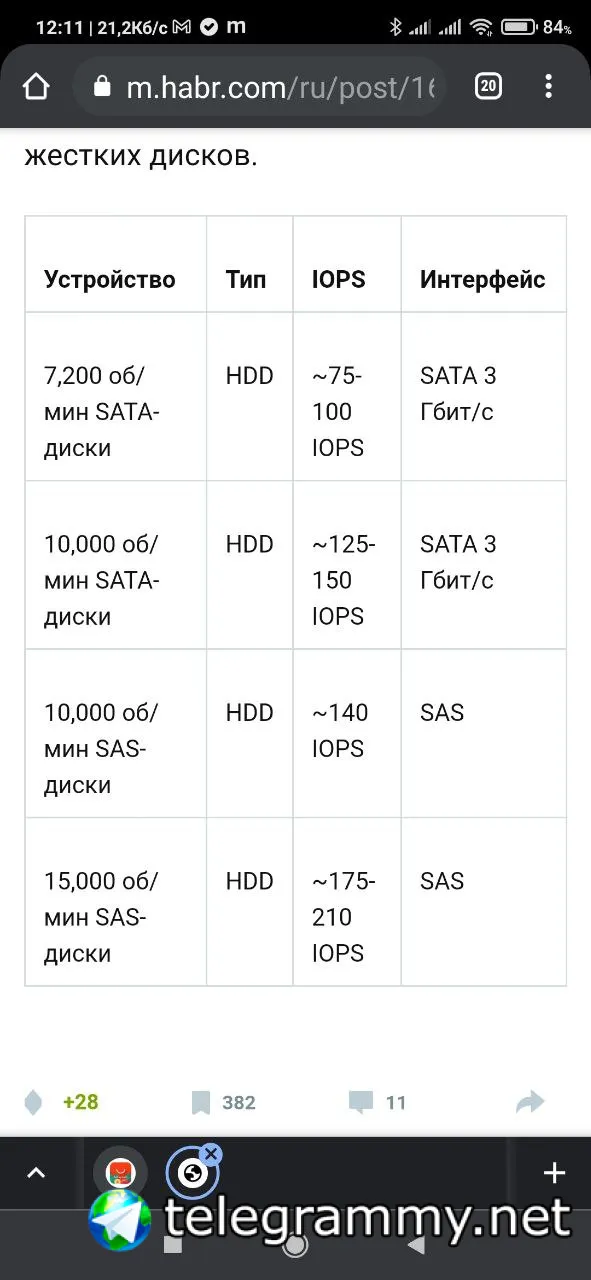 Василий
Василий
Но это 12 год
Fedor
https://t.me/ru_zfs/15588
Fedor
Бгг
Василий
Тут же зфс
Василий
винты как вино, с годами иопсов только больше выдают
Ссд как всего. С каждым годом... Ну и остальной бред
Fedor
Из тех обсуждений можно извлечь ряд краеугольных камней такого решения
Сергей
Проблемы ещё и в доступных иопсах- тут это тоже обсуждали
для меня это некритично. Там будут ПГ совсем хилые и для несложных запросов - это тестовые ПГ, нагрузка почти никакая
Василий
Так. Это ты к какому из тредов тут?
Я? Речь шла про иопсы диска. Hdd сейчас около 200+ выдают, если современные