а че только на HDD?
На ссд фрагментация не так аффектит, только на том что для фрагментированного чтения диску нельзя промежуток запросить, а придётся несколько промежутков, в остальном на ссд задержки дополнительной, как у хдд на позиционирование, нет
 George
George


 Василий
Василий
спектрум были: 16кб и 48кб версии. потом появилась 128кб версия
 Fedor
Василий
Fedor
Василий
На ссд фрагментация не так аффектит, только на том что для фрагментированного чтения диску нельзя промежуток запросить, а придётся несколько промежутков, в остальном на ссд задержки дополнительной, как у хдд на позиционирование, нет
до 50 раз потеря скорости это не эффектит?? нвме, самсунг 970 про
George
до 50 раз потеря скорости это не эффектит?? нвме, самсунг 970 про
Не должно так быть, скорее не догрели на тестах, 50раз я только на непрогретых тестах видел когда диск ещё может выдавать максимальные значения. Есть тесты в паблике?
Fedor
спектрум были: 16кб и 48кб версии. потом появилась 128кб версия
Так я ж не про спектрумы, а про извечный мем :)
George
до 50 раз потеря скорости это не эффектит?? нвме, самсунг 970 про
Если мы про чтение, конечно
Fedor
Не должно так быть, скорее не догрели на тестах, 50раз я только на непрогретых тестах видел когда диск ещё может выдавать максимальные значения. Есть тесты в паблике?
Кстати, неизвестно, будут ли в зфс оптимизации под быстрые накопители?
George
Я щупал нвме, которые при первом чтении дают 3000мбайт/сек, а после перезаписи не важно как - не более 1000мбайт/сек
Василий
Не должно так быть, скорее не догрели на тестах, 50раз я только на непрогретых тестах видел когда диск ещё может выдавать максимальные значения. Есть тесты в паблике?
это не тесты. это спецификация. линейное чтение 3.5гб\с, рандом 15к опс по 4кб - итого 60 мб/с
Василий
но да, это плохой рандом - очередь 1.
Fedor
Ну кто ж сейчас по 4кб читает :)
George
это не тесты. это спецификация. линейное чтение 3.5гб\с, рандом 15к опс по 4кб - итого 60 мб/с
Так вопрос размера блока
George
Рандомное чтение 1мб блоком будет примерно как линейное
George
Мало кто умеет последовательное чтение 4к блоком дотянуть до идентичной скорости чтение 1мб блоком, тут бессмысленно на спеку смотреть
Fedor
Минималка обычно 8 - да и то, в бд
George
Кстати, неизвестно, будут ли в зфс оптимизации под быстрые накопители?
Конечно, сейчас direct io прикручивают к arc именно для nvme
Fedor
👏👏👏
Василий
Минималка обычно 8 - да и то, в бд
фрагменить оно будет тем размером, которым бд будет синкать
Fedor
фрагменить оно будет тем размером, которым бд будет синкать
Которым ты укажешь в рекордсайзе:)
 Владимир
Владимир
Ну как скомпилишь
хотел тебя обломать
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_log_write_ahead_size
а там 8 оказывается, что за ерунда)), ну я вообще для наглядности прописываю 16))
Fedor
Хотя у нас терминология неидентичная- можем друг друга неправильно понимать
Василий
Которым ты укажешь в рекордсайзе:)
ll files are stored either as a single block of varying sizes (up to the recordsize) or using multiple recordsize blocks.
Василий
up to, а не точно
Fedor
Чем я занимаюсь в выходной, а 😁
Василий
хотя на больших файлах, скорей всего да, будет менять рекордсайзами
Василий
делать рекордсайз отличный от размера блока которыми оперирует скл - так себе решенгие
Fedor
Вот вот
Василий
"If you're running a MySQL database on an SSD using ZFS, you should go change your datasets's record record size to 16k. If however, you are running a media server on traditional HDDs, then you are probably fine on the default 128k, or may wish to increase it to 1MB but don't expect any massive performance boost"
Василий
итого, в зависимости от характера нагрузки, потеря скорости до 12 раз (реально конечно меньше)
Fedor
Стораджи всегда меряются в иопсах)
Василий
Линейное чтение - это циферка практически бесполезная
сильно от характера нагрузки зависит. как не странно, зфс, с отключенным синком по иопсам обходит честный ext4, но виртуалки на нем, все равно работают медленее
 Alexander
Alexander
Он помечает страницы как свободные
Например, в Db2 реально переносит данные (убирает фрагментацию на уровне файлов) и перестраивает индексы например по кластерному ключу - команда REORG, на большой базе и на слабом оборудовании она может фигачить всю ночь еженочно, а если пропустить недельку, то тогда вообще целые сутки или больше.
Fedor
Fedor
Да и мускуль не знаю практически
Василий
кстати, мсскл если не ребилдить и не паковать, тормоза через неделю на ссд сторе начинаются нехилые
Fedor
Профилирование проводилось? В чем причина?
Fedor
А про производительность решений - я даже в лвм в горлышко умудрился упереться 😁
Fedor
Лвм дольше обрабатывал ио, чем стораджи
Василий
Профилирование проводилось? В чем причина?
не, просто план написали: ночные "по чуть чуть" и выходные полный ребилд. про неделю я чуть загнался. если пару недель не было - то тормоза. собсно, в до забиксовые временя так и определяли что "что то поломалось")
Василий
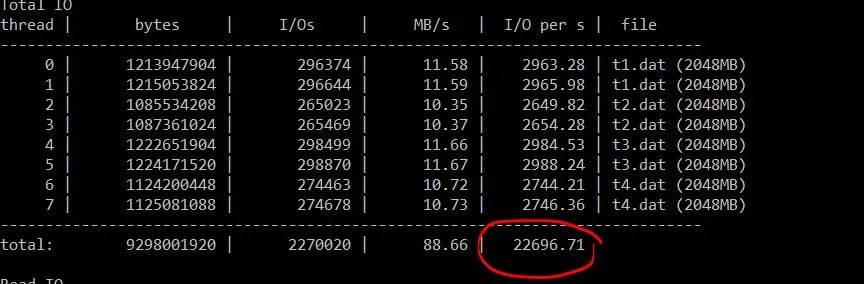 Василий
Василий
на дико тормозном, в плане работы, томе
George
Лвм дольше обрабатывал ио, чем стораджи
И на служебных операциях лвм тоже даёт аффект, кстати
Василий
Те самые, даже на линейном чтении размер блока решает
как? оно ж линейно читает. за раз по максимуму. иначе это уже не линейное чтение.
George
как? оно ж линейно читает. за раз по максимуму. иначе это уже не линейное чтение.
количеством запросов на чтение же, 4к и 1М, в 256 раз больше запросов
George
линейное чтение = последовательное, не более. Именно по этой причине без размера блока и других параметров измерять в "мб/сек" бессмысленно
Василий
количеством запросов на чтение же, 4к и 1М, в 256 раз больше запросов
линейное - это прочитай мне дофига. а то что у тебя рандом последовательный это все равно не линейное
George
George
4к линейное чтение не перестаёт быть линейным изза размера блока
George
и (сюрприз) т.к. на классических фс размер блока обычно 4к, то большинство приложений не умеет эффективно читать последовательно. Тут им на помощь приходят префетчеры ОС, если они смогли эвристикой распознать нужный паттерн
George
так что отсутствие фрагментации помогает только в очень частных случаях, когда само приложение хочет линейный доступ, но не умеет обращаться большим блоком
Василий
4к линейное чтение не перестаёт быть линейным изза размера блока
а что такое линейное чтение? :)
Василий
хабр утверждает: Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К).
George
Василий
https://habr.com/ru/post/164325/
George
хабр утверждает: Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К).
ну даже в том куске, который вы процитировали, явно говорится про последовательный доступ к блокам
Василий
George
а, если прочитать дальше статью, то там явно говорится
Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К). При произвольных операциях данные читаются случайно из разных областей носителя, обычно они ассоциируются с размером блока 4 Кбайт.
обычно
George
это мы за скобками оставляем, что я могу сейчас подредактировать свою статью на хабре и на неё быстренько сослаться как подтверждение)
George
в общем последовательный доступ не обязует иметь какой-то конкретный размер блока
Василий
а, если прочитать дальше статью, то там явно говорится
Под линейными операциям чтения/записи, при которых части файлов считываются последовательно, одна за другой, подразумевается передача больших файлов (более 128 К). При произвольных операциях данные читаются случайно из разных областей носителя, обычно они ассоциируются с размером блока 4 Кбайт.
обычно
жду ваш вариант определения последовательного со любой ссылкой на статью )
Василий
в общем последовательный доступ не обязует иметь какой-то конкретный размер блока
чем он тогда от случайного будет отличаться?
George
жду ваш вариант определения последовательного со любой ссылкой на статью )
https://en.wikipedia.org/wiki/Sequential_access
George
даже картиночка есть
George
😁
 central
central
последовательное это чтение блоков один за другим: блок N, N+1, N+M где M количество блоков, рандомное чтение, это чтение в случайном порядке, хз, зачем сюда приплетать recordsize и все остальное
Fedor