 central
central


 bes
bes
я его удалил, начало писать что ошибка в subvol, до этого указывало точный путь к файлу
central
маловероятно что это друг с другом связано
bes
 bes
bes
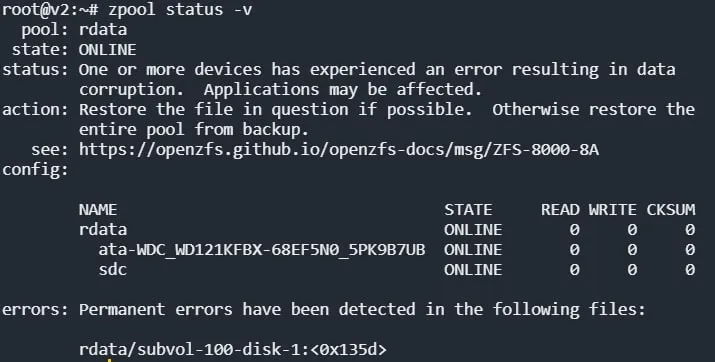
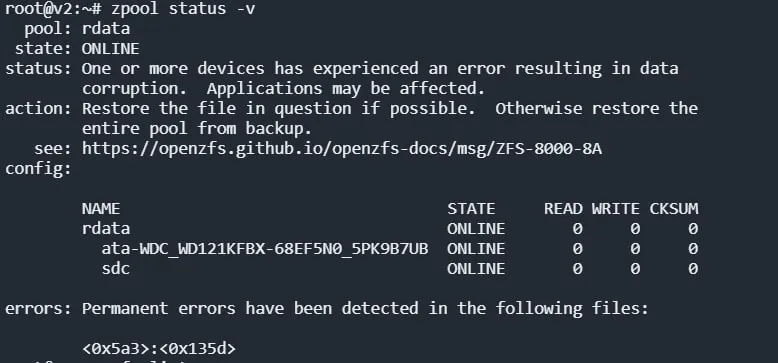
вот ссылка из сообщения https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A/
 Δαρθ
Δαρθ
вот кстати чем плох zfs. если б он не указывал что есть потерянные данные, то и не заметил бы. а теперь неспокойно как-то 😃
чтоб спокойно, миррор или раидз* :)
bes
kernel:[18533.754857] PANIC: zfs: adding existent segment to range tree (offset=3787b011000 size=120000)
Да что ж такое. Что-то много багов для 12 лет эксплуатации, как кое-кто там рекламировал...
 Dmitry
Dmitry
вообще не хороший опыт пока что получается: pool создан 20 часов назад, запись на 60% утилизации дисков 60%/40% read/write и уже приехали
А можно подробнее, как вы её так ушатали? Какая система, версии, профиль нагрузки, состояние дисков
 nAHKPATOB
nAHKPATOB
Кто знает куда написать про баг в зфс, у меня повторилась ситуация с потерей места уже на второй машине?
nikolay
В багтреккер писать. а что за ситуация, можете рассказать или дать ссылку?
 Fedor
Fedor
Как определили потерю места? Может, неудаленные снапшоты?
bes
А можно подробнее, как вы её так ушатали? Какая система, версии, профиль нагрузки, состояние дисков
Значит что я пробовал.
1. Proxmox 6 (kernel-5.4.114, zfs-kmod-2.0.4), диски новые WD121KFBX-68EF5N0 (12.0TB, CMR, гонялись badblock -w), zpool (raid0, sync=standard, compression=lz4), дальше всё стандартными средствами proxmox: контейнер lxc и mount rdata/subvol-100-disk-0 type zfs (rw,xattr,posixacl).
поставил копироваться бэкапы (4TB мелких файлов) на ночь и утром:
kernel:[18533.754857] PANIC: zfs: adding existent segment to range tree (offset=3787b011000 size=120000)
дальше call trace
zpool после перезагрузки не импортируется
не дебажил дальше
2. всё тоже самое только полноценная qemu и zfs subvol как блочное внутри, где поверх создан gpt и ext4. dd в файл без ошибок записало где-то 6TB. поставил бэкапы на ночь и утром:
kernel:[17495.851378] PANIC: blkptr at 0000000056257076 has invalid BLK_BIRTH 0
[17642.502124] INFO: task zvol:21998 blocked for more than 120 seconds.
[17642.502145] zvol D 0 21998 2 0x80004000
дальше call trace
Нужно видимо признать, что zfs на этой конкретной машине не работает, хотя никаких претензий к ней не было за последние 5 лет в связке mdadm-lvm2-ext4, но с другими дисками.
Alexander
Добрый день
Alexander
Пожалуйста, подскажите, как склонировать со снэпшота snap2 и при этом сохранить снэпшоты snap3, snap4 и т.д., только без rsync и пересоздания новых снэпшотов.
Alexander
Например, есть dataset: system/rootfs
Alexander
снэпшоты: snap1, snap2, snap3, ....
Alexander
Делаю zfs clone system/rootfs@snap2 system/rootfs_clone
Alexander
Далее как мне получить снэпшоты snap3, snap4, ... на новом клоне system/rootfs_clone ?
Alexander
Или это новый dataset и снэпшоты могут быть тоже только новые?
 George
George
Значит что я пробовал.
1. Proxmox 6 (kernel-5.4.114, zfs-kmod-2.0.4), диски новые WD121KFBX-68EF5N0 (12.0TB, CMR, гонялись badblock -w), zpool (raid0, sync=standard, compression=lz4), дальше всё стандартными средствами proxmox: контейнер lxc и mount rdata/subvol-100-disk-0 type zfs (rw,xattr,posixacl).
поставил копироваться бэкапы (4TB мелких файлов) на ночь и утром:
kernel:[18533.754857] PANIC: zfs: adding existent segment to range tree (offset=3787b011000 size=120000)
дальше call trace
zpool после перезагрузки не импортируется
не дебажил дальше
2. всё тоже самое только полноценная qemu и zfs subvol как блочное внутри, где поверх создан gpt и ext4. dd в файл без ошибок записало где-то 6TB. поставил бэкапы на ночь и утром:
kernel:[17495.851378] PANIC: blkptr at 0000000056257076 has invalid BLK_BIRTH 0
[17642.502124] INFO: task zvol:21998 blocked for more than 120 seconds.
[17642.502145] zvol D 0 21998 2 0x80004000
дальше call trace
Нужно видимо признать, что zfs на этой конкретной машине не работает, хотя никаких претензий к ней не было за последние 5 лет в связке mdadm-lvm2-ext4, но с другими дисками.
в баг трекере что-то на эту тему было, конкретно с релизом 2.0.4, в 2.0.5 фиксы по идее приедут, либо 0.8.6, там этих проблем нет.
Увы, 2.0 релиз ещё свежеват, проксовцы имхо поторопились
George
Или это новый dataset и снэпшоты могут быть тоже только новые?
именно, клон - уже новая сущность изменяемая, только если клониться от последнего нужного снапа
George
а почему не сразу от последнего снапа то клониться?
nikolay
в баг трекере что-то на эту тему было, конкретно с релизом 2.0.4, в 2.0.5 фиксы по идее приедут, либо 0.8.6, там этих проблем нет.
Увы, 2.0 релиз ещё свежеват, проксовцы имхо поторопились
опередил меня) я только хотел ответить что лучше не использовать 2.0.. интересно, в Proxmox 2.0.4 разве встроенный? или автор обновлял руками?
Alexander
именно, клон - уже новая сущность изменяемая, только если клониться от последнего нужного снапа
А хотя бы старые снэпшоты в клоне нельзя увидеть?
George
А хотя бы старые снэпшоты в клоне нельзя увидеть?
что значит нельзя увидеть? клон будет являться отображением конкретного снапа
Alexander
а почему не сразу от последнего снапа то клониться?
Последний содержит состояние системы после небольшой аварии.
George
Последний содержит состояние системы после небольшой аварии.
тогда только последний перед аварией брать и докатывать частично что вам нужно, либо наоборот - брать снап с аварией и проблемные места из старых снапов достать
Alexander
опередил меня) я только хотел ответить что лучше не использовать 2.0.. интересно, в Proxmox 2.0.4 разве встроенный? или автор обновлял руками?
А когда примерно можно будет переходить на 2.0.latest? Когда будет самый последний релиз 2.0.x ? Типа 0.7.12/13
bes
в баг трекере что-то на эту тему было, конкретно с релизом 2.0.4, в 2.0.5 фиксы по идее приедут, либо 0.8.6, там этих проблем нет.
Увы, 2.0 релиз ещё свежеват, проксовцы имхо поторопились
Сейчас что-то с бэкапами придумаю и буду воспроизводить, дебажить, писать багрепорты :)
George
А когда примерно можно будет переходить на 2.0.latest? Когда будет самый последний релиз 2.0.x ? Типа 0.7.12/13
я около года обычно жду, плюс баг трекер смотрю
George
примерно похоже политике дебиана
George
на то оно и стейбл
bes
опередил меня) я только хотел ответить что лучше не использовать 2.0.. интересно, в Proxmox 2.0.4 разве встроенный? или автор обновлял руками?
Всё только по мануалу. Видимо уже стантартный
Alexander
тогда только последний перед аварией брать и докатывать частично что вам нужно, либо наоборот - брать снап с аварией и проблемные места из старых снапов достать
Хотел просто на память сохранить состояние после аварии с историей снэпов для разбора полетов потом.
Получается клоном никак, только если делать копию через send | receive ?
Alexander
я около года обычно жду, плюс баг трекер смотрю
Т.е. даже на 0.8.6 еще рановато переходить?
George
0.8.6 для 0.8 ветки как раз маст хев, он баги только и фиксит
Alexander
что значит нельзя увидеть? клон будет являться отображением конкретного снапа
Хотелось бы историю снэпов, а не просто состояние в последнем снапе.
George
Хотелось бы историю снэпов, а не просто состояние в последнем снапе.
просто оставить их на месте?
Alexander
просто оставить их на месте?
Дело в том, что на оригинале я уже откатился назад, исправил, что хотел, теперь надо бэкапить, но хотелось бы на сервере бэкапов сохранить поставарийное состояние в отдельной ветке, и бэкапить (реплицировать) со старого снэпа snap2, но уже новыми данными.
Alexander
А копировать целиком датасет на бэкап сервере - это очень много по объему для меня по крайне мере.
Alexander
Наверно тогда как вариант rsync-ом можно скопировать поставарийные снэпшоты.
Alexander
В buster-backports зачем-то запихали v2.0.3
Alexander
https://packages.debian.org/search?suite=buster-backports&searchon=names&keywords=zfs
bes
Конечно не исключаю, что дело в дисках, ну условно шлейфы другие взял и т.п, но вообще опыт с zfs пока что сумбурный из 5 дней знакомства с ней. По ощущениям этакий ceph (куча тумлеров и настроек), но локальный.
bes
да, это какой-то старенький asus + i3-2120, хорошо работал на всех kernel 4.1-5.10
Ivan
да, это какой-то старенький asus + i3-2120, хорошо работал на всех kernel 4.1-5.10
мб асус не может работать с таким большим диском нормально ?
bes
вся история заканчивалась на 500-600Gb записи на каждый диск
Dmitry
в баг трекере что-то на эту тему было, конкретно с релизом 2.0.4, в 2.0.5 фиксы по идее приедут, либо 0.8.6, там этих проблем нет.
Увы, 2.0 релиз ещё свежеват, проксовцы имхо поторопились
Поддержу, 2.0 ещё сыровата. Тестировал её под FreeBSD, нативное шифрование работает медленнее, чем GELI
bes
кроме этого никакх dmi error в dmesg не свалилось
bes
ну тут нужно попробовать разные версии ядра и zfs, я просто рассказал как бывает
bes
сейчас сделал на mdadm+ex4 и в lxc как shared mount наливаю снова те же данные, потом чексуммами сверюсь
Δαρθ
мб асус не может работать с таким большим диском нормально ?
вывод выглядит сомнительно (какое дело материнке и контроллеру сата до РАЗМЕРА диска?) но проверить корректность записи больших объёмов инфы на диск можно. убив данные. грубо говоря, надо зашифровать /dev/zero при помощи openssl (c -nosalt) и записать на диск
Δαρθ
потом посчитать md5sum того что он шифрует (отдельно в сторонке, по размеру диска) и считать мд5 с диска тоже
Δαρθ
-nosalt чтоб каждый раз одно и то же шифровалось
 Василий
Василий
вывод выглядит сомнительно (какое дело материнке и контроллеру сата до РАЗМЕРА диска?) но проверить корректность записи больших объёмов инфы на диск можно. убив данные. грубо говоря, надо зашифровать /dev/zero при помощи openssl (c -nosalt) и записать на диск
эх юность :) были раньше и такие проблемы )
Ivan
вывод выглядит сомнительно (какое дело материнке и контроллеру сата до РАЗМЕРА диска?) но проверить корректность записи больших объёмов инфы на диск можно. убив данные. грубо говоря, надо зашифровать /dev/zero при помощи openssl (c -nosalt) и записать на диск
много материнок, которые обрезают размер партиций до 2ТБ, встречал как-то проблему даже с обрезанием до 1ТБ.
Ivan
мы ж говорим о стареньком железе
Δαρθ
эх юность :) были раньше и такие проблемы )
у меня была проблема конкретно с глючным сата контроллером (или мамкой) еще на pci. но там очевидно размер диска не ролял, просто связка мамка+контроллер портили иногда данные
Ivan
еще на десктоп железе память не ecc, что может прибавить проблем
Δαρθ
а что касается ограничений CHS, bios, LBA28 и LBA48 -- ну какбэ было такое на IDE, но не думаю что в i3 чтото из этого осталось
Василий
у меня была проблема конкретно с глючным сата контроллером (или мамкой) еще на pci. но там очевидно размер диска не ролял, просто связка мамка+контроллер портили иногда данные
не, были в свое время матери, которые больше определенного размера не видели. некоторые просто висли...
Δαρθ
Василий
на сате?
вот этого не помню :( помню, что видела 500мб, куда я винду всунул, а винда уже видела оставшиеся 1.2гб )))
Василий
скорей всего иде
Δαρθ
вот этого не помню :( помню, что видела 500мб, куда я винду всунул, а винда уже видела оставшиеся 1.2гб )))
что какбэ намекает что проблема была в софте (в биосе) а не в железе )
Δαρθ
ИДЕ контроллеру такто по барабану было, цхс или лба, и сколько бит лба
Василий
что какбэ намекает что проблема была в софте (в биосе) а не в железе )
там где "висло" там от этого не легче. но да, проблема софтовая. согласен
Василий
А кто какой рекорд сайз для виртуалок ставит? Не бд. Среднестатические вм
 Сергей
Сергей
А кто какой рекорд сайз для виртуалок ставит? Не бд. Среднестатические вм
вы ставите виртуалки как qcow2 файлы внутри обычной filesystem?
я так ни разу не делал, в основном zvol. С размером 8к / 16к
Василий
Василий
Теоретически, нфс может работать большими блоками, что уменьшает фрагментаци
Autumn
Джентльмены, викторина на один вопрос, попалась хранилка с 8 ssd производителя STEC (прикидывается как hgst). Перед конфигурацией как обычно проверил размер сектора для выбора ashift и опаньки там судя по fdisk -l и cat /sys/block/ssd/queue/physical_block_size реальные 512. Кто мутил на ссд ashift=9 признавайтесь, деградации не будет или лучше вкатать 12 и не парится. В этой же хранилке диски, и там все как обычно 512e с реальным 4к. Никогда еще не встречал ссд с физсектором в 512.
Autumn
STEC S842E2000M2 2TB
Autumn
по даташиту тоже пишут что 512
bes
Так потестите где у них деградация по скорости начинается