 Igor
Igor


это после ребута сбрасывается!
 George
George
это после ребута сбрасывается!
пропиши чтоб не сбрасывалось :) https://openzfs.github.io/openzfs-docs/Performance%20and%20Tuning/ZFS%20on%20Linux%20Module%20Parameters.html#zfs-on-linux-module-parameters
riv
это после ребута сбрасывается!
Так все сбрасывается, если в modprobe к модулю zfs параметром не добавить.
Igor
спасибо
Igor
понял
Igor
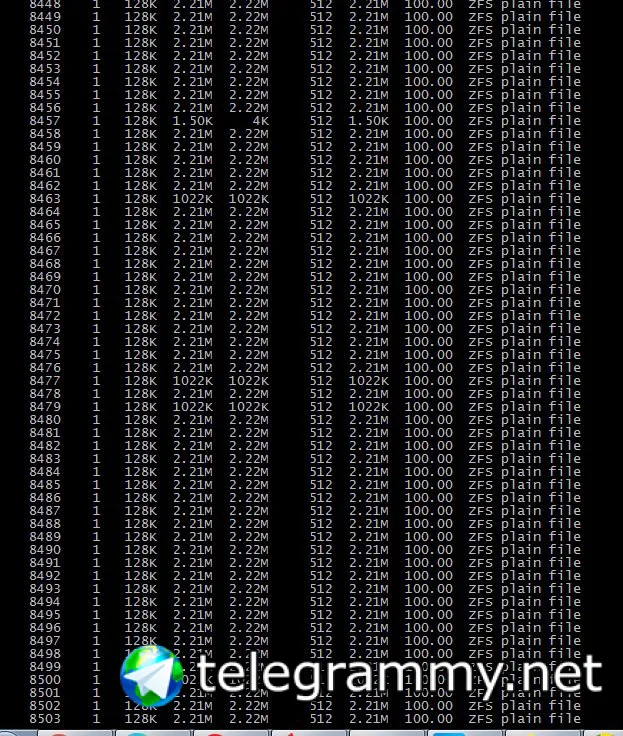
юзаю такой рекорд ибо файлы по 2.4мега. миллионы
George
А в каких случаях нужны такие огромные рекордсайзы и что они дают?
меньше меты, лучше сжатие, есть смысл когда доступ к файлам гарантированно не меньшим размером блока идёт
George
ну и фрагментация меньше в теории
riv
юзаю такой рекорд ибо файлы по 2.4мега. миллионы
Не будет ли 128к лучшем выбором? потери на контрольных суммах не значительные, а если файл 2 мега, ещё два в помойку?
George
Не будет ли 128к лучшем выбором? потери на контрольных суммах не значительные, а если файл 2 мега, ещё два в помойку?
если файл меньше recordsize, то он запишется фактическим объёмом, iirc
George
плюс если сжатие включено, оно успешно сожмёт разницу в последнем блоке для случая, если у файла больше одного блока
Igor
Не будет ли 128к лучшем выбором? потери на контрольных суммах не значительные, а если файл 2 мега, ещё два в помойку?
так компрессия туда ж запихает еще файлов
George
так компрессия туда ж запихает еще файлов
легко проверяется, если что, можете inode взять и через zdb проверить размер записанного
riv
Хороший диск 7500RPM дает в худшем случае 100IOPS на случайном доступе, а в лучшем 400IOPS (за один оборот, он может сделать несколько операций), с другой стороны, его линейная скорость в среднем около 100МБ/сек. А значит, что при блоках в от 128К до 1МБ, влияние фрагментации на скорость не значительное.
Но зато, при чтении, и записи всегда придется считывать и записывать огромные блоки.
Просто я тестировал на больших файлах и пришел к выводу, что больше 128к не имеет смысла. Во и интересуюсь, какие именно плюшки выстрелили в таком сценарии?
Igor
 Igor
Igor
я так понял юзается все на 100%?
riv
я так понял юзается все на 100%?
А сравнивали производительность со 128к блоками? Действительно лучше?
Igor
не я, это делал Krey в своей феноменальной исследовательской работе. Я просто мимикрирую и доверяю его опыту
George
Хороший диск 7500RPM дает в худшем случае 100IOPS на случайном доступе, а в лучшем 400IOPS (за один оборот, он может сделать несколько операций), с другой стороны, его линейная скорость в среднем около 100МБ/сек. А значит, что при блоках в от 128К до 1МБ, влияние фрагментации на скорость не значительное.
Но зато, при чтении, и записи всегда придется считывать и записывать огромные блоки.
Просто я тестировал на больших файлах и пришел к выводу, что больше 128к не имеет смысла. Во и интересуюсь, какие именно плюшки выстрелили в таком сценарии?
ну я выше написал, что смысл есть только если гарантированно таким же блоком или бОльшим доступ осуществляется. Либо когда сжатие важнее эффективности доступа
George
если доступ меньшим блоком, то дефолтные 128К отлично ложатся на физику hdd
 Nikolay
Nikolay
не стоит этим механизмом пользоваться просто так.
Можно просто special раздел делать в начале диска, потом при надобности сносится slog l2arc, раздел увеличивается руками, делается autoexpand на vdev, профит
Но ручками это же удалить раздел и создать заного. В это время pool не дееспособен ?
riv
Но ручками это же удалить раздел и создать заного. В это время pool не дееспособен ?
Дееспособен, если речь про log и cache, а вот special не получится удалить без перемещения в пул, а это не хорошо.
George
Но ручками это же удалить раздел и создать заного. В это время pool не дееспособен ?
работоспособен, меняется только информация в таблице разделов что "1й раздел не с блока 1 по 10, а по 100500"
George
"удаление" раздела из таблицы разделов gpt не приводит к обнулению значений непосредственно блоков
riv
"удаление" раздела из таблицы разделов gpt не приводит к обнулению значений непосредственно блоков
Но действуя вручную, важно не ошибиться потом. Но, кстати, а что происходит с блочным устройством при перечитывании таблиц разметки диска?
George
Но действуя вручную, важно не ошибиться потом. Но, кстати, а что происходит с блочным устройством при перечитывании таблиц разметки диска?
ну это стандартный метод увеличения раздела с любой фс рабочий. Тонкости проще на тесте посмотреть, я не углублялся
riv
ну это стандартный метод увеличения раздела с любой фс рабочий. Тонкости проще на тесте посмотреть, я не углублялся
Вот вот. Мне что-то кажется, что не растянется раздел, пока система не удалит связанное с ним блочное устройство.
Я тоже не проверял, т.к. использую LVM 😊
George
Вот вот. Мне что-то кажется, что не растянется раздел, пока система не удалит связанное с ним блочное устройство.
Я тоже не проверял, т.к. использую LVM 😊
я и ext и zfs так растягивал. lvm по тому же принципу должен действовать.
Nikolay
У меня глупый вопрос: сделал я разделы под спец и слог. Но ни под какую ФС не форматирую их. Когда добавлю в пул, разделы автоматом станут zfs ? или их обязательно предварительно под что-то надо форматнуть ?
 Qwerty
Qwerty
@gmelikov Поставил на ресильвер свой пул
8.92G resilvered, 0.52% done, 14:27:51 to go
George
George
@gmelikov Поставил на ресильвер свой пул
8.92G resilvered, 0.52% done, 14:27:51 to go
кинь плиз результат потом
Qwerty
Ну и я бы не сказал что черепашья скорость
scan: resilver in progress since Wed Sep 23 09:15:00 2020
2.04T scanned at 4.14G/s, 70.4G issued at 143M/s, 7.17T total
16.6G resilvered, 0.96% done, 14:27:01 to go
George
Ну и я бы не сказал что черепашья скорость
scan: resilver in progress since Wed Sep 23 09:15:00 2020
2.04T scanned at 4.14G/s, 70.4G issued at 143M/s, 7.17T total
16.6G resilvered, 0.96% done, 14:27:01 to go
в начале ресильвера с 0.8 версии теперь есть шаг последовательного чтения меты чтоли, он то быстрый)
Qwerty
Я ожидал худшего от SMR дисков
George
медленно станет после 50% где-то)
riv
У меня глупый вопрос: сделал я разделы под спец и слог. Но ни под какую ФС не форматирую их. Когда добавлю в пул, разделы автоматом станут zfs ? или их обязательно предварительно под что-то надо форматнуть ?
ничего с разделами делать не нужно. Просто zpool add my_zfs_pool special mirror /dev/sdXy /dev/sdZm или zpool add my_zfs_pool slog mirror /dev/sdZx /dev/sdYq и т.д
riv
Я ожидал худшего от SMR дисков
Заполните диск до отказа и удалите часть данных, потом повторите тест. Я боюсь, что результат может быть в разы, а то и на порядок хуже.
George
50% ресильвера?
ага, когда "issued" дойдёт до 100% от размера, то начнётся самый больной этап ресильвера
Qwerty
Заполните диск до отказа и удалите часть данных, потом повторите тест. Я боюсь, что результат может быть в разы, а то и на порядок хуже.
А как я его заполню, если у меня raidz1? Вроде должно равномерно размазывать?
Qwerty
Это мне нужно пул забивать
ValkraS
Всем доброго, Вопрос.
При создании zvol для виртуалки нужно указывать дополнительные параметры или достаточно по умолчания значений?
ashift=13
VM - Windows guest
Перерыл уже много ресурсов - ответа не нашел (
ValkraS
"zfs create -V 1T rpool/vms" к примеру?
George
Всем доброго, Вопрос.
При создании zvol для виртуалки нужно указывать дополнительные параметры или достаточно по умолчания значений?
ashift=13
VM - Windows guest
Перерыл уже много ресурсов - ответа не нашел (
volblocksize можно по вкусу покрутить, но тут зависит от предполагаемого профиля нагрузки
ValkraS
volblocksize можно по вкусу покрутить, но тут зависит от предполагаемого профиля нагрузки
нагрузка до 20 человек, офис + немного 1С файлового но много файлов и поиск по контексту )
ValkraS
volblocksize можно по вкусу покрутить, но тут зависит от предполагаемого профиля нагрузки
то есть его ставить или 8к или больше? и там уже в самой системе с этим "подставлять" я правильно понимаю?
George
то есть его ставить или 8к или больше? и там уже в самой системе с этим "подставлять" я правильно понимаю?
ну он по умолчанию 8к, уменьшать точно не стоит, увеличивать без нормальных тестов - тоже
ValkraS
ну он по умолчанию 8к, уменьшать точно не стоит, увеличивать без нормальных тестов - тоже
это я тоже понял, но при создании гостя, винда ставит по умолчанию свой в 4к, а это удваивает место занимаемое файлами по блокам? точней данные по факту будут занимать в 2 раза больше места в zvol - или я что-то недопонял?
George
это я тоже понял, но при создании гостя, винда ставит по умолчанию свой в 4к, а это удваивает место занимаемое файлами по блокам? точней данные по факту будут занимать в 2 раза больше места в zvol - или я что-то недопонял?
нет, но для доступа к одному из 4к блоков zfs прочитает/запишет весь 8к. Т.е. 8к volblocksize содержит 2 4к блока ntfs, если на пальцах.
George
в ntfs можно размер блока изменить при желании
George
но, опять же, надо тестить, у меня такой статистики нет, не держу винду
ValkraS
но, опять же, надо тестить, у меня такой статистики нет, не держу винду
Понял, благодарю, буду пробовать
riv
нагрузка до 20 человек, офис + немного 1С файлового но много файлов и поиск по контексту )
На volblocksize 16k и ntfs unitsize=16k и быстрой SSD, 1С грузится в два раза быстрее, чем радует бухгалтеров. У меня такая разница на optane возникает.
ValkraS
На volblocksize 16k и ntfs unitsize=16k и быстрой SSD, 1С грузится в два раза быстрее, чем радует бухгалтеров. У меня такая разница на optane возникает.
на NVME должно быть быстрей, в принципе если pool уже 8к то указав при создании zvol 16k он его override-т так?
riv
то есть его ставить или 8к или больше? и там уже в самой системе с этим "подставлять" я правильно понимаю?
Забыл добавить, в файловой 1С тоже размер записи 16 нужно сделать, вот так:
CNVDBFL.EXE -c -f 8.3.8 -p 16k С:\<путь к файлу>\1Cv8.1CD
riv
на NVME должно быть быстрей, в принципе если pool уже 8к то указав при создании zvol 16k он его override-т так?
просто будет записывать и считывать минимум по 2 8к блоков. Но самое важное, что 1с будет работать с 16к блоками.
ValkraS
ValkraS
просто будет записывать и считывать минимум по 2 8к блоков. Но самое важное, что 1с будет работать с 16к блоками.
у них и 7.7 еще файловая.... ей это уже врядли поможет )))
ValkraS
там же и так всё быстро?
пока работали по сети, не очень.. сейчас перевожу на терминал ZFS + NVME )
riv
пока работали по сети, не очень.. сейчас перевожу на терминал ZFS + NVME )
вы по копайте в сторону recordsize у семерки. Может быть как-то так-же делается. Если накопаете, мне тоже интересно 😊
ValkraS
Nikolay
Добавил slog и special. Получил такие результаты. Мне опять кажется что мало 😄 Хотя синхронная была на уровне 4 Мб/с , а случайная вроде не изменилась. Для hdd пула большего ожидать уже нельзя ?🤔
Nikolay
Nikolay
Nikolay
Nikolay
Nikolay
Nikolay
Просто ваши тесты смотришь - 300-400 Мб/с 🤔
riv
Ещё бы atop во время теста и конфигурацию пула.
Вангую, что на синхронной записи всё уперлось в slog ssd perfomance. Почему бы под эту нагрузку, требующую полностью синхронную запись, не сделать просто ssd-пул?
С моей точки зрения, zfs спроектирована не для того, чтобы мерить синхронную запись. Все ухищрения с CoW и журналами, slod, special и т.д., дающие серьёзный оверхед, но позволяют опереться на writeback и безопасно* увеличить длинну очередей к дискам. При этом, случайная запись становится более линейной и многократно возрастает производиьельность.
special нужен, чтобы случайная запись стала почти полностью линейной и чтобы разгрузить vdev-ы пула от случайных операций с метаданными, а slog чтобы улучшить латентность и сделать так, чтобы синхронные операции не ухудшали производительность пула для других клиентов.
Эти тесты, на мой взгляд, не показывают результаты от реальной нагрузки в реальных ситуациях. По тому, что в реальности у вас будет смесь небольшого количества синхронных операций и остальные будут фактически в режиме writeback CoW, что драматически повышает быстродействие.
* - безопасно, значит не разрушится при сбое, но не синхронные операции могут откатится к более раннему, но консистентному состоянию.
 Сергей
riv
Сергей
riv
zfs очень хорошо подходит для СУБД и хранения образов ВМ. В этих обоих вариантах синхронная запись очень важна.
Важна, но не всегда нужна. Тут была очень большая дискуссия по этому поводу.
Вот нашел. Кому интересно про writeback, sync и т.д., примерно из этого района надо читать: https://t.me/ru_zfs/10402 - там за и против writeback в zfs (sync=disabled) vs (sync=enable/always)
riv
Добавил slog и special. Получил такие результаты. Мне опять кажется что мало 😄 Хотя синхронная была на уровне 4 Мб/с , а случайная вроде не изменилась. Для hdd пула большего ожидать уже нельзя ?🤔
Но я бы сказал, что не вникая в подробности, можно оставить поведение по умолчанию. Но ваш тест не показывает реальную производительность пула. Полностью синхронная запись - это вырожденный случай. В реальности, скорее всего, будет намного быстрее.
Nikolay
Я не гонюсь за пиковой скоростью, но интересно на сколько быстрее с слог меняется запись.
riv
Подскажите, пожалуйста, что (как) именно требуется atop запускать, что показать. Я им никогда не пользовался просто.
Усреднение за 5 сек:
atop 5
Усреднение за 1 сек:
atop 1
Желательно в соседнем окне держать
zpool iostat -v 5
или
zpool iostat -v 1
соответственно доя 5 или 1 секунды. Я думаю, вы поняли, что количество секунд можно ставить любое.