Последний раз когда я пытался пользоватся предпроцесором фасма я пошел и написал скрипи на питоне который выполнял нужные функции
а я лепил костыли макросами для VKdebug
 Aiwan \ (•◡•) / _bot
Aiwan \ (•◡•) / _bot

 Aiwan \ (•◡•) / _bot
Aiwan \ (•◡•) / _bot
кроч, надо разбтраться в анализаторе аргументов средствами fasma
 bilka00
bilka00
а я лепил костыли макросами для VKdebug
Собстна самое обидное что нет отладчика для предпросесора
bilka00
(
Aiwan \ (•◡•) / _bot
Собстна самое обидное что нет отладчика для предпросесора
а он нужен? а если нужен то для каких целей?
 Eugene
Eugene
Сделать сразу везде поддержу такого не получится, я думаю (макросы в fasm вроде не могут возвращать значения).
Можно сделать конкретно для mov, к примеру.
Надо просто взять исходник макроса invoke и переделать под mov.
Aiwan \ (•◡•) / _bot
тоже о таком подумывал
Aiwan \ (•◡•) / _bot
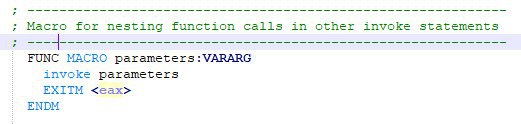 bilka00
bilka00
а он нужен? а если нужен то для каких целей?
У меня была задача кое чо на лету пересчитывать
Aiwan \ (•◡•) / _bot
нарример?
Aiwan \ (•◡•) / _bot
как вариант на ум толко display приходит для просмотра значений
bilka00
Хеши блоков памяти посчитать надо было
bilka00
там есть virtual через которые по идее можно провести подобные вычисления
bilka00
Но я посидел вечерок с кефиром и забил
Aiwan \ (•◡•) / _bot
там есть virtual через которые по идее можно провести подобные вычисления
ты о чистом препроцессоре или о макросах с пекремешкой с кодом?
bilka00
да наверное неверно выразился
Aiwan \ (•◡•) / _bot
а подкинь простенькую (чтоб с карандашом можно было проверить) задачку на эту тему, мож сам покумекаю
Aiwan \ (•◡•) / _bot
можешь в личку
 s54820
s54820
как вариант на ум толко display приходит для просмотра значений
Так есть же prepsrc. Правда, он не слишком понимания добавляет. Но иногда полезен.
Aiwan \ (•◡•) / _bot
prepsrc
что то новенькое, мануал молчит
Aiwan \ (•◡•) / _bot
иль ты про исходник?
s54820
fasm/tools/<платформа>/собираешь, препроцессируешь.
bilka00
а подкинь простенькую (чтоб с карандашом можно было проверить) задачку на эту тему, мож сам покумекаю
Блин, я уже совсем подбностей не помню. Проекты не храню практический.
Aiwan \ (•◡•) / _bot
fasm/tools/<платформа>/собираешь, препроцессируешь.
я так понимаю, утилитка для раскрытия макросов?
bilka00
Задача стояла такая, есть блок в N байт, и нужно посчитать его хеш на этапе сборки
bilka00
Сам тип хеша был не принципиален
Aiwan \ (•◡•) / _bot
билке я думаю не совсем это надо. я думаю ему резульатт нужен сразу после компилиции, типо того. тобишь средствами препроцессора вычисояется его задача
bilka00
Честно говоря не понимаю почему я не нагуглил топик
https://board.flatassembler.net/topic.php?t=3831
bilka00
Но тогда он мне был прям очень нужен, вот
Eugene
Я видел где-то AES шифрование на макросах.
 sc
sc
😃
 Group Butler [beta]
Group Butler [beta]
H͚̓ü̺n̪̬̟ͣho͎̥͆wͧ banned BitMEX Support!
Eugene
Интересно конпиляторы об этом знают?
Давным-давно читал эту статью, но уже забыл. Как раз об этом написано:
Крайне нежелательно смешивать SSE- и AVX-инструкции (в том числе AVX-аналоги SSE-инструкций). Чтобы перейти от выполнения AVX-инструкций к SSE-инструкциям процессор сохраняет в специальном кэше верхние 128 бит AVX регистров, на что может уйти полсотни тактов. Когда после SSE-инструкций процессор снова вернётся к выполнению AVX-инструкций, он восстановит верхние 128 бит AVX регистров, на что уйдёт ещё полсотни тактов. Поэтому смешивание SSE и AVX инструкций приведёт к заметному снижению производительности. Если вам нужна какая-то команда из SSE в AVX-коде, воспользуйтесь её AVX-аналогом с префиксом v.
https://habr.com/ru/post/99367/
Anonymous
Так, а если он ссе и авх2 смешает то в кеш попадут уже 512-128 бит?))
Eugene
Только он слегонца гонит по поводу того, что
Команды загрузки/сохранения выровненных данных vmovaps/vmovapd/vmovdqa требуют, чтобы данные были выровнены на 16 байт, даже если сама команда загружает 32 байта.
При работе с 32 байтами нужно выравнивание именно на 32 байта (аналогично с 64) — это в мане Intel написано.
Ну и...
Сохранения верхней части AVX регистров при переходе к SSE-коду можно избежать, если занулить верхние 128 бит AVX регистров с помощью команды vzeroupper или vzeroall. Несмотря на то, что эти команды зануляют все AVX регистры, они работают очень быстро. Правилом хорошего тона будет использовать одну из этих команд перед выходом из подпрограммы, использующей AVX.
Относительно быстро всё же...
Ryzen: vzeroupper = 10/17, vzeroall = 18/33 такта (32/64 бита)
Sandy Bridge: vzeroupper = 4, vzeroall = 12/20 тактов (32/64 бита)
Skylake: vzeroupper = 4, vzeroall = 25/34 такта (32/64 бита)
 Dolphin
Dolphin
тыш тайминги показываешь )
Eugene
тыш тайминги показываешь )
Это vzeroupper только (и это 1800X).
А так у меня есть новый ноут Ryzen 5 2500U и старый Sandy Bridge.
Там double в SSE/AVX работают пошустрее (правда, single так же 😁) на моём коде.
Eugene
Но это ноутовский проц (Ryzen), в синтетике он, в общем-то чуть-чуть шустрее моего Sandy Bridge'а.

Я почти поверил (нет).
Eugene
В продолжение темы, кому интересно про "пенальти" при переходе SSE / AVX:
https://software.intel.com/sites/default/files/m/d/4/1/d/8/11MC12_Avoiding_2BAVX-SSE_2BTransition_2BPenalties_2Brh_2Bfinal.pdf
/ban
/ban прямо в жбан
Eugene
Ну, так контекст (стояние регистров при переключении потоков) кто сохраняет? Если винда не знает о существовании таких регистров, значит увы.
Почему вот для SSE таких проверок нет только...?
До меня дошло!
Для SSE нет таких проверок тупо потому, что xgetbv тогда (во времена появления SSE) не было. Вот и весь ответ, лол! 🤣
Соответственно, можно было только проверять разве что версию Windows. Или использовать SSE на свой страх и риск в надежде, что винда его поддерживает :)
Надо потестить на VMware, какая винда начинает нормально работает с SSE...
 Ivan
Ivan
Слушайте, а у меня нубский немного вопрос: а чем выгоднее присваивать 0 через регистр чем через какой-нибудь mov $0, %ax ?
Ivan
Я просто постоянно вижу подобное в джитовом коде и тут ещё наткнулся в статье
The card mark "set" is actually encoded as "0". This is again practical, because we ca then reuse the zero registers
bilka00
Слушайте, а у меня нубский немного вопрос: а чем выгоднее присваивать 0 через регистр чем через какой-нибудь mov $0, %ax ?
Нет обращения в память, код работает быстрей
bilka00
mov eax, 0 медленней чем опеация в которой xor eax, eax
bilka00
Собстнв когда делаешь mov reg, arg
arg лежит в памяти и эти пересылки занимают больше времени чем когда все происходит чито в процессоре (образно говоря, может кто то более научно обьяснит)
Ivan
Собстнв когда делаешь mov reg, arg
arg лежит в памяти и эти пересылки занимают больше времени чем когда все происходит чито в процессоре (образно говоря, может кто то более научно обьяснит)
У меня вот такой код:
mov %r12b,(%rbx,%r11,1) ; put 0 to (rbx+r11)
Ммм... на интеле:
mov (rbx,r11,1), r12b ; put 0 to (rbx+r11)
Где r12 доселе не использованный регистр
Ivan
Собстнв когда делаешь mov reg, arg
arg лежит в памяти и эти пересылки занимают больше времени чем когда все происходит чито в процессоре (образно говоря, может кто то более научно обьяснит)
Я просто для меня константа, она и в африке константа, особенно 0, я не ожидал что это через память идёт
Ivan
Типа это обращение к участку памяти, где лежит этот код, со смещением на эту константу, типа такого?
 електр🟢нік ✙🟠рчбеч ඞ
електр🟢нік ✙🟠рчбеч ඞ
не, константы в опкоде обычно сразу идут
електр🟢нік ✙🟠рчбеч ඞ
а вот в арме это так и работает
bilka00
bilka00
Там полюбом есть какие то механизмы опимизации с предзагрузкой в кеш
bilka00
Но все же
Ivan
 Eugene
Eugene
mov eax, 0 медленней чем опеация в которой xor eax, eax
xor или sub просто короче, хотя процессоры такие штуки понимают и оптимизируют как-то. Вряд ли это быстрее, но зависимостей это, по крайней мере, не создаёт.
Eugene
У меня вот такой код:
mov %r12b,(%rbx,%r11,1) ; put 0 to (rbx+r11)
Ммм... на интеле:
mov (rbx,r11,1), r12b ; put 0 to (rbx+r11)
Где r12 доселе не использованный регистр
Неиспользованный — это не значит, что там 0.
Но если там 0, то просто это тупо короче (опкод короче).
Записать константу в память 64 бита... я не помню, вроде можно, но если она не превышает signed int32.
Eugene
А в плане скорости можно глянуть xk8.ru/agnerinstbl
Ivan
Неиспользованный — это не значит, что там 0.
Но если там 0, то просто это тупо короче (опкод короче).
Записать константу в память 64 бита... я не помню, вроде можно, но если она не превышает signed int32.
Да, извиняюсь, нулевой, конечно.
Говорят в jvm есть часть оптимизаций, которая расчитывает что r12 содержит 0
Dolphin
Бот
Eugene
Бывает, возникает необходимость перевести флаг zf в cf.
Скажем, чтобы инкрементировать счётчик или ещё что-то (adc).
Если мы только что сделали sub eax,edx, тогда достаточно добавить sub eax,1 — это и будет перенос zf в cf.
А если менять регистр с нулевым результатом нельзя или zf поменялся после cmp, скажем, или test, то придётся городить огород типа
setz cl
shr cl,1
Вроде тоже нормально, но меня всё время не покидает ощущение, что есть какое-то более красивое решение, одной операцией, может.
Ни у кого нет идей на этот счёт? 🙂
Eugene
Естественно, без...
jnz .skip
inc ...
.skip:
Dolphin
Бывает, возникает необходимость перевести флаг zf в cf.
Скажем, чтобы инкрементировать счётчик или ещё что-то (adc).
Если мы только что сделали sub eax,edx, тогда достаточно добавить sub eax,1 — это и будет перенос zf в cf.
А если менять регистр с нулевым результатом нельзя или zf поменялся после cmp, скажем, или test, то придётся городить огород типа
setz cl
shr cl,1
Вроде тоже нормально, но меня всё время не покидает ощущение, что есть какое-то более красивое решение, одной операцией, может.
Ни у кого нет идей на этот счёт? 🙂
>Если мы только что сделали sub eax,edx, тогда достаточно добавить sub eax,1 — это и будет перенос zf в cf.
Если у тебя уже был перенос, он сбросится.
Eugene
Перенос значения флага из zf в cf.
Короче, надо сделать cf = zf.
Eugene
А зачем вам в cf переносить zf?
К примеру (придумываю на ходу), посчитать кол-во элементов массива с нужным значением (со значением eax, допустим).
Хотя нет, тут shr bl,1 не нужен тогда...
xor edx,edx ; кол-во
xor ebx,ebx
@@: cmp [esi+ecx*4-4],eax
setz bl
add edx,ebx
dec ecx
jnz @B
В общем, как-то нужно было, уже не помню суть, но в мозгу осталось.
 Vyacheslav
Vyacheslav
К примеру (придумываю на ходу), посчитать кол-во элементов массива с нужным значением (со значением eax, допустим).
Хотя нет, тут shr bl,1 не нужен тогда...
xor edx,edx ; кол-во
xor ebx,ebx
@@: cmp [esi+ecx*4-4],eax
setz bl
add edx,ebx
dec ecx
jnz @B
В общем, как-то нужно было, уже не помню суть, но в мозгу осталось.
Этот пример можно соптимизировать с помощью repne scasd?