 Alexander
Alexander


I think you need to use timestampadd function inside raw SQL fragment
Alexander
Something like:
dt = datetime.datetime.now()
select(
a for a in Active
if a.group.groupid == some_value
and a.group.active_time is not None
and a.last_active_gr > raw_sql("""
timestampadd(second, -"group"."active_time", $dt)
""")
)
Notice that:
1) I added unnecessary condition a.group.active_time is not None in order to force Pony to join "group" table, as Pony cannot understand it just from raw SQL fragment itself
2) You need to try the query and use the actual alias of the second table, maybe "group" is incorrect
 Santosh
Santosh
select(
(max(d.name), max(d.time), 50 * raw_sql("CEIL(d.time/50)"))
for d in Data
).order_by(3) # by third column
@metaprogrammer I get unsupported operand type error for int and RawSql type
Alexander
select(
(max(d.name), max(d.time), raw_sql("50 * CEIL(d.time/50)"))
for d in Data
).order_by(3) # by third column
Alexander
But the former query was logically incorrect, so I'm not sure that this query produces expected results
Alexander
In your sql query you group by X and select Y,Z,W, this is not how aggregate queries actually work
Santosh
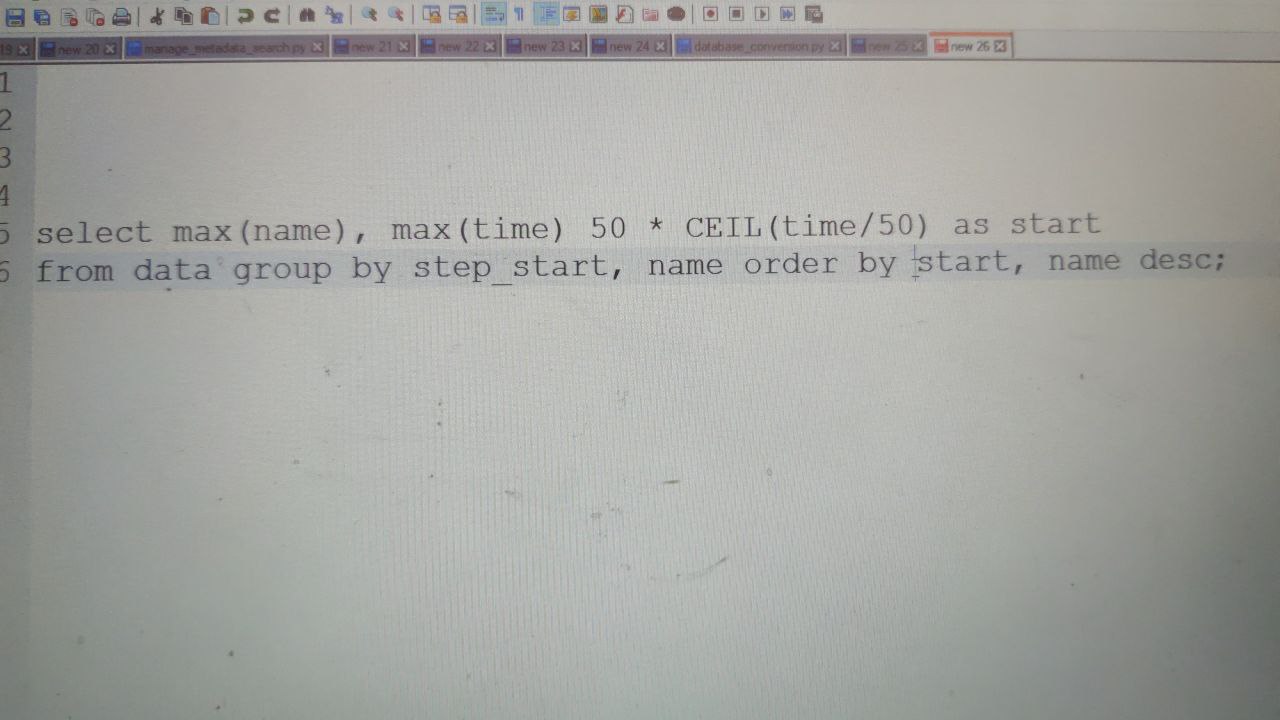 Santosh
Santosh
This is my sample query
Alexander
This query looks incorrect. You group by "step_start, name", but than use different ungrouped and unaggregated expression "start" in select
Santosh
Sorry it's typo
Santosh
Group by start
Alexander
If you group by name, then you should not use max(name) in select
Santosh
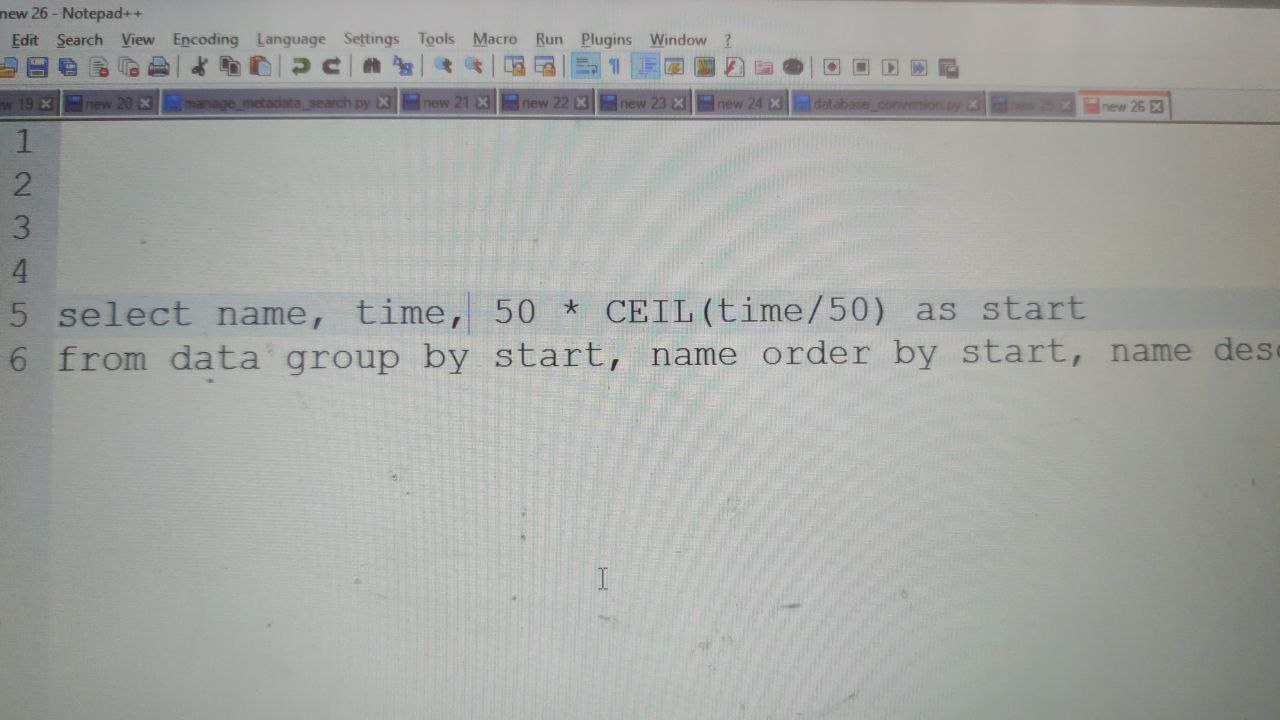 Santosh
Santosh
How about this
Alexander
but you aren't group by time, so you can't use it without aggregation in select
Santosh
I need to select multiple fields and group by that ciel exp and other column
Alexander
If you group by some expressions:
GROUP BY X, Y, Z
Then in select you can include subset of this columns
SELECT X, Y, Z
or
SELECT X, Y
or
SELECT Y, Z
and add some aggregation functions for other columns.
So a correct query may look like:
SELECT X, Y, max(A), sum(B+C)
FROM ...
WHERE ...
GROUP BY X, Y, Z
HAVING ...
or
SELECT X, Y, Z, sum(A), max(P*Q)
FROM ...
WHERE ...
GROUP BY X, Y, Z
HAVING ...
or something like that.
Alexander
In Pony, when you write
select(
(data.X, data.Y, data.Z, max(data.A), sum(data.B+data.C))
for data in Data
if ...
)
Pony splits expression part into the two groups of expressions: aggregated and non-aggregated. In this example, data.X, data.Y, data.Z are non-aggregated, and max(data.A), sum(data.B+data.C) are aggregated.
Then Pony adds non-aggregated expressions to GROUP BY section. So, Pony query
select(
(data.X, data.Y, data.Z, max(data.A), sum(data.B+data.C))
for data in Data
if ...
)
is equivalent to
SELECT X, Y, Z, max(A), sum(B+C)
FROM ...
GROUP BY X, Y, Z
Alexander
So, probably, you want something like
select(
(d.time, raw_sql("50 * CEIL(d.time/50)"), max(d.name))
for d in Data
).order_by(3) # by third column
Alexander
you want to group by time and the second expression
Santosh
Yes
Santosh
Thanks a lot it really helped
Alexander
Sure
Santosh
Is it possible to get entity object in the above case
Santosh
Currently I get tuple of values
Alexander
It usually make no sense to return entity object from aggregated query, as each of returned rows correspond to multiple objects grouped together
Santosh
If I need to select JSON object and it's not part of group by
Santosh
How do we handle
 Bok
Bok
hello everyone! how i can fix this error: ValueError: Value -1001284265240 of attr DB_Group.chatid is less than the minimum allowed value -2147483648
Bok
is this error of DB or python? i cant understand
Bok
yep, it is error of mysql. minimum of int -2147483648
Bok
so how i can declare entity with BIGINT?
Anonymous
Anonymous
attr1 = Required(int, size=8) # 8 bit - TINYINT in MySQL
attr2 = Required(int, size=16) # 16 bit - SMALLINT in MySQL
attr3 = Required(int, size=24) # 24 bit - MEDIUMINT in MySQL
attr4 = Required(int, size=32) # 32 bit - INTEGER in MySQL
attr5 = Required(int, size=64) # 64 bit - BIGINT in MySQL
Bok
aaa thank you very much! ))
Bok
God bless you
Anonymous
You can use the unsigned parameter to specify that the attribute is unsigned:
 maks
maks
Hello, is it possible to write this query using pony orm? Cannot figure out how joins work here
select c.name, count(c.id) as attendance
from m_attendances as a
join m_groups as g on a.group_id = g.id
join m_branches as b on g.branch_id = b.id
join m_companies as c on b.company_id = c.id
group by c.id
Alexander
The exact query depends on your entity definitions, but it may be something like:
select(
(a.group.branch.company, count(a))
for a in Attendance
)
maks
The exact query depends on your entity definitions, but it may be something like:
select(
(a.group.branch.company, count(a))
for a in Attendance
)
does it mean i need to have group declared as set in attendance table?
Alexander
No, in my example it is assumed that the group is declared as Required or Optional. Set should be named in plural, like "groups"
Alexander
As in your SQL query the m_attendances table has the group_id column, the Attendance.group attribute shoud be declared as Required or Optional.
Alexander
If I need to select JSON object and it's not part of group by
Sorry Santosh, I cant comprehend what you want to achieve with this query.
The questions sounds to me like "I have a car, but the problem is it can't fly. Painting it in red color did not help. How I can improve the speed?" I'm not sure that you correctly understand what aggregate queries do
maks
Alexander
Sure
Santosh
Select (p.name, max(p.age), p.details for p in person)
Santosh
Details is JSON column, I don't want to group by, but for that I need to add some aggregation
Santosh
What type of it can be added
Santosh
I can't make like Select (p.name, max(p.age), max(p.details) for p in person)
Santosh
I can make like Select (p.name, max(p.age), group_concat(p.details) for p in person)
Santosh
I can make like Select (p.name, max(p.age), group_concat(p.details) for p in person)
But will it be correct
Alexander
Probably you need to separate it to two different queries
person_list = select((p.name, p.details) for p in Person)
max_age = select(max(p.age) for p in Person)
Alexander
select(p.name, max(p.age), p.details for p in person)
select(p.name, max(p.age), max(p.details) for p in person)
select(p.name, max(p.age), group_concat(p.details) for p in person)
I can't understand meaning of these queries. Can you formulate in plain English what you want to achieve?
Santosh
Actually I have table with few columns in which one is JSON and other is int where I store timestamp in milli seconds
Now I need query this table and make group of these rows in segment
Santosh
Line group of data in segment of second each
Santosh
Hence in select I use 5000 * ceil (timestamp/1000) and group by this
Alexander
But then each group has multipe JSON values in it. How do you want to combine them?
Santosh
I group by name and ciel value so that I get unique name in each segment
Santosh
Combining I do at program level
Alexander
Then probably you should not perform grouping in the query. Instead, you should select rows for each segment and combine them in memory:
def read_segment(name, start_time, duration=1):
end_time = start_time + timedelta(seconds=duration)
query = select(
data for data in Data
if data.name == name
and data.time >= start_time
and data.time < end_time
)
combined_json = []
for data in query:
combined_json.append(data.json)
return combined_json
Santosh
Here I don't know start_time
Santosh
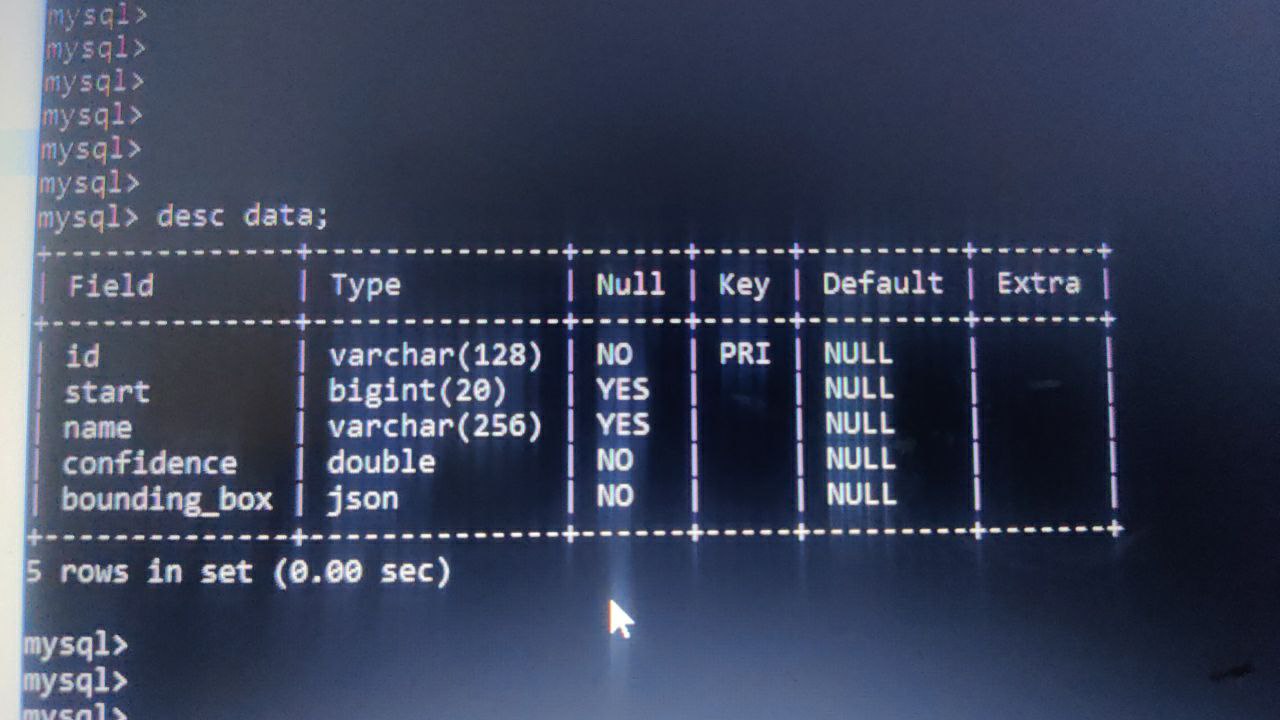 Santosh
Santosh
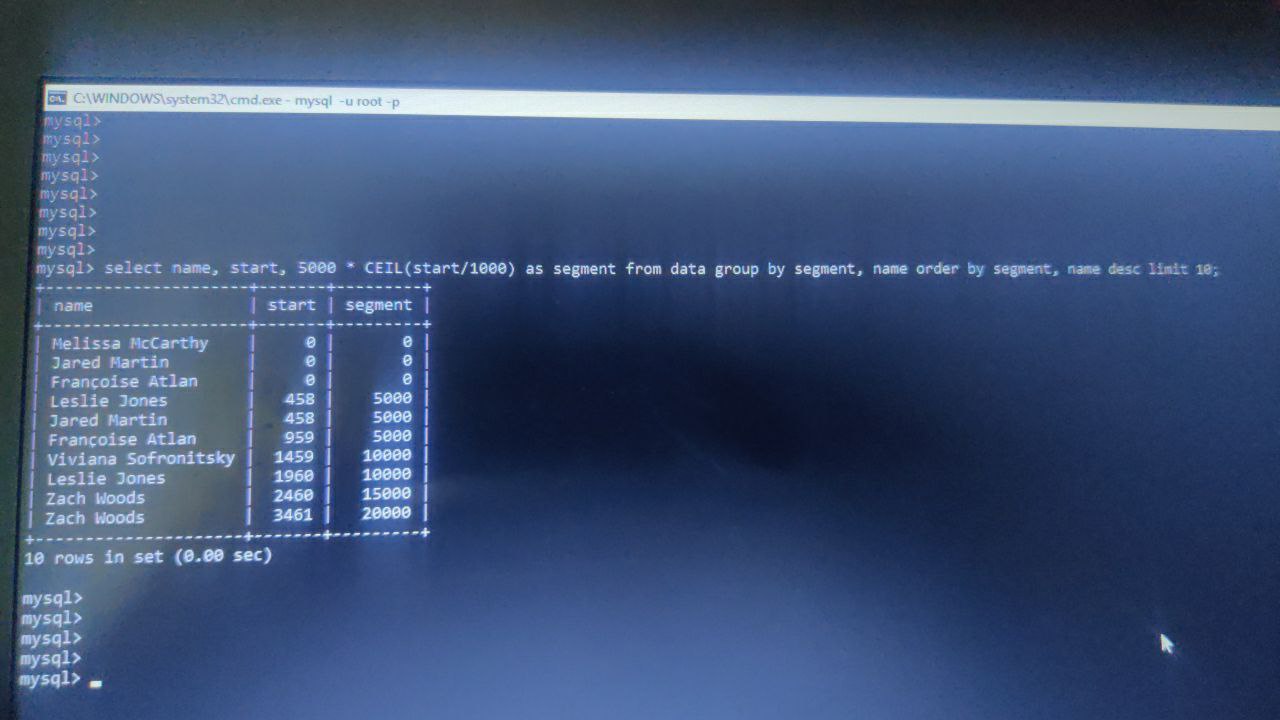 Santosh
Santosh
This is sample data, here I have data of actors, there are other tables where some emotion data is stored in similar table structure
Santosh
So In the same segement I need to check from other table that any emotions are present for same segement
Santosh
Start time on these tables may not be same, but ideally segement should be same
Santosh
overall I need to say these actors were seen in these segement and corresponding emotion
Alexander
You can first select start times rounded to second and then read data in the second query.
def process_data():
query1 = select(
(name, raw_sql("ceil(data.start / 50) * 50"))
for data in Data
)
for name, start_time in query1:
combined_json = read_segment(name, start_time, duration=50)
print(name, start_time, combined_json)
Santosh
Looks promising, but will ther be any performance impact, becoz each table may have around 10k of rows
Santosh
And I have 3 such tables
Santosh
So for each table if I query each table in for loop, so for time stamp of 3 hours we have around 2160 segments
Santosh
And i need to do further processing as well and all within 29 seconds time
Yuvraj
how to add a file field to models in pny orm?
Anonymous
File field? Wdym
 Christian
Christian
how to add a file field to models in pny orm?
https://docs.ponyorm.org/api_reference.html#attribute-data-types
Christian
I guess you want bytes (stored as BLOB).
Alexander
Another option is to store file outside of the database in some folder, and keep file name in the database in str attribute
Santosh
Any workaround for bulk insert
Santosh
For MySQL dB