 Ben
Ben


Hi! Is there any way to set a property to have "ON DELETE RESTRICT" with Pony?
 Alexander
Alexander
Hi! Pony does not support it. Probably you can set up before_update/before_delete hooks to achieve a similar effect if you delete rows only using Pony
 Christian
Christian
In a database of games, I have two entities (game and gametype) in a many-to-many relationship. There's a score how well a gametype fits a game, that applies to this relationship - so I store it in an explicit joining table. Is this a bad idea? Can I make this future-proof for upcoming pony versions? (Looking at you, migrations-table-renaming!)
Alexander
I think intermediate entity is a good way for storing this info
class Game(db.Entity):
title = Required(str)
scores = Set("GameScore")
class GameType(db.Entity):
name = Required(str, unique=True)
scores = Set("GameScore")
class GameScore(db.Entity):
game = Required(Game)
type = Required(GameType)
value = Required(float, default=0)
PrimaryKey(game, type)
...
select(g for g in Game if "Arcade" in g.scores.type.name)
select(score.game for score in GameScore if score.type == "Arcade" and score.value > 0.1)
Christian
Great! Thank you!
 David
David
Hi, may I ask a question? Well this is a question itself so i guess so ;-)
David
I am working with Timescale postgres extension, where we can set an hypertable (kind of time-based index) for a TIME attribute. This is done by calling create_hypertable funcion for the table and indexed attribute. SELECT create_hypertable('mytable', 'myattribute')
David
I was wondering if i could extend pony, so that if a time attribute has a timescale=True argument could generate that in the ddl as currently is generated for indexes
Alexander
Hi! Currently Pony does not have a direct possibility for this.
You can use migration tools like FlywayDB and manually write custom SQL scripts in it to perform such changes.
David
that's what we are trying to do with yoyo
David
but, since we relay on the ddl generated by pony to detect schema changes while developing, it could be nice if that could be added as part of the ddl, so we detect that as part of the changes we have to manually write
Alexander
Thank you for bringing this, I doubt we have resources now to do something in that direction, but in the future we can refactor the code of table creation to make it more extensible #todo
David
well, thank you, but i wasn't asking you to do that, instead offering myself to add it. But now im looking the long list of pending PR's i understand more PRs would add more tension to an eventual merge of the migration branch. just guessing. am i right?
Alexander
Yes, at this moment, it may be difficult to accept big PRs. We have several branches with pretty different internal implementation. Adding a feature to the current branch assumes that the migration branch with a different architecture should also have a similar feature. Probably most of PRs will not be accepted before the finishing of migrations.
David
Looking at the source (orm branch) it wont be hard to implement, just like Oracle has more objects_to_create by adding DBObjects, i could specialize a PGTable(Table) which ads a TimescaleHypertable(DBObject) and implement the interface to generate the sql. What a neat design, guys, its already extensible, but by means of PR :-)
Alexander
You can try, I just can't guarantee we accept the PR fast :) Maybe you need to ping us about it later
David
I think we would agree all that the migration branch is more prioritary than most PR's including this one of mine. Do you have any roadmap or kill-list we could help on?
Alexander
I think I could be ready to discuss it on the next week
David
cool
 Anonymous
Anonymous
Redirect 👀
 Maik
Maik
a little question. why has ponyorm a "first()" option but not a "last()" one on a query?
Matthew
maybe because you can reverse the ordering of your query if you only want the last row?
Matthew
Otherwise I think it would be expensive to load all rows into memory just to return the last row?
Alexander
Yes. Because in SQL, the LIMIT N clause limits first N rows. In SQL, it is very inefficient to read all rows and then throw all of them out except the last one.
In principle, it would be possible for Pony to invert the ORDER BY clause and get the first row from the resulted query. But, depending on the ORDER BY expression, it is not necessarily the same row as what you would get if you read all rows and take the last one.
Maik
Yes. Because in SQL, the LIMIT N clause limits first N rows. In SQL, it is very inefficient to read all rows and then throw all of them out except the last one.
In principle, it would be possible for Pony to invert the ORDER BY clause and get the first row from the resulted query. But, depending on the ORDER BY expression, it is not necessarily the same row as what you would get if you read all rows and take the last one.
i need to get the last value that is imported into the db... when i call a list en return the last line it takes a long time
Matthew
try doing a query that is order by id descending
Matthew
then take the first result from that
Maik
try doing a query that is order by id descending
i do this already but there are 1000's of inputs and takes a few seconds to load... this takes to long
Matthew
use limit(1) ?
Matthew
MyEntity.select().order_by(...).limit(1).first() I think
Maik
thanks you @matthewrobertbell
Matthew
🙂
Anonymous
Is there anyway to create a db entity object outside in a method without db_session, then attach the object to db_session method to add the entity to the database?
Anonymous
test
Alexander
No, currently it is not possible. Outside of the db_session you can create a dict with object's data, but it is not as convenient
Ben
Is there a way for Pony to check if NOT NULL constaints are properly set in the database when generating_mapping?
Alexander
You mean checking that a column has NOT NULL?
Ben
yup exactly
Ben
for my whole schema
Ben
checking that columns marked as Required in Pony actually have NOT NULL
Alexander
If you use inheritance, than an attribute defined in subclass will be nullable even if defined as Required
Alexander
You can check attributes using the following code after db.generate_mapping():
Alexander
for entity in db.entities.values():
if entity._root_ is entity: # not a subclass
for attr in entity._attrs_:
assert not (attr.is_required and attr.nullable), attr
Ben
Oh nice! Thanks a lot. That checks the actual value in the DB?
Alexander
No, that checks Pony entities used to generate CREATE TABLE commands
Alexander
Regarding checking the database, I don't have a ready answer. You can generate a list of required Pony attributes and than check them in the database using some database-specific script
Anonymous
Is there a way to add a callback function when i create a new object? Without before_insert
e.g
instead of doing
User(..., password=my_sha_func(PASSWORD))
I could do
class User(Entity):
...
password = Required(..., func=my_sha_func)
And then
User(..., password=PASSWORD)
Will do the same
 Alexander
Alexander
Yeah
password = Required(str, default=<func>)
Anonymous
Yeah
password = Required(str, default=<func>)
Isn’t it get called in case I didn’t specify password=
?
Alexander
Ah, i got you.
Anonymous
Seems like i can do a hack
def before_insert(self):
self.password = sha(self.password)
But eh
Anonymous
Before_update too
Alexander
You can override the constructor:
def hash_password(password):
return sha(password)
class Person(db.Entity):
username = Required(str, unique=True)
password_hash = Required(str)
def set_password(self, password):
self.password_hash = hash_password(password)
def __init__(self, username, password):
super().__init__(username, password_hash=hash_password(password))
Anonymous
Yeah, that’s nice too
Anonymous
But it’d be nicer to have a callback func, :D
Anonymous
thanks!
Anonymous
You can override the constructor:
def hash_password(password):
return sha(password)
class Person(db.Entity):
username = Required(str, unique=True)
password_hash = Required(str)
def set_password(self, password):
self.password_hash = hash_password(password)
def __init__(self, username, password):
super().__init__(username, password_hash=hash_password(password))
Btw why not just
username = PK(str)
Instead of Unique Required?
Alexander
Both are possible, it just a matter of preference.
1) If it is possible to change username, it should not be a primary key, as primary keys should never change
2) If username is primary key, it is used directly in all foreign keys that refers to User. On one side, it is more explicit - you can look at Message table and directly see username in Message.author. On the other side, int values are shorter and take less place.
Anonymous
Ah, ok. Thanks!
Santosh
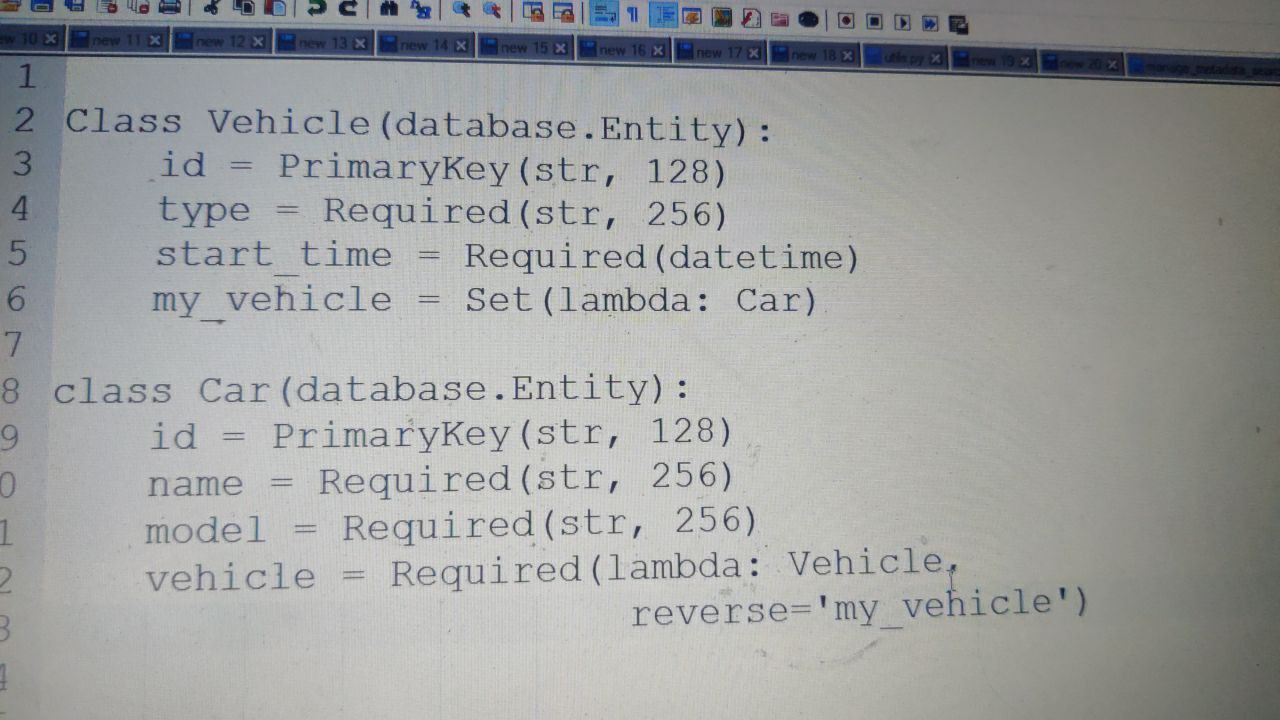 Santosh
Santosh
Now I need to query car and sort by car column and vehicle column
Santosh
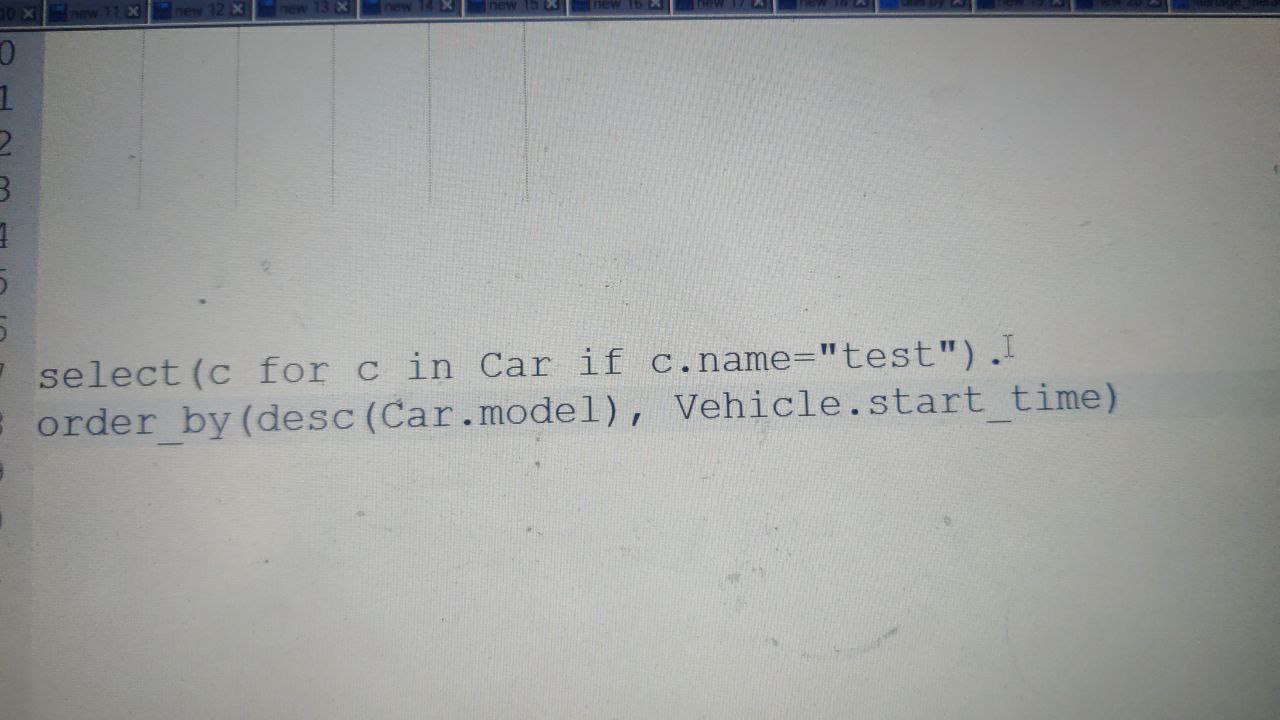 Alexander
Alexander
query1 = Car.select(
lambda car: car.model.startswith('A')
).order_by(
lambda car: (desc(car.model), car.vehicle.start_time)
)
or
query2 = select(
car for car in Car if car.model.startswith('A')
).order_by(
lambda car: (desc(car.model), car.vehicle.start_time)
)
Santosh
Thanks 👍
Maik
got an strange issue:
print(Active.select(lambda gr: gr.group.groupid == '362490' and gr.last_active_gr > datetime.datetime.now() - datetime.timedelta(seconds=gr.group.active_time))[:])
when i put the seconds normal (gr.group.active_time to 600) then it works but i cant get the value from the db anyone know why?
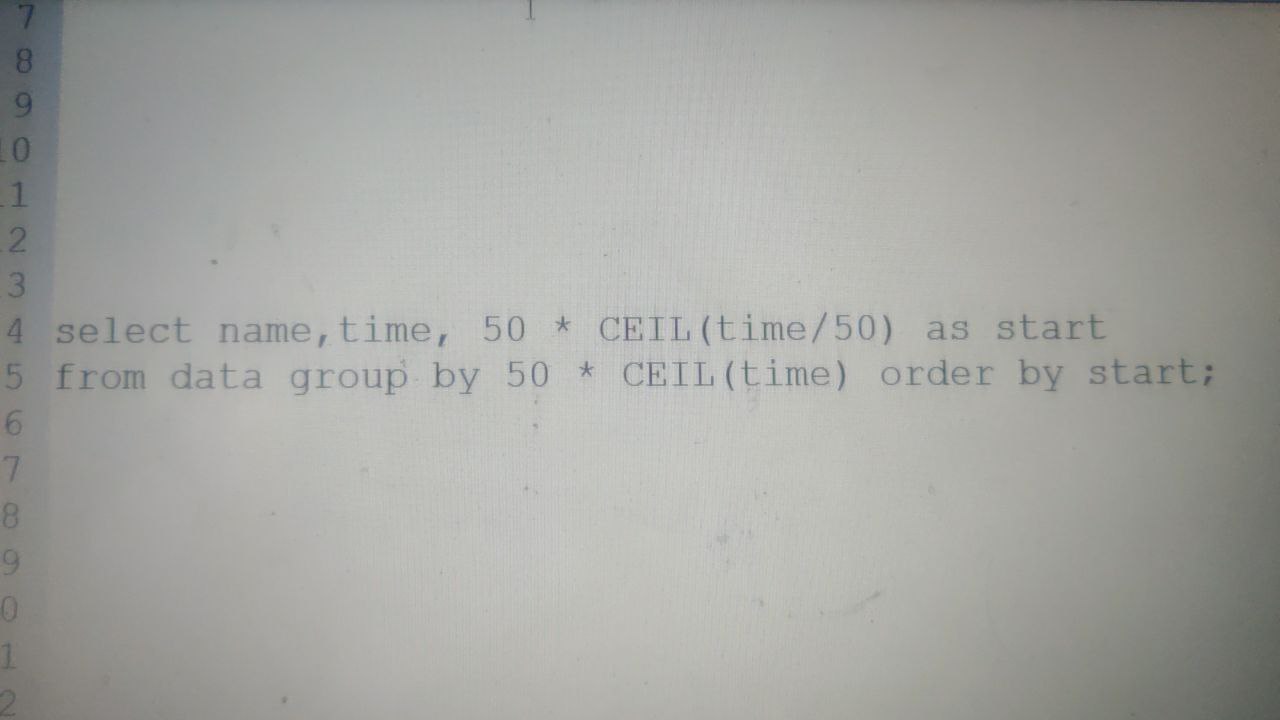
Santosh
 Alexander
Alexander
this is incorrect SQL
Alexander
If you group by some expression (but not by name and time), you need to aggregate name and time in select
Alexander
select(
(max(d.name), max(d.time), 50 * raw_sql("CEIL(d.time/50)"))
for d in Data
).order_by(3) # by third column
Santosh
Is it possible to write for Loop with step count
Santosh
Something like I need to get all data from 0 to 100 with step value of 20
Santosh
I couldn't find solution in MySQL query
Santosh
But any luck as how can I without querying again and again
Santosh
@metaprogrammer any suggestions please
Alexander
You can write complex SQL query which uses window functions:
https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
With ROW_NUMBER function you should be able to do it
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html#function_row-number
But Pony does not support windows functions currently, you need to write raw SQL
As easy but not as efficient alternative, you can load data in memory and process them in memory
Alexander