 Matthew
Matthew


does the table already exist? are you a user who owns the database?
 Lucky
Lucky
I create it as part of my pony_up migration with the code the editor spit out, as I need to insert data into it as part of the same migration.
Lucky
Otherwise I would let pony create that table, that is working fine.
Lucky
However db.execute(…) is run with the proper database connection.
Lucky
does the table already exist? are you a user who owns the database?
Yes, the user owns the database. Only the raw SQL table creation seem to fail.
Matthew
if you connect to the database with the exact same settings and manually run that sql do you get the same error?
Lucky
Huh. I indeed created the table manually, with indeed a different user. Thanks.
Matthew
🙂
Anon
Yes, we have such plans, but right now we don't have resources for that
Have you got any ideas for how you would implement this? Are you looking to convert the ast directly to Pandas or just replace the execute functions with a SQL to Pandas translator?
As I mentioned previously, I've added basic support for SQL Server in the sqlserver branch pull request, although I need to update this pull request as the limit and offset wasn't working, anyway, I've been eyeing to do the same for Mongo DB.
 Alexander
Alexander
As a first step in adding Pandas support I want to add query.to_pandas() method which directly generates Pandas DataFrame without constructing Pony objects in memory. This should be much faster and memory-efficient
 Alexey
Alexey
Have you got any ideas for how you would implement this? Are you looking to convert the ast directly to Pandas or just replace the execute functions with a SQL to Pandas translator?
As I mentioned previously, I've added basic support for SQL Server in the sqlserver branch pull request, although I need to update this pull request as the limit and offset wasn't working, anyway, I've been eyeing to do the same for Mongo DB.
Samuel, what would you expect from the integration with Pandas?
Alexander
So, the query SQL is generated as before, but when fetching data from the database they are loaded directly to a data frame, and the data frame structure is determined from the select expression
Anon
Indeed it would be more efficient but it would be unable to integrate with the current code base without major rewrites, right?
Anon
Samuel, what would you expect from the integration with Pandas?
Well, on the top of my head, I would assume it would simply act as other databases work currently for Pony, and just translate the SQL generated to Pony queries etc.
Anon
But as Alexander mentioned, it would mean the full overhead of Pony
Alexander
Indeed it would be more efficient but it would be unable to integrate with the current code base without major rewrites, right?
I think it is not too hard to add select(...).to_pandas() support, as it will not require complex refactoring.
On the other hand, if you want to allow Pandas as a separate data provider (that is, to be able to write db = Database('pandas', ...)) and use Pandas dataframes as a data source for Pony queries, this is a completely different story
Anon
Yeah, if all you want is to output a query result to pandas, It's really easy since Pandas already have this function, to create a DataFrame from an SQL query, I'm already doing something similar:
sql, arguments, attr_offsets, query_key = query._construct_sql_and_arguments()
connection = database.get_connection()
df = pd.read_sql_query(sql, connection)
 Evgeniy
Evgeniy
Hello there! Please tell me what's wrong with this code: https://pastebin.com/i4Qmp1uN When it is executed, I see the following error:
ModuleNotFoundError: No module named 'pony.orm.dbproviders.Log'
. The Log class is not created inside the corresponding function, although the code inside the class (when it is created) is executed (variables inside the class are assigned).
Evgeniy
The exception swears at this line: `class Log(self.db):`
Alexander
> ModuleNotFoundError: No module named 'pony.orm.dbproviders.Log'
It seems that you have somewhere in your code:
db = Database('Log', ...)
or
db.bind('Log', ...)
instead of specifying the name of supported provider ('postgres', 'mysql', 'sqlite', 'oracle')
Evgeniy
> ModuleNotFoundError: No module named 'pony.orm.dbproviders.Log'
It seems that you have somewhere in your code:
db = Database('Log', ...)
or
db.bind('Log', ...)
instead of specifying the name of supported provider ('postgres', 'mysql', 'sqlite', 'oracle')
No, the db object is created without arguments.
Evgeniy
This is what the Connector class looks like, where the db object is created: https://pastebin.com/WM4jirP2
Evgeniy
In this situation, an object of the Connector class is created without arguments and must use the default SQLite connection.
Jim
hi,
Entity A exists in database.
If I add a new B entity with A relationship :
class A(db.Entity):
some filed...
b = Optional("B")
class B(db.Entity):
a = Optional("A")Will db.generate_mapping(create_tables=True) create the new b column in table A ? Or should I do it manually ?
Alexander
Hi! With optional-to-optional relation Pony will sort (entity_name, attr_name) pairs to determine on which side to create a column by default. As ("A", "b") < ("B", "a"), the column will be created on A side.
generate_mapping does not alter tables, it just creates new tables. So it will not add a column to A, you need to do it manually.
Also, you can force column creation on B side, and the column will be added with the "B" table:
class B(db.Entity):
a = Optional("A", column="a")
Jim
thank you
Vladimir
Hi!
how can I set sql_default for str field ?
now I can't get migration file with sql_default value, but at the same time it's set in the model.
class Channel(db.Entity):
...
geo_type_list = Optional(str, 16, default="BLACK", sql_default='"BLACK"')
...
operations = [
...
op.AddAttr('Channel', 'geo_type_list', orm.Optional(str, 16, sql_default="''")),
...
Luis
Hi, Can I put unsigned in Decimal type?
Alexander
Hi! No, decimal type does not support unsigned option
Luis
Thanks Alex ✌️
Alexander
Hi, what migrations branch do you use?
Vladimir
mmm, I use
"pony = { git = "https://github.com/ponyorm/pony.git", branch = "orm-migrations" }"
Alexander
Migrations are still work-in-progress, and not ready for production yet. orm-migrations branch is a previous attempt, current version is in migrations_dev branch. You can try migrations_dev if you use PostgreSQL. Not sure if it currently supports sql_default correctly or not.
 Alexander
Alexander
I bet it should
 Luis E.
Luis E.
hi, latest version of ponyorm documentation in pdf or other offline format please. thanks.
Alexander
Hi, it is available online only https://docs.ponyorm.org/
Luis E.
oh, thanks.
Jim
Hi! With optional-to-optional relation Pony will sort (entity_name, attr_name) pairs to determine on which side to create a column by default. As ("A", "b") < ("B", "a"), the column will be created on A side.
generate_mapping does not alter tables, it just creates new tables. So it will not add a column to A, you need to do it manually.
Also, you can force column creation on B side, and the column will be added with the "B" table:
class B(db.Entity):
a = Optional("A", column="a")
just to be sure, If I add column creation on B like you propose I've noting else to do to make it work ?
Alexander
Jim
👍
 Андрей
Андрей
Good evening. Please tell me how to fulfill such a request for ponyorm
SELECT AVG(val) FROM (SELECT * FROM table ORDER BY some_val DESC LIMIT 10)
Alexander
Good evening. Please tell me how to fulfill such a request for ponyorm
SELECT AVG(val) FROM (SELECT * FROM table ORDER BY some_val DESC LIMIT 10)
Hi!
from pony.orm.examples.university1 import *
populate_database()
q = select(s for s in Student).order_by(lambda s: s.gpa).limit(10)
q2 = select(avg(s.gpa) for s in q)
Андрей
Tnx
Андрей
 Alexander
Alexander
can you add sql_debug=True option to db_session and show resulted SQL queries?
Андрей
 Alexander
Alexander
That looks like a bug #todo #bug
Alexander
I'll try to fix it today later
Андрей
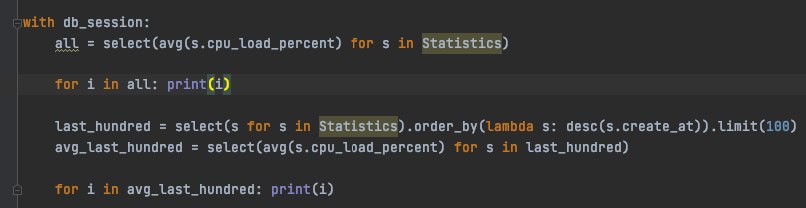
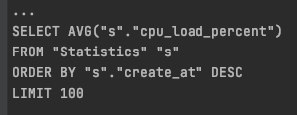
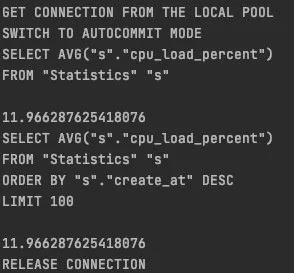 Андрей
Андрей
all = select(avg(s.cpu_load_percent) for s in Statistics)
last_hundred = select(s for s in Statistics).order_by(lambda s: desc(s.create_at)).limit(100)
avg_last_hundred = select(avg(s.cpu_load_percent) for s in last_hundred)
Anon
@metaprogrammer I have an issue in my mssql provider,
When I try to filter a query by datetime:
select(e for e in Entity if e.created > date and e.created < second_date)
I get basically this where clause:
WHERE |e|.|created| >= TIMESTAMP '2020-10-01 02:00:00.000000'\n AND |e|.|created| <= TIMESTAMP '2020-10-31 19:59:00.000000'
I've attempted to fix the TIMESTAMP part by overriding dbapiprovider.DatetimeConverter in mssql provider, but it's not working.
Also, it looks like the "TIMESTAMP" string is added in:
if isinstance(value, datetime):
return 'TIMESTAMP ' + self.quote_str(datetime2timestamp(value))
located in the Value class in sqlbuilding but when I set a break point in this function, when running the above query, it's not breaking execution.
I've tried to make a global search for all sections mentioning the timestamp string but this looks like the only location that adds it.
What I need to do is remove "TIMESTAMP" and the .000000 from the WHERE clause.
Any pointers would be appreciated :)
Anon
nvm, I fixed it :)
RdfBbx
Hello everybody! Tell me please, how I can select last row in table with pony?
Alexander
select(obj for obj in MyClass).order_by(lambda obj: desc(obj.id)).first()
RdfBbx
thank you. I will try
 Michele
Michele
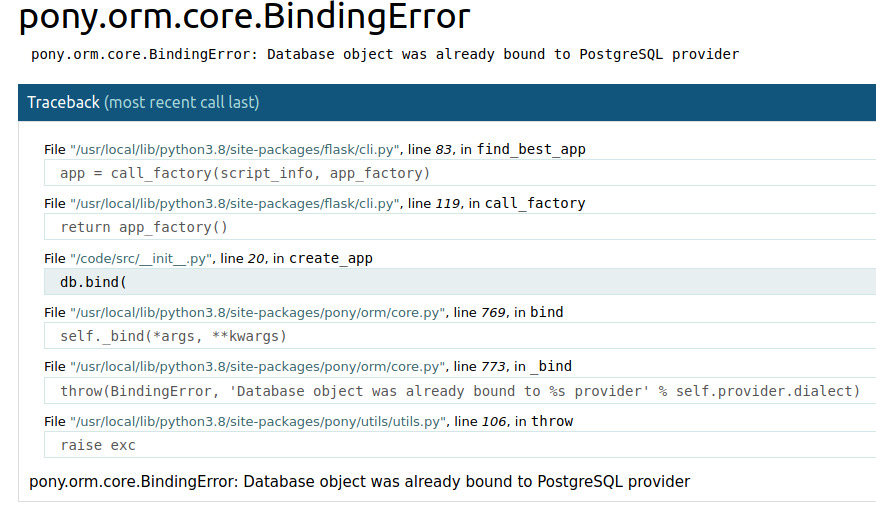 Michele
Michele
It happens randomly sometimes
Alexander
It seems Flask re-import /code/src/__init__.py second time somehow
Michele
Hope this won't happen in production but it should not I guess
Michele
And I have another question.
I have a search bar and I have to search posts titles, how can I do that with pony? (I mean, I have to give results to the user Also if the search query isn’t equal to the post name but it’s similar)
Hope I’ve explained my self and that you can help me
Alexander
What database do you use?
Michele
Postgres
Alexander
Hope this won't happen in production but it should not I guess
Just check out your imports or db.bind calls.
Alexander
Postgres
You can use full text search capabilities of PostgreSQL
https://www.postgresql.org/docs/9.5/textsearch-intro.html
It does not integrate into Pony, but you can include into your query raw SQL fragments with FTS expressions
Michele
Lucky
Ah yes.
once more I crashed my server as
owner_username = Optional(str)
results in
ValueError: Attribute Channel.owner_username cannot be set to None
even though it is set to optional.
Lucky
That is so counterintuitive that Optional doesn't mean nullable like every other type.
Lucky
that introduces bugs every time
Michele
You can do
query.page(3, page_size=20)
But it returns query result (list of objects), not some Paginator class instance
I'm using this but how can I get the number of pages? do I have to select count of all my items and then divide by page_size?
Alexander
That is so counterintuitive that Optional doesn't mean nullable like every other type.
You can do something like:
def Optional(py_type, *args, **kwargs):
if py_type == str:
kwargs['nullable'] = True
return orm.Optional(py_type, *args, **kwargs)
Alexander
Note that other ORMs do the same:
https://docs.djangoproject.com/en/3.1/ref/models/fields/#django.db.models.Field.null
Alexander
that introduces bugs every time
You got this error while trying to add inconsistent data to the database. So, the data consistency was unharmed.
With nullable string attribute, you soon encounter that half of your "empty" strings contain NULL, and another half contains an empty string. And then you will have a fun time debugging why some of your queries return incorrect results, but only for some subset of objects.
Alexander
Note that in SQL NULL have very counterintuitive behavior for some queries
Alexander
So in my opinion it is better to "fail fast" and prevent mixing of two different empty values, especially if one of them has counterintuitive behavior.
Alexander
Another option was to silently convert empty strings to NULLs, but I haven't seen anybody uses this approach.