 Alexander
Alexander


If you add elem to new.some_set, and elem can be linked to a single object only, this action unlink elem from old and remove it from old.some_set
Alexander
Or else we have inconsistent state
 Lucky
Lucky
I was expecting it would duplicate the elem, to not silently "delete" something from an unrelated entry's set.
Lucky
I mean it makes sense, but it's not intuitive that it removes itself from other sets.
Alexander
But what otherwise should be the value of elem.reverse_attr after adding elem to new.some_set?
Alexander
Yes, I agree that is may not always be intuitive, but I think this is a correct way to do
Alexander
But you can keep old.some_set.clear() just to be sure :) This way the code will work if you later change elem.reverse_attr type from Optional to Set
Lucky
Yes, I agree that is may not always be intuitive, but I think this is a correct way to do
The question is if it should do that silently.
Alexander
What else it can do?
Lucky
I'm not even sure right now if that behaviour is documented
Lucky
But I think it should either warn the user (Warnings or logger.warn) or even run into a hard error?
like so you have to write it as either
for item in old.items:
old.remove(item)
new.add(item)
or
for item in old.items:
item.reverse = new
 Matthew
Matthew
I think the current behaviour is logically correct
Alexander
Lucky
I think the current behaviour is logically correct
$ python
Python 2.7.17 (default, Nov 7 2019, 10:07:09)
>>> import this
The Zen of Python, by Tim Peters
Which lists
- Explicit is better than implicit
- Readability counts.
- Errors should never pass silently.
- Unless explicitly silenced.
Lucky
Still same problem as above, still I am trying to re-calculate and update a unique id column which now has duplicates again.
I'm getting
Key (file_unique_id)=(AgADMwEAApuSNAAB) already exists.
In a gist this is the code:
for original in Sticker:
new_file_unique_id = calculate_it(original)
if original.file_unique_id == new_file_unique_id:
continue
# end if
duplicate = db.Sticker.get(file_unique_id=new_file_unique_id)
if not duplicate:
continue
# end if
# TODO: copy everything from duplicate over to original, if newer
duplicate.delete()
original.file_unique_id = new_unique_id
orm.flush()
# end for
Feels like duplicate.delete() is not working?
Lucky
Interesting, the exception is actually raised in the original = db.Sticker.get(id=id) row.
Lucky
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/pony/orm/dbapiprovider.py", line 52, in wrap_dbapi_exceptions
return func(provider, *args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/pony/orm/dbproviders/postgres.py", line 256, in execute
else: cursor.execute(sql, arguments)
psycopg2.errors.UniqueViolation: duplicate key value violates unique constraint "file_unique_id_unique"
DETAIL: Key (file_unique_id)=(AgADMwEAApuSNAAB) already exists.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./main.py", line 5, in <module>
from sticker_tag.main import app
File "./sticker_tag/main.py", line 27, in <module>
from .database_helper.sticker import db_create_update_sticker
File "./sticker_tag/database_helper/sticker.py", line 16, in <module>
from .user import db_create_update_user
File "./sticker_tag/database_helper/user.py", line 8, in <module>
from ..database import User
File "./sticker_tag/database.py", line 50, in <module>
python_import="sticker_tag.migrations"
File "/app/src/pony-up/pony_up/do_update.py", line 300, in do_all_migrations
db, version_and_meta = do_version(module, bind_database_function, current_version, old_db=db)
File "/app/src/pony-up/pony_up/do_update.py", line 178, in do_version
return new_db, version_module.migrate.do_update(migrator)
File "./sticker_tag/migrations/v23/migrate.py", line 33, in do_update
migrate_file_ids(bot_username=me.username, db=db)
File "<string>", line 2, in migrate_file_ids
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 515, in new_func
return func(*args, **kwargs)
File "./sticker_tag/file_unique_id_migrator.py", line 63, in migrate_file_ids
original = db.Sticker.get(id=id)
File "<string>", line 2, in get
File "/usr/local/lib/python3.6/site-packages/pony/utils/utils.py", line 78, in cut_traceback
reraise(exc_type, exc, full_tb)
File "/usr/local/lib/python3.6/site-packages/pony/utils/utils.py", line 95, in reraise
try: raise exc.with_traceback(tb)
File "/usr/local/lib/python3.6/site-packages/pony/utils/utils.py", line 61, in cut_traceback
try: return func(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 4001, in get
try: return entity._find_one_(kwargs) # can throw MultipleObjectsFoundError
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 4104, in _find_one_
if obj is None: obj = entity._find_in_db_(avdict, unique, for_update, nowait, skip_locked)
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 4163, in _find_in_db_
cursor = database._exec_sql(sql, arguments)
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 942, in _exec_sql
connection = cache.prepare_connection_for_query_execution()
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 1810, in prepare_connection_for_query_execution
if not cache.noflush_counter and cache.modified: cache.flush()
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 1896, in flush
if obj is not None: obj._save_()
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 5421, in _save_
elif status == 'modified': obj._save_updated_()
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 5330, in _save_updated_
cursor = database._exec_sql(sql, arguments, start_transaction=True)
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 949, in _exec_sql
connection = cache.reconnect(e)
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 1784, in reconnect
if not provider.should_reconnect(exc): reraise(*sys.exc_info())
File "/usr/local/lib/python3.6/site-packages/pony/utils/utils.py", line 95, in reraise
try: raise exc.with_traceback(tb)
Lucky
File "/usr/local/lib/python3.6/site-packages/pony/orm/core.py", line 947, in _exec_sql
try: new_id = provider.execute(cursor, sql, arguments, returning_id)
File "<string>", line 2, in execute
File "/usr/local/lib/python3.6/site-packages/pony/orm/dbapiprovider.py", line 66, in wrap_dbapi_exceptions
except dbapi_module.IntegrityError as e: raise IntegrityError(e)
pony.orm.dbapiprovider.IntegrityError: duplicate key value violates unique constraint "file_unique_id_unique"
DETAIL: Key (file_unique_id)=(AgADMwEAApuSNAAB) already exists.
Lucky
How can I get a duplicate key violation with a SELECT?
Alexander
It is possible, as select provokes flush of previously modified data
Lucky
I got it working with
orm.flush()
duplicate.delete()
orm.flush()
original.file_unique_id = new_unique_id
orm.commit()
orm.rollback()
Matthew
How can I do "md5(table.column) = md5('some value')" in pony? Do I need to use raw sql?
 Volbil
Volbil
How can I do "md5(table.column) = md5('some value')" in pony? Do I need to use raw sql?
You mean md5 check within query?
Matthew
it's doing an md5 hash of the value
Matthew
this is a way to have fast exact querying of which rows match that value
Matthew
750ms -> .01 ms for my table
Matthew
it works fine in postgres, I just need to change my pony code
Matthew
with raw sql am I risking sql injection?
Matthew
raw_sql('md5("c"."message")' == message_md5)
Matthew
will that work? message_md5 calculated in python
Matthew
message_md5 == models.raw_sql('md5("c"."message")')
Matthew
that worked
Alexander
Calculating md5 in PostgreSQL can be slow without an index based on expression md5("message"):
create index idx_mytable_message_md5 on mytable (md5("message"))
Pony does not create expression-based indexes, you can create it manually.
Alternatively you can add another column message_hash, calculate it on object creation, and specify index=True for it
Matthew
I have that index 🙂
Alexander
Ah, ok
Matthew
is the way I used raw_sql appropriate?
Alexander
yes. raw_sql is protected from sql injections, if you dont pass user-defined sql fragments into it
Matthew
Great, thank you
Matthew
I think I'm stuck, I have a postgres query which does a join and checks whether a few fields are a boolean value or null / not null. This runs in approx 20 ms.When I add a certain boolean field to the query, checking if it is false, the query takes approx 1800ms. I have tried creating a normal index on this field, as well as a partial index, and a partial index to cover all of where statement that doesn't involve the join. This field is false for most values.The query planner refuses to use any indexes I create, instead filtering all rows. This is fast, but when I add this field, it does a lot more filtering and slows down a lot.Any ideas?
Alexander
An index on a boolean field is usually not helpful. First, indexes typically cannot be combined, and the database server needs to choose one of them.
Then, the point of any index is to reduce the number of page reads. If you have an index on, say, user last names, then PostgreSQL can see that searching for a specific user's last name will return on average only 2% of all table pages. So, for a query that specifies one user's last name, using that index as a starting point can reduce the necessary page reads from 100% to 2%. But on the other hand, sequential read of table pages are usually much faster (especially on a traditional HDD drives) than random page reads through an index. PostgreSQL then compares what is more efficient: read 2% of pages randomly through the index, or read 100% of pages 10x faster, and can prefer index in that specific case.
For a bool index, we usually have rows with "true" and "false" values on ALL table pages. So, using the index will not reduce page reads count *at all*. Then PostgreSQL chooses - what is better - read 100% of pages through the index on a boolean column with random reads, or read the same 100% of pages sequentially with a full scan at 10x speed, and obviously chooses full table sequential scan.
So adding an index for a boolean column usually will not speed up the query (except the case when only, say, 0.01% of all rows have "true" value, PostgreSQL knows these statistics, and we search for "true" value in this query).
But it is strange that adding one boolean field to query slows down the query from 20ms to 1800ms. Probably without this boolean field, the query didn't use a full scan and took all information from some index?
Matthew
It used "Index Scan using idx_mytable_created"
Matthew
which is a timestamp field
Matthew
sorry that was wrong
Matthew
it uses an index scan on mytable_pkey
Matthew
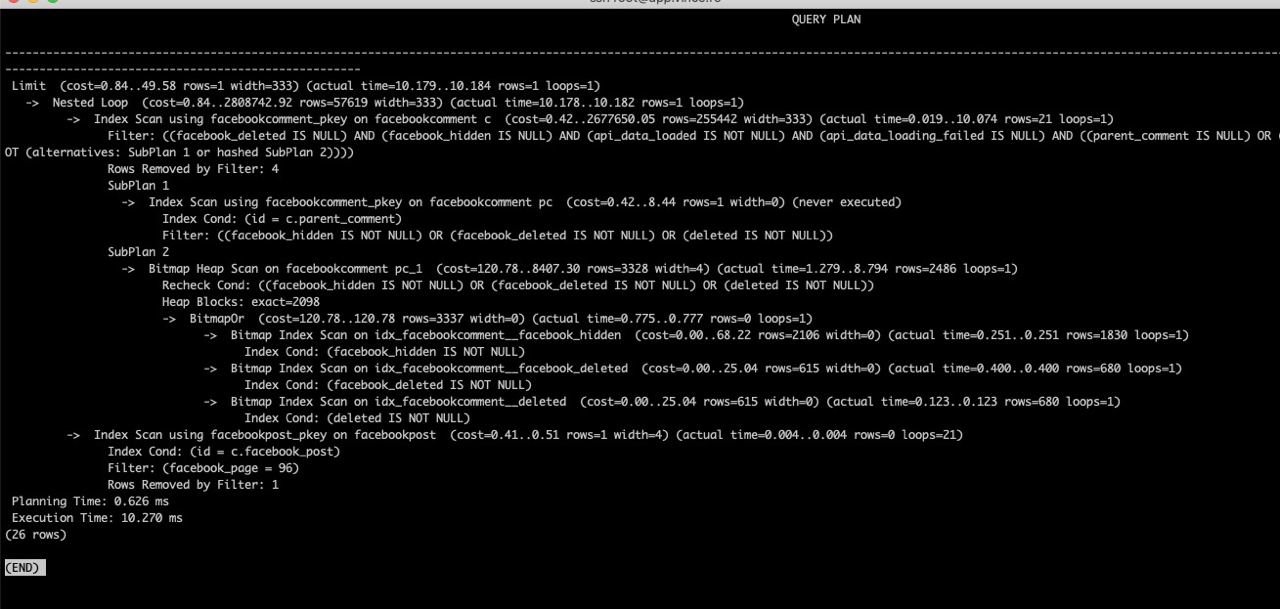 Matthew
Matthew
slow version:
Matthew
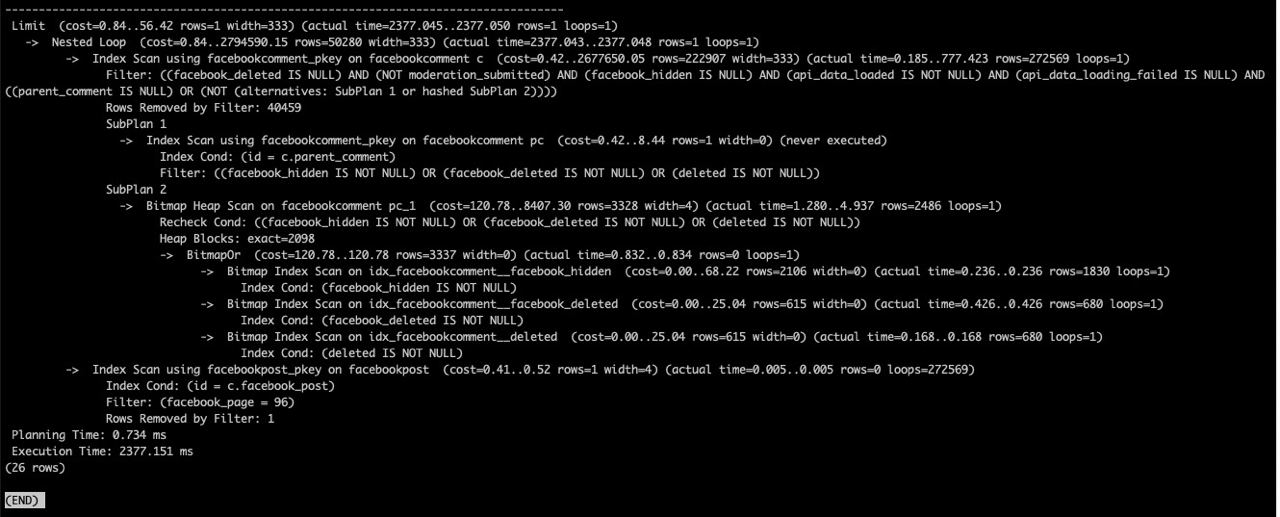 Matthew
Matthew
it seems the same apart from the extra filtering
Matthew
I ended up improving it to 300-400ms by removing the LIMIT. It then used one of my indexes.
 Ben
Ben
Hey! I was looking for a way to add comments to Postgres tables/column in Pony but could not find in the documentation. Is it possible or I must use raw_sql for that?
Alexander
Hi! Adding comments to columns is not supported now in Pony.
You can do it manually (simplified version, not tested):
def set_comment_on_attr(attr, comment):
if not attr.is_collection:
entity = attr.entity
table_name = entity._table_
column_name = attr.column
if column_name:
sql = """
comment on "%s"."%s" is '%s'
""" % (table_name, column_name, comment.replace("'", "''"))
with db_session:
db.execute(sql)
set_comment_on_attr(Person.name, 'first name')
RdfBbx
Good day! I use PonyORM for telegram bot. I have got this error:
pony.orm.dbapiprovider.OperationalError: near "s": syntax error
. I tried to find something on StackOverflow and found nothing. Help me please
Volbil
RdfBbx
Could you provide code which is causing this error?
Sorry, I'm novice. This is Verification bot for online quest.
https://pastebin.com/pmTKs3Ys
Volbil
Can you send whole error log?
Volbil
 Volbil
Volbil
Pony provide nice api for querying so you don't have to do everything manually
https://docs.ponyorm.org/queries.html
Volbil
And since you got syntax error I assume there is something wrong with your raw queries
RdfBbx
Pony provide nice api for querying so you don't have to do everything manually
https://docs.ponyorm.org/queries.html
I tried to replace table name
RdfBbx
and havent found solution for this
RdfBbx
table = tables[user.status]
table = 'One' or 'Two' and etc
RdfBbx
Volbil
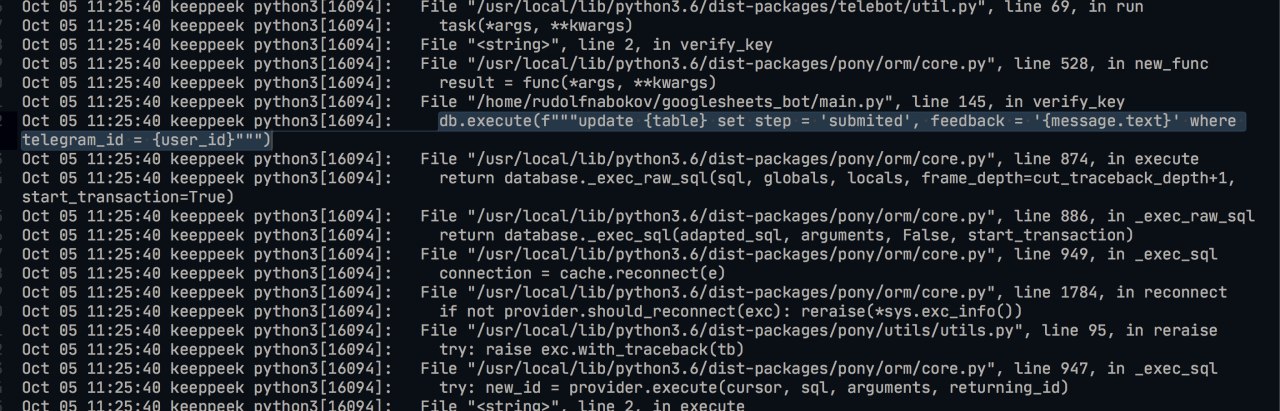 Volbil
Volbil
Here is line which causing this error
RdfBbx
But it was working fine. 8 from 10 players have submitted without erros
RdfBbx
but other two got a problems
Volbil
Sometimes telegram is using negative user id
Volbil
Maybe this is the problem?
Volbil
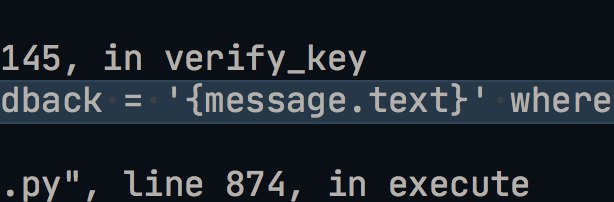 Volbil
Volbil
User can do sql injection this way
 Alexander
Alexander
I tried to replace table name
class MyEntity(db.Entity):
_table_ = 'my_custom_table_name'
...
Lucky
 Lucky
Lucky
So far it seems to still work if I press cancel every time
Lucky
Albeit everything is really slow. Taking about a minute to generate a postgres version of my schema
 Evgeniy
Evgeniy
Are you planning to integrate Pony with Pandas?
Alexander
Yes, we have such plans, but right now we don't have resources for that
Lucky
I am getting an error
pony.orm.dbapiprovider.ProgrammingError: must be owner of relation tablename
After I manually created a table with
db.execute('''
CREATE TABLE "tablename" (