Там еще запись идет постоянно. Около 3х записей в секунду
вообще ниочем
 Andrey
Andrey

 Andrey
Andrey
в смысле скорость
 Nick
Nick
Просто mysql уже при 19 млн записей стал искать около часа. Особенно в to
Индексы настройте, для любой базы ваша выборка не представляет проблемы, если оперативы под индексы хватит
 Artem
Artem

 Mykola 🤷🏼♀️
Artem
Mykola 🤷🏼♀️
Artem
спасибо
Artem
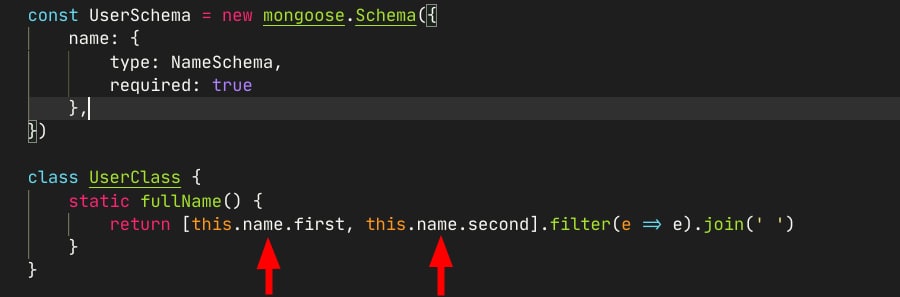
А как задавать несколько типов, или хотя-бы String | null ?
Illia
Всем привет. Посоветуйте как можно добавить колонку в коллекцию (из списка (массива) значений), где каждый следующий эллемент списка закрепляется за каждым следующим эллементом монговской коллекции. (проходить по всей коллекции на вариант - данные большие). Или я фантазер?
Mykola 🤷🏼♀️
А как задавать несколько типов, или хотя-бы String | null ?
по дефолту все значения nullable, если не указано required: true
Mykola 🤷🏼♀️
Всем привет. Посоветуйте как можно добавить колонку в коллекцию (из списка (массива) значений), где каждый следующий эллемент списка закрепляется за каждым следующим эллементом монговской коллекции. (проходить по всей коллекции на вариант - данные большие). Или я фантазер?
если я правильно понял, можно попробовать залочить этот ресурс (список значений для ключа с последним используемым) мьютексом и оттуда его брать.
Если есть несколько инстансов, то можно юзать редлок или еще чего
Artem
 Вячеслав
Вячеслав
Индексы настройте, для любой базы ваша выборка не представляет проблемы, если оперативы под индексы хватит
Индексы btree были установлены. База MyISAM
Nick
Всем привет. Посоветуйте как можно добавить колонку в коллекцию (из списка (массива) значений), где каждый следующий эллемент списка закрепляется за каждым следующим эллементом монговской коллекции. (проходить по всей коллекции на вариант - данные большие). Или я фантазер?
вам нужен связный список из документов в коллекции?
Artem
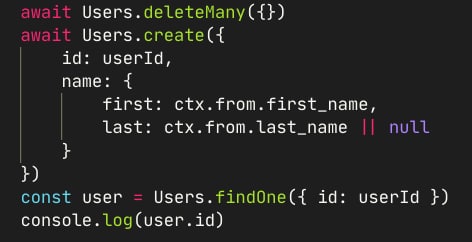
findOneAndUpdate с upsert: true в случае создания нового документа будет создавать в нем те поля, которые были использованы в фильтре?
Artem
(node:33382) DeprecationWarning: collection.ensureIndex is deprecated. Use createIndexes instead. — что за предупреждение? ensureIndex в явном виде не использую
Nick
Nick
Daniil
Nick
т.е. model.findOneAndUpdate({a: 1}, {a:1, b:2}) писать?
перпроверил, фильтр также добавляется при апсерте
Artem
 Nick
Artem
Artem
Nick
Artem
Artem
 Nick
Nick
в каком смысле?
если запустить два поток для одинакового юзерИд, то возможна ситуация когда один из потоков из базы ничего не полуит, т.к. во втором потоке отработал deleteMany.
Artem
Daniil
Павел
Может кто помочь составить 4 запроса с агрегацией (простых). Не бесплатно
Павел

 Anton
Anton
Ставить ли в кампаунд индекс поля по которым будет сортировка?
Anton
 Anton
Anton
1. Первыми будут поля которые участвуют в фильтре с атомарным значением
2. Вторыми идут поля, по которым будет сортировка
3. Третьими будут поля которые в фильтре указывают не атомарное значение а диапазон ($gt $lt)?
 Roman
Roman
У меня одного атлас сегодня либо не грузиться, либо оооочень долго это делает?
Artem
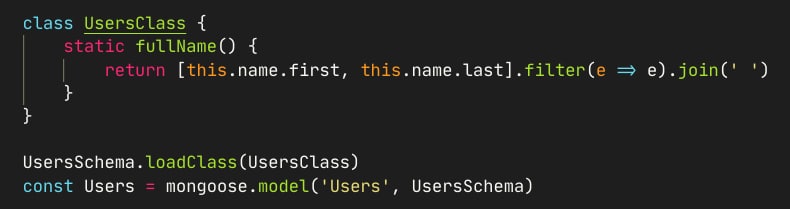
static же, это метод модели, а не объекта
Убрал static. ".findOne().fullName()" => "fullName is not a function"
Artem
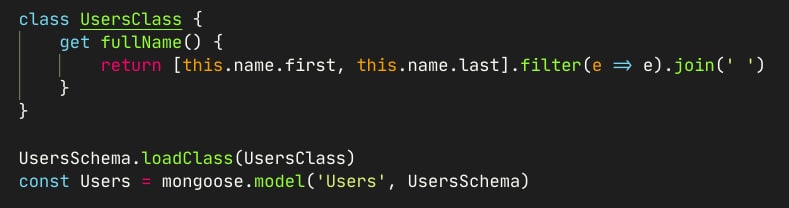 Artem
Artem
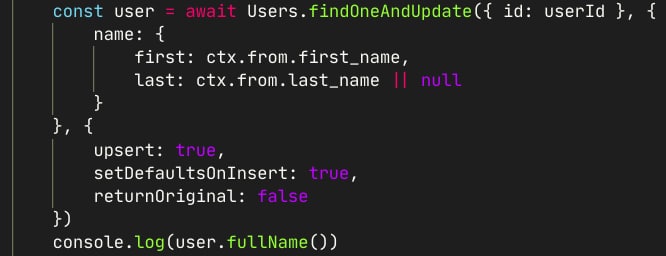 Daniil
Daniil
Убрал static. ".findOne().fullName()" => "fullName is not a function"
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/get
Bogdan
Привет, есть способ получить порядок сортировки для каждого элемента в агрегации?
Nick
Привет, есть способ получить порядок сортировки для каждого элемента в агрегации?
не понятно, нужен пример
Bogdan
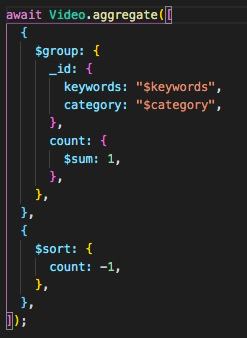 Bogdan
Bogdan
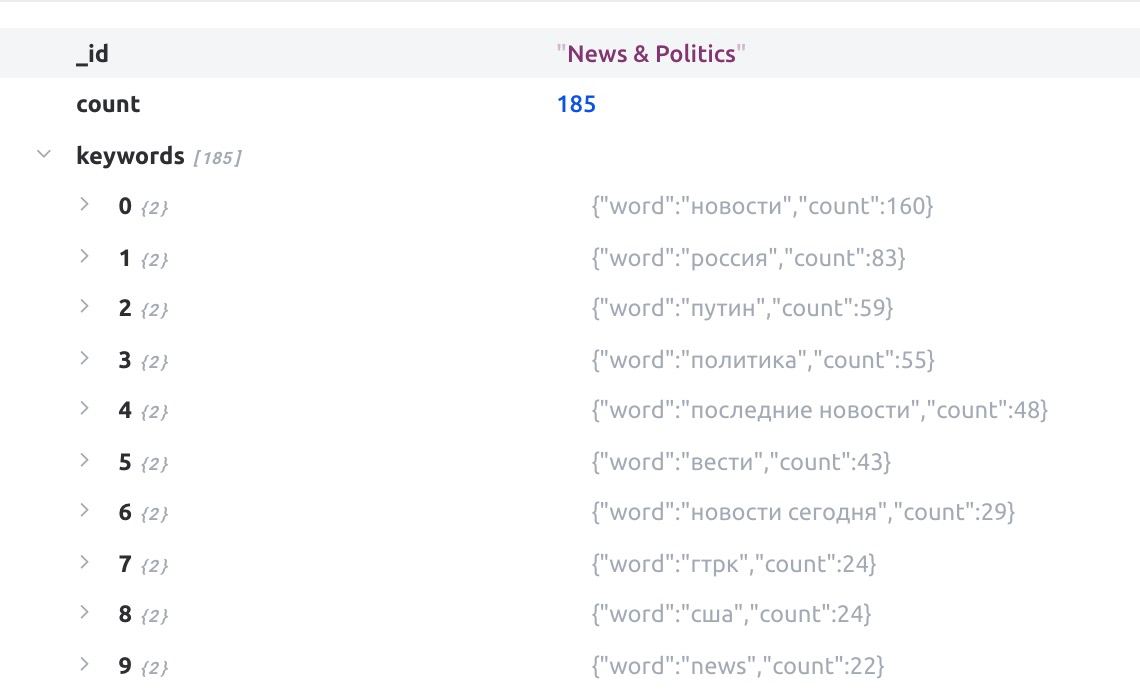 Roman
Roman
подсобите плиз, есть айдишник, с помощью него мне надо найти все документы, у которых в массиве parentIds есть такой элемент, как это замутить?
Anton
Roman
еще один момент хочу прояснить, я хочу обновить массив в документе, сначада я присваиваю массиву пустой массив, а потом хочу с помощью $addToSet добавить элемент в массив, но у меня ничего не добавляетя. Монго так не умеет чтоли или я неправильно делаю что-то?
Viktar
еще один момент хочу прояснить, я хочу обновить массив в документе, сначада я присваиваю массиву пустой массив, а потом хочу с помощью $addToSet добавить элемент в массив, но у меня ничего не добавляетя. Монго так не умеет чтоли или я неправильно делаю что-то?
Добрый день, что бы вам помочь, нам надо видеть, что именно вы делаете. А так идея у вас правильная
Viktar
Только не понятно зачем вам пустой массив
Roman
Только не понятно зачем вам пустой массив
ну долго объяснять, на самом деле там от условия зависит, либо пустой массив, либо с элементами, а уже после добавить еще один элемент в любом случае
Roman
$push: {parentIds: {$each: parent ? [...parent.parentIds, req.body.parent] : [req.body.parent]}} так тоже ничего не добавляет, в итоге пустой массив получается
Roman
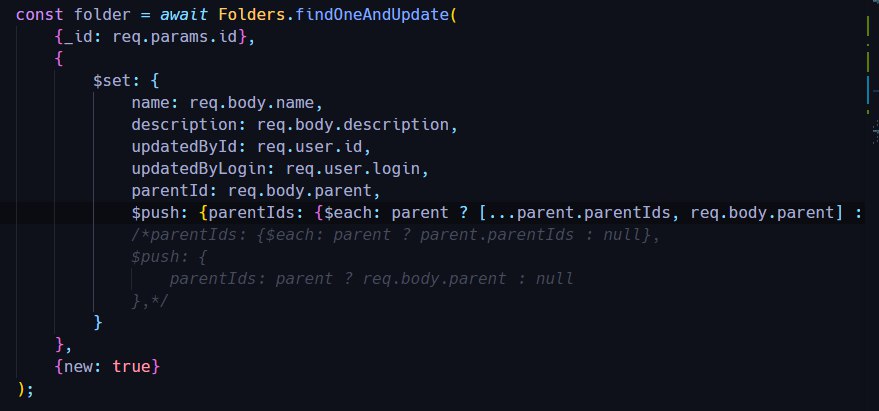 Roman
Roman
вот что я делаю
Viktar
parent ? [...] что это такое я не знаю. Но я не силен в js. Но думаю дело в этом
Anton
Я опять с индесами
Есть такой запрос:
db.BMW_offers
.find({"model":"X5", "predict_value":{"$gt":700,"$lte":1300}, "owners_number":{"$lte":2}, "status":{"$ne":"ERROR"}, "year":{"$gt":2010 }})
.sort({"offer_creation_date":-1, "predict_value":1, "mileage": 1})
По правилам ESR построил такой compound индекс:
db[col_name].create_index([
('model', 1),
('offer_creation_date', -1),
('predict_value', 1),
('mileage', 1),
('predict_value', -1),
('predict_value', 1),
('owners_number', 1),
('status', 1),
('year', -1)
], name='actual_search', default_language='english')
Может что-то убрать из индекса или добавить, не знаете?
Anton
а что не так? не работает? работает недостаточно?
Запрос на 80к доков выполняется 14 сек. первый раз и в последующие по 0.114 сек
Anton
Но это на HDD
Nick
Запрос на 80к доков выполняется 14 сек. первый раз и в последующие по 0.114 сек
а потом этот запрос но с другими ограничения отрабатывает так же медленно или дальше уже все хорошо?
Anton
а потом этот запрос но с другими ограничения отрабатывает так же медленно или дальше уже все хорошо?
Дальше все в пределах 1 секунды
Yaroslav
Сначала читается диск и данные в память загружаются, потом уже из памяти (поэтому последующие запросы быстро работают).
Все по документации)
Yaroslav
А проблема в чем?
Nick
Anton
Получается что слабое звено мой HDD
Я запрос с этим индексом проверил используя hint() и explain() вроде бы он на 1000 иттераций быстрее чем без этого кампаунда, но просто я не уверен в том надо ли в compound вставлять поле несколько раз
Anton
И смущали эти десятки секунд первого запроса
Yaroslav
Получается что слабое звено мой HDD
Я запрос с этим индексом проверил используя hint() и explain() вроде бы он на 1000 иттераций быстрее чем без этого кампаунда, но просто я не уверен в том надо ли в compound вставлять поле несколько раз
Одно поле в кампаунд несколько раз не нужно. С кампаундом надо лишь порядок полей подобрать.
В explain обратите внимание на то сколько документов монга читает с диска. Там два поля есть - сколько ключей индекса прочитано и сколько документов. Вам надо минимизировать количество чтений документов.
Anton
а что за "правила ESR"? интересно даже планировщик монги как себя тут поведет ведет
Roman
можно как то в самом запросе обновления записи получить значение поля документа?
Anton
можно как то в самом запросе обновления записи получить значение поля документа?
Через переменные в агрегационных функциях?