ну это только если монга сама сгенерировала ObjectId, а не клиент его передал
да, как раз сама генерит
 Maxim
Maxim

 Chern
Chern
Подскажите как вытащить данные за период ))))
db.user_bonuses.find(
{$and:
[
{user_id: 2308},
{created_date: {$gte: new ISODate("2019-10-29 17:17:17")}},
{drop: 31500}
]
})
Chern
Text '2019-10-29 17:17:17' could not be parsed
Chern
Спасибо )
Chern
Даже вот так бы
db.user_bonuses.find(
{$and:
[
{user_id: 2308},
{{$toDate:created_date}: {$gte:new ISODate("2019-10-29T17:18:59Z")}}
]
})
 Eugen
Eugen
Ребят, как достать данные из Array обьектов по Id обьекта в Array .
пример
{
"name": "Something",
"surname": "Nothing",
lesson: [
{
id: 123123,
name: "cocococo",
cart: "cart"
},
{
id: 2222222,
name: "cocococo",
cart: "cart"
}
]
}
find { id: 123123, name: "cocococo" }
вывести только из Array обьект ( не целый документ )
{
id: 123123,
name: "cocococo",
cart: "cart"
}
Chern
ребятки, а как можно всё-таки достать данные если у меня текстовое поле в котором хранится дата, а нужно сделать отбор за период? (((
Stripe
Всем привет, а может кто подсказать, почему сортировка не работает корректоно?
сортирую так
{
"name": "desc",
"_id": "desc"
}
в ответе так
{
"items": [
{
"id": "5f5f8fcc344b64ae6afbec3e",
"name": "asdf",
},
{
"id": "5f5f90b1344b64ae6afbec41",
"name": "Test Report",
},
{
"id": "5f5f90ba344b64ae6afbec42",
"name": "Janelle's Report",
],
"stats": {
"total": 3
}
}
 Leonid
Leonid
 Joe
Joe
ребятки, а как можно всё-таки достать данные если у меня текстовое поле в котором хранится дата, а нужно сделать отбор за период? (((
Предварительно подключив проекцию, чтобы перевести текстовую строку в дату монги и только после этого фильтр по дате подрубить
Joe
Всем привет, а может кто подсказать, почему сортировка не работает корректоно?
сортирую так
{
"name": "desc",
"_id": "desc"
}
в ответе так
{
"items": [
{
"id": "5f5f8fcc344b64ae6afbec3e",
"name": "asdf",
},
{
"id": "5f5f90b1344b64ae6afbec41",
"name": "Test Report",
},
{
"id": "5f5f90ba344b64ae6afbec42",
"name": "Janelle's Report",
],
"stats": {
"total": 3
}
}
https://docs.mongodb.com/manual/reference/operator/aggregation/sort/
 Daniyar
Daniyar
ребят.. как восстановить бэкап файл .js? написал: mongorestore --db dbname C:\folders\backup.js.. выкидывает ошибку
 yopp
yopp
mongoimport
Daniyar
он как коллекцию воспринимает чтоли?
yopp
насколько я помню, mongoexport не сохраняет метаданные
Андрей
ребят.. как восстановить бэкап файл .js? написал: mongorestore --db dbname C:\folders\backup.js.. выкидывает ошибку
если делался экспортом, то импортом
Null
Вышла новая версия MongoDB — 3.6.20: https://docs.mongodb.com/manual/release-notes/3.6/#sep-14-2020
Null
4.4.1 (Sep 9) ◦ 4.2.9 (Aug 21) ◦ 4.0.20 (Aug 21)
• Плейграунд для запросов
• Документация
• Официальные курсы (Бесплатно)
Stable: 4.4.1 (Sep 9) ◦ Bugfix: 4.2.9 (Aug 21), 4.0.20 (Aug 21)
Legacy: 3.6.20 (Sep 14)
По вопросам платной поддержки и покупки лицензий пишите @dd_bb
Iskander
Доброй ночи. Подскажите, пожалуйста, по такому вопросу. С mongoDB на вы, но партия сказала решить задачу.
Есть БД, в ней коллекция binary_files, обычная файлопомойка. Файлы достаются редко и хорошо поддаются сжатию, поэтому, в целях экономии места решили их хранить в сжатом виде, а потом при запросе уже восстанавливать исходный файл.
Был написан скрипт, который прошёлся по всем записям в коллекции, извлёк старые бинарные данные, удалил их, положил новые, сжатые. Все работает.
После заметил, что вместо того, чтобы получить экономию места, наоборот, размер БД увеличился, проверил это командой show dbs и сам .wt файл распух.
Нагуглил в интернете, что монга не очищает место после удаления записи, а "переиспользует" его. Поправьте меня, пожалуйста, если я не прав.
Теперь вопрос - это нормальное поведение и это освобождённое место будет переиспользовано или как-то можно пересчитать и по-настоящему почистить данные?
Выигрыш в результате компрессии достаточно весомый, поэтому хотелось бы узнать, как правильней поступить в этой ситуации.
Надеюсь, я объяснил все понятно.
 h1dw0w
h1dw0w
Доброй ночи. Подскажите, пожалуйста, по такому вопросу. С mongoDB на вы, но партия сказала решить задачу.
Есть БД, в ней коллекция binary_files, обычная файлопомойка. Файлы достаются редко и хорошо поддаются сжатию, поэтому, в целях экономии места решили их хранить в сжатом виде, а потом при запросе уже восстанавливать исходный файл.
Был написан скрипт, который прошёлся по всем записям в коллекции, извлёк старые бинарные данные, удалил их, положил новые, сжатые. Все работает.
После заметил, что вместо того, чтобы получить экономию места, наоборот, размер БД увеличился, проверил это командой show dbs и сам .wt файл распух.
Нагуглил в интернете, что монга не очищает место после удаления записи, а "переиспользует" его. Поправьте меня, пожалуйста, если я не прав.
Теперь вопрос - это нормальное поведение и это освобождённое место будет переиспользовано или как-то можно пересчитать и по-настоящему почистить данные?
Выигрыш в результате компрессии достаточно весомый, поэтому хотелось бы узнать, как правильней поступить в этой ситуации.
Надеюсь, я объяснил все понятно.
>Теперь вопрос - это нормальное поведение и это освобождённое место будет переиспользовано
Да
> или как-то можно пересчитать и по-настоящему почистить данные?
https://docs.mongodb.com/manual/reference/command/compact/
 Nick
Nick
Доброй ночи. Подскажите, пожалуйста, по такому вопросу. С mongoDB на вы, но партия сказала решить задачу.
Есть БД, в ней коллекция binary_files, обычная файлопомойка. Файлы достаются редко и хорошо поддаются сжатию, поэтому, в целях экономии места решили их хранить в сжатом виде, а потом при запросе уже восстанавливать исходный файл.
Был написан скрипт, который прошёлся по всем записям в коллекции, извлёк старые бинарные данные, удалил их, положил новые, сжатые. Все работает.
После заметил, что вместо того, чтобы получить экономию места, наоборот, размер БД увеличился, проверил это командой show dbs и сам .wt файл распух.
Нагуглил в интернете, что монга не очищает место после удаления записи, а "переиспользует" его. Поправьте меня, пожалуйста, если я не прав.
Теперь вопрос - это нормальное поведение и это освобождённое место будет переиспользовано или как-то можно пересчитать и по-настоящему почистить данные?
Выигрыш в результате компрессии достаточно весомый, поэтому хотелось бы узнать, как правильней поступить в этой ситуации.
Надеюсь, я объяснил все понятно.
если у вас данные хорошо жмутся, то ожидаемо включенная по дефолту компрессия же сжимала данные достаточно и сдается мне, что ваш алгоритм просто хуже дефолтного snappy на ваших данных
Iskander
>Теперь вопрос - это нормальное поведение и это освобождённое место будет переиспользовано
Да
> или как-то можно пересчитать и по-настоящему почистить данные?
https://docs.mongodb.com/manual/reference/command/compact/
Спасибо, изучаю. @yatoba , нет, мы все посчитали перед запуском скрипта, а также проверяли на тестовых данных, сжатие должно было дать эффект и он есть. Если интересно, то отпишусь позже, как запустим compact.
Nick
буду ждать, интересно насколько реально такое решение применимо
Iskander
Сработало, спасибо. Получили экономию в 16% от исходного объема. Примерно эту цифру мы и ожидали.
Nick
хм
Nick
а сколько это в живых байтах?
Nick
общее место занимаемое сейчас?
yopp
Спасибо, изучаю. @yatoba , нет, мы все посчитали перед запуском скрипта, а также проверяли на тестовых данных, сжатие должно было дать эффект и он есть. Если интересно, то отпишусь позже, как запустим compact.
Если snappy хуже сжимает данные, то вы можете попробовать классический zlib или фейсбуковский zstd. snappy предназначен для good enough компрессии с низким memory & computational cost
yopp
А ещё посмотрите на gridfs
 🖤
🖤
Коллеги, подскажите, есть ли для питона какие-нибудь библиотеки для чтения файлов mongoexport? Я понимаю, что это JSON, однако там есть всякие штуки а-ля $date, $oid и прочее, которые по идее требуют конверсии и я не хочу бросаться писать велосипед; думаю, такая задача уже где-то решалась.
Chern
Коллеги, подскажите, есть ли для питона какие-нибудь библиотеки для чтения файлов mongoexport? Я понимаю, что это JSON, однако там есть всякие штуки а-ля $date, $oid и прочее, которые по идее требуют конверсии и я не хочу бросаться писать велосипед; думаю, такая задача уже где-то решалась.
Если найдете, киньте сюда обязательно )
Я пока на велосипеде сижу ))
 GG
GG
Коллеги, подскажите, есть ли для питона какие-нибудь библиотеки для чтения файлов mongoexport? Я понимаю, что это JSON, однако там есть всякие штуки а-ля $date, $oid и прочее, которые по идее требуют конверсии и я не хочу бросаться писать велосипед; думаю, такая задача уже где-то решалась.
А почему бы не импортировать эти данные в бд, и от туда уже читать?
Chern
А почему бы не импортировать эти данные в бд, и от туда уже читать?
А если нужны джоины и какие-то манипуляцин по агрегации ?
GG
А если нужны джоины и какие-то манипуляцин по агрегации ?
А этого нет в какой нибудь орм монги на питоне?
Chern
А этого нет в какой нибудь орм монги на питоне?
Так в этом и чуть проблемы/вопроса - отдает монго всеравно с каким-то ключом внутри, хотя только что нашел ещё одну библиотеку для монги, может там лучше. И когда получаем данные из нужно нормализовать и уже работать с ними
Nick
🖤
Зачем вам это? Какая задача
У меня просто лежат файлы экспорта, использую их для анализа данных, чтоб не поднимать базу.
Никаких манипуляций, просто чтение
Nick
У меня просто лежат файлы экспорта, использую их для анализа данных, чтоб не поднимать базу.
Никаких манипуляций, просто чтение
Поднимите базу, залейте данные и экспортируйте в json
🖤
Поднимите базу, залейте данные и экспортируйте в json
Оно экспортировано и так в json :) Я ж про то, что в том JSON не совсем обычный JSON, а есть идентификаторы типов данных а-ля date и oid , которые хотелось бы по возможности автоматически конвертировать в подходящие типы.
Dmitry
🖤
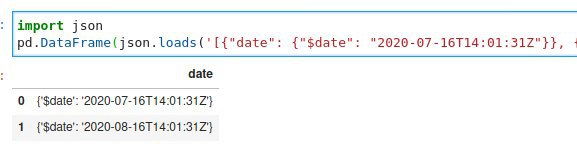
pandas read_json. Всё разберёт. Id просто строка.
а date - не просто строка, и преобразовывать в date её придётся мне, в то время как при запросе драйвером конверсия будет авто конверсия.
🖤
 🖤
🖤
 yopp
yopp
Оно экспортировано и так в json :) Я ж про то, что в том JSON не совсем обычный JSON, а есть идентификаторы типов данных а-ля date и oid , которые хотелось бы по возможности автоматически конвертировать в подходящие типы.
Проще всего экспортировать в BSON и использовать встроенный в драйвер сериализатор
Dmitry
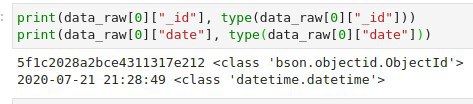
Не понимаю проблему. date['$date' ]
🖤
Проще всего экспортировать в BSON и использовать встроенный в драйвер сериализатор
о, спасибо, вот это интересный вариант, попробую.
🖤
Не понимаю проблему. date['$date' ]
проблема в выборе "велосипедить самому" и "использовать готовое". я ни секунды не спорю, что можно написать все конверсии руками. мой изначальный вопрос про готовую библиотеку.
Petro
Подключаюсь через Studio3t к серверу на mongodb atlas
Получаю ошибку
Mongo Server error (MongoCommandException): Command failed with error 8000 (AtlasError): 'no SNI name sent, make sure using a MongoDB 3.4+ driver/shell.'
кто подскажет что не так?
Nikita
Коллеги, всем привет!
Есть репликасет из 3-х серверов версии 3.4.23
Мастер ушёл в OOM и был убит ядром. После восстановления нормального состояния репликасета параметр featureCompatibilityVersion был выставлен в 3.2 вместо 3.4. Вернул руками, но в логах не нашёл следов изменеия этого параметра кроме того, что я сам выставил
Кто-нибудь сталкивался с подобным поведением?
yopp
Коллеги, всем привет!
Есть репликасет из 3-х серверов версии 3.4.23
Мастер ушёл в OOM и был убит ядром. После восстановления нормального состояния репликасета параметр featureCompatibilityVersion был выставлен в 3.2 вместо 3.4. Вернул руками, но в логах не нашёл следов изменеия этого параметра кроме того, что я сам выставил
Кто-нибудь сталкивался с подобным поведением?
Если db.adminCommand( { getParameter: 1, featureCompatibilityVersion: 1 } ) возвращает 3.4, то всё в порядке
Юрий
на php кто нибудь работает?
не могу понять почему числа сохраняет в int32
$db->test->insertOne(['val' => 15]);
в доках написано про mongo.native_long но от него у меня ничего не зависит, тк это актуально для x32 как я понял.
так и на win и на линукс (версии всего ПО свежие).
Евдоким
на php кто нибудь работает?
не могу понять почему числа сохраняет в int32
$db->test->insertOne(['val' => 15]);
в доках написано про mongo.native_long но от него у меня ничего не зависит, тк это актуально для x32 как я понял.
так и на win и на линукс (версии всего ПО свежие).
Эту статью читал? Может поможет https://habr.com/ru/post/117155/
Юрий
нет
Viktar
Всем привет. Подскажите есть такие решения с монгой когда данные хранятся на с3?
Daniil
Всем привет. Подскажите есть такие решения с монгой когда данные хранятся на с3?
есть решения когда файлы хранятся на с3, а в монге существуют записи о файлах с путем до с3
yopp
Всем привет. Подскажите есть такие решения с монгой когда данные хранятся на с3?
https://www.mongodb.com/atlas/data-lake
Viktar
Благодарю
Nikita
Если db.adminCommand( { getParameter: 1, featureCompatibilityVersion: 1 } ) возвращает 3.4, то всё в порядке
сейчас отдаёт 3.4 потому что я это выставил руками, вопрос в том какого он стал 3.2 после восстановления репликасета
yopp
роллбэк?
yopp
Но 3.4 уже EOL, так что даже если это баг, то его уже не исправят
Nikita
ну ролбечить там некуда, т.к. ставилась изначально эта версия, так что видимо какой-то баг, да 🤤
Юрий
Эту статью читал? Может поможет https://habr.com/ru/post/117155/
прочитал. понял что mongo.native_long не актуально.
это из старого расширения Mongo а я использую Mongodb
в общем вопрос еще открыт.
yopp
на php кто нибудь работает?
не могу понять почему числа сохраняет в int32
$db->test->insertOne(['val' => 15]);
в доках написано про mongo.native_long но от него у меня ничего не зависит, тк это актуально для x32 как я понял.
так и на win и на линукс (версии всего ПО свежие).
а в php у чисел какой тип по-умолчанию?
Юрий
но как то криво работает, если сохранить большое число то в базе уже как double.
$Db->test->insertOne(['val' => 15e9]);
реально поведение которое должно бы решить mongo.native_long параметр. но этот параметр из старого расширения, а в новом нету такого
yopp
значит драйвер при сериализации оптимизирует
yopp
а почему это проблема?
Юрий
а, нет все нормально.
если сделать так то норм
$Db->test->insertOne(['val' => 15000000000]);
в базе уже x64
Юрий
не думал что при экспонентной записи числа в float превращаются.
Юрий
то есть если чсило влазит в 32 бита то сохраняется как 32битное.
если больше - то получается 64битное.
yopp
да
Юрий
и поиск потом не находит.
yopp
нет
yopp
это делает ваш драйвер
yopp
> db.test.insertMany([{number: 111}, {number: NumberLong("2090845886852")}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5f62069b601c589721545183"),
ObjectId("5f62069b601c589721545184")
]
}
> db.test.find({number: {$gte: 0}})
{ "_id" : ObjectId("5f62069b601c589721545183"), "number" : 111 }
{ "_id" : ObjectId("5f62069b601c589721545184"), "number" : NumberLong("2090845886852") }
> db.test.find({number: {$lte: NumberLong("2090845886853")}})
{ "_id" : ObjectId("5f62069b601c589721545183"), "number" : 111 }
{ "_id" : ObjectId("5f62069b601c589721545184"), "number" : NumberLong("2090845886852") }
yopp
Монга нормально справляется с кастом числовых значений при поиске
Michael
хай, кто-то шарит как делать left join?