 Viktar
Viktar


Нужен совет, есть коллекция на 200М записей, нужно их всех проапдейтить, что будет быстрее, инплейс апдейт или рядом создать новую и сделать инсерты?
Yehor
Нужен совет, есть коллекция на 200М записей, нужно их всех проапдейтить, что будет быстрее, инплейс апдейт или рядом создать новую и сделать инсерты?
если не ошибаюсь, то апдейт работает быстрее, чем инсерт
Yehor
https://www.simform.com/mongodb-vs-mysql-databases/
Yehor
тут неплохо рассказано
Viktar
Вот, у меня как то не быстро он идёт. Сейчас накидываю скрипт, что бы с инсертом посмотреть
Yehor
 Yehor
Viktar
Yehor
Viktar
Вторые сутки
Viktar
И по расчету, ещё ему около 45 лет идти)
Yehor
И по расчету, ещё ему около 45 лет идти)
я бы такое колличество данных не хранил бы в монге
доверился бы скьюелю
Viktar
UpdateOne(_id: id, expression ) примерно 2-3 десятка полей апдейтится, есть пуш в массив
Yehor
Viktar
я бы такое колличество данных не хранил бы в монге
доверился бы скьюелю
Так исторически сложилось, миграцию в сиквел можно будет, но через пару месяцев
Yehor
Да. Телеграм меняет на заглавную
не, я имею в виду, что идет апдейт какой-то конкретной записи, или всех 200М?
Viktar
Каждую из 200м своими значениями
Viktar
Открываю курсор и пошел каждую обновлять
Viktar
В смысле не руками?
Yehor
ну я хотел сказать
на сколько сильно отличаются данные для обновления каждой записи друг для друга
у вас эти 200M запросов написаны в цикле типо?
Viktar
Каждая запись индивидуальна
Viktar
Есть каталог, и к нему приходит каждые полгода обновления. Надо обновить текущие значения некоторых параметров, плюс добавить в массивы исторические значения
Viktar
Упрощённый пример: счётчик воды. Текущее значение и значения по месяцам.
Roman
Возможно с bulk write было бы быстрее
Viktar
Только в моем случае текущих параметров больше, и исторических тоже
Yehor
хм, может действительно будет быстрее считывать каждую запись - искать соотвествие айдишки в каком-то справочнике ЯП, где поиск будет О(1) и записывать новый вариант в новый документ(таблицу)
Yehor
в монге есть индексы, не помню просто?
Viktar
Есть
Viktar
Попробую завтра накидать скрипт на инсерт, тогда поделюсь результатами
Yehor
Попробую завтра накидать скрипт на инсерт, тогда поделюсь результатами
а на каком ЯП вы делаете? чисто из интереса
 Артем
Артем
А у вас использование массивов внутри документа необходимо? Возможно если развернуть массив и сделать плоскую структуру каждого отдельного документа, можно будет вместо update воспользоваться bulk write, который упомянули выше и который сильно быстрее
Viktar
а на каком ЯП вы делаете? чисто из интереса
На питоне, pymongo. Прикрутил к нему мультрединг, что бы сразу в несколько потоков
Viktar
А у вас использование массивов внутри документа необходимо? Возможно если развернуть массив и сделать плоскую структуру каждого отдельного документа, можно будет вместо update воспользоваться bulk write, который упомянули выше и который сильно быстрее
Не получится, массивы собирают объекты, иначе будет слишком сложный бекенд, собрать их в массивы
Артем
Внутри массивов находятся объекты?
Viktar
Да
Артем
Ну, насколько я понял все операции можно разбить на инсерты новых документов и апдейты массивов внутри старых документов. Инсерты пройдут быстро без проблем тем же bulk write, а апдейты можно заменить на селект тех документов, которые планируется модифицировать, выкачку всех документов, затем модификацию каждого документа в оперативной памяти, затем удаление старых, инсерт новых (опять же через bulk write). Можно удаление не делать, а просто делать инсерты в новую коллекцию
Артем
Это конечно если вы можете написать более менее общее условие на селект модифицируемых документов
Артем
Учитывая ваши большие объемы, эту операцию можно разделить на фиксированные группы. А то вдруг не влезут в оперативку)
Viktar
У меня сейчас примерно так: курсор {}, потом идём во вторую коллекцию _id:_id, забираем данные, формируем експрешен для апдейта, и сам апдейт
Viktar
Все это обернуто в мультипроцессинг с фиксированным количеством записей на каждый процесс
Viktar
Хочу попробовать примерно такой же подход, только формировать новый документ, и инсертить в новую коллекцию, потом старую коллекцию удалить, а новую переименовать
Viktar
Но вижу один момент, если прервать апдейт, то его потом можно продолжить с того же места, есть признак, того что запись уже проапдейчена(версия). То с инсертом в новую, продолжить в случае остановки уже не получится по такому признаку
Артем
А чем отличается проапдейченный документ от документа после инсерта в новую коллекцию?
Артем
Он ведь так или иначе должен содержать новую версию? Разница лишь в том, что вставка в массив произошла на вашей стороне, а не на стороне монги
Viktar
А чем отличается проапдейченный документ от документа после инсерта в новую коллекцию?
Да. Но ведь вычитывается документ из другой коллекции, в которой он остаётся без изменения, а в варианте с аплейтом, он меняется
Артем
Вы можете в документ в новой коллекции добавить временное поле prev_id — id соответствующего старого документа. Тогда при остановке вам нужно будет взять множество всех id для документов, требующих апдейта из старой коллекции, затем множество всех временных prev_id у вставленных документов в новую коллекцию, взять разность между ними и получить множество id, по которым нужно продолжить. Потом в конце дропнуть поле prev_id у всех документов новой коллекции
Viktar
Вы можете в документ в новой коллекции добавить временное поле prev_id — id соответствующего старого документа. Тогда при остановке вам нужно будет взять множество всех id для документов, требующих апдейта из старой коллекции, затем множество всех временных prev_id у вставленных документов в новую коллекцию, взять разность между ними и получить множество id, по которым нужно продолжить. Потом в конце дропнуть поле prev_id у всех документов новой коллекции
👍 я примерно так и думал, только у меня ид совпадают, поэтому найти разницу множеств
Viktar
Но быстро ли отработает ин на таком количестве ид?
 Yaroslav
Yaroslav
Всем привет
Yaroslav
Хотел бы спросить, есть у кого опыт реализации elastic search +mongodb, первый как поисковый движок, а второй как основная бд
Viktar
Хотел бы спросить, есть у кого опыт реализации elastic search +mongodb, первый как поисковый движок, а второй как основная бд
На моем проекте как раз такая связка.
Yaroslav
На моем проекте как раз такая связка.
Супер, расскажи плиз, как вы организовали индексацию, какие инструменты задействовали, поделись плиз опытом)
Viktar
Но у меня данные не динамичные, обновляются редко. В моём варианте, флатится Джейсон, по определенным полям и записывается весь в индекс. И при обновлении индекс перестраивается с 0.
Yaroslav
Ясно, я коненчо буду писать свои плагин для монгуса, чтобы перже сохранением или обновлением документа отправлять нужное в индекс
 Denis 災 nobody
Denis 災 nobody
а кто использовал монгу от перконы? Дали тут изучить
Denis 災 nobody
Percona Server for MongoDB delivers high-performance and reliability to enterprises looking to achieve optimum performance, without being tied into an expensive proprietary software vendor relationship.
Denis 災 nobody
MongoDB Community Edition is at the core of Percona Server for MongoDB, so it automatically includes features such as native high availability, distributed transactions, a flexible data schema, and the familiarity of JSON documents.
But Percona Server for MongoDB doesn’t stop there: with the Percona Memory Engine in-memory storage engine, HashiCorp Vault integration, data-at-rest encryption, audit logging, external LDAP authentication with SASL, and hot backups it's a complete package that maximizes performance and streamlines database efficiencies.
Артем
Но быстро ли отработает ин на таком количестве ид?
По ид в монге создается автоматически индекс, поэтому скорость по идее должна быть максимальной
Viktar
Ясно, я коненчо буду писать свои плагин для монгуса, чтобы перже сохранением или обновлением документа отправлять нужное в индекс
Я думаю, эта архитектура, не в новинку. Поэтому советую сначала изучить продукты которые уже есть. Возможно будет дешевле переиспользовать
Viktar
По ид в монге создается автоматически индекс, поэтому скорость по идее должна быть максимальной
Думаю так оно и есть, но на больших объемах, это может работать не очень хорошо
Артем
Думаю так оно и есть, но на больших объемах, это может работать не очень хорошо
Я на первый взгляд могу сказать про одну проблему, с которой сам сталкивался — expression, который будет содержать этот in, вывалится за 16 Мб из за ваших объемов. Но это лечится нарезанием массива айдишников на фиксированные куски
Артем
Но это не совсем про скорость. Со скоростью, кажется, проблем быть не должно
Denis 災 nobody
Кто перкону трогал?
 Bro
Bro
Bro
Bro
такая же проблема была
Bro
апдейт по сути 2 операции нужно выбрать документы и проапдейтить их
Bro
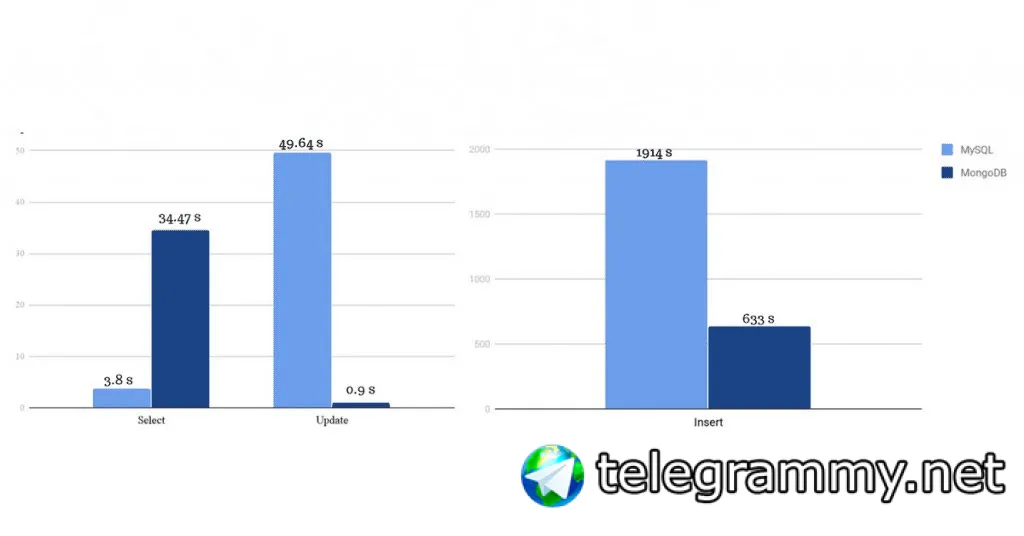
хотя я могу и ошибаться. но вообщем попробовав апдейты и перейдя затем на инсерты получил значительную (в несколько раз) прибавку в скорости.
Bro
коллекции по 400+лямов были
 Valera
Valera
 Valera
Valera
 Roman
Roman
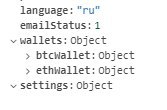
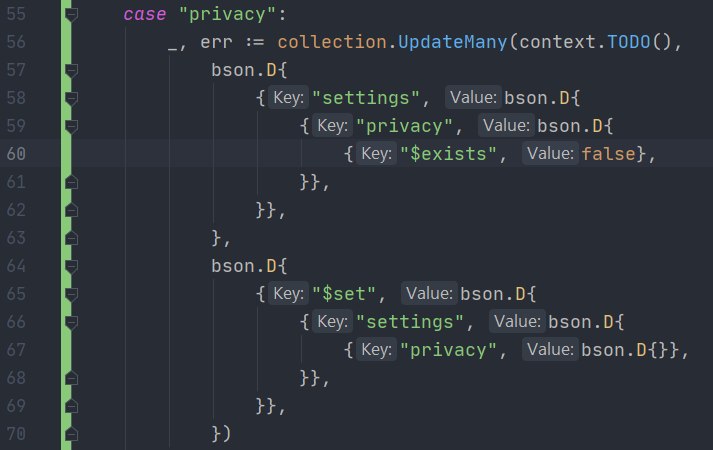
А попробуйте как Key :"settings.privacy"
 Denis
Denis
 Andrew
Andrew
Подскажите, пожалуйста: у меня есть 100 записей, но мне нужно получать по 10. Я сделал .find(...).limit(10), а как, например, вторые 10 получить?
Roman
https://docs.mongodb.com/manual/reference/method/cursor.skip/
Bro
Скип вроде плохой варик
Bro
Лучше иды использовать
Bro
Про это в доках есть
 no
no