 Гена
Гена


{
"$project" : {
"feald" : {
"$objectToArray" : "$feald"
}
Гена
вот кусок запроса
 Nick
Nick
дальше добавить стейджы
$unwind
$match
Гена
а match будет field.k?
Anonymous
🤚 привет
Anonymous
⚠️ У вас есть штаб разработчиков, но они не хотят пилить новую фичу для рынка?
👨💻 Простую разработку решаете на раз-два, а при внедрении оригинальных, нестандартных решений слышите:
❌ Это не предусмотрено фреймворком;
❌ Тут такое сделать нельзя;
❌ Это делают только большие корпорации;
🚫 Не верьте им! Большинство сложных систем - это набор маленьких, простых решений.
✅ Если Вам знакома данная проблема, то Мы предлагаем Вам и Вашим разработчикам пройти авторский курс, аналога которому нет на рынке!
👉 Курс по внедрению оригинальных решений в графовую базу данных neo4j предназначен для владельцев бизнеса, который включает в себя комплексную backend-систему.
👍 Курс расскажет как можно использовать neo4j для быстрого решения нестандартных задач на стороне backend.
Когда старт курса❓ Какая структура курса ❓ Какая стоимость❓Могу я узнать о курсе более детально ❓
❗️Ответы на эти вопросы вы сможете узнать у: @n4jdev
🙅♂️ Не ждите пока проблема в backend решится сама собой.
🏆 Записывайтесь на курс и получите уникальную информацию по внедрению оригинальных решений на neo4j
Гена
да
вот такой мутант получился
db.getCollection("coll").aggregate(
[
{
"$project" : {
"field" : {
"$objectToArray" : "$field"
}
}
},
{
"$unwind" : {
"path" : "$field.k"
}
},
{
"$match" : {
"field.k" : 1.0
}
},
{
"$limit" : 1.0
}
],
{
"allowDiskUse" : false
}
);
Nick
анвинд просто field
Гена
просто запрос супер долго бежит
Nick
а вы лимит в начало поставьте
Nick
чтобы проверить идею
Гена
ок
Гена
чет не хочет
Гена
[
{
"$project" : {
"field" : {
"$objectToArray" : "$field"
}
}
},
{
"$limit" : 1.0
},
{
"$unwind" : {
"path" : "$field"
}
},
{
"$match" : {
"field.k" : 1.0
}
}
],
{
"allowDiskUse" : false
}
);
Гена
{
"$match" : {
"field.k" : 1.0
}
неверный
Гена
@yatoba подскажи пожалуйста, можно ли в цикле в монге подставлять значения через курсор в путь ?
то есть field.переменная.value?
Гена
всё
Гена
разобрался
Гена
Спасибо большое)))
Гена
Подскажите пожалуйста, а как через group собрать всех по оперделённому значению ?
Гена
например по значению field.1=5
и вот все документы где это значение равно 5 захлопнуть в один
Roman
Можно выбрать все документы, где field.1=5, а потом делать group
Гена
можно как то сделать так чтоб он одинкаовые схлопывал?
Roman
Что значит "одинаковые схлопывал" ?
Гена
Что значит "одинаковые схлопывал" ?
если документы в них есть поле 1
в каждом документе это поле содержит еще поле 2 со значениями
от 1 до 999
надо со всех документов собрать одинаковые значение и собрать в один вывод
например
Документов с значением 88 в коллекции 150
Гена
структура такая
поле1.поле2.:значение
Гена
ну и в идеале показать сколько таких значений поймалось
Roman
Вы бы лучше где-нибудь написали пример, какие документы имеются, и какой результат ожидается. Непросто понять, какая у вас схема данных
Гена
Вы бы лучше где-нибудь написали пример, какие документы имеются, и какой результат ожидается. Непросто понять, какая у вас схема данных
{
"field" : {
"k" : "88"
}
}
{
"field" : {
"k" : "110"
}
}
{
"field" : {
"k" : "111"
}
}
Гена
это один документа
а таких много где есть и 88 и 110
Гена
надо чтоб они собирались вместе
Roman
Попробуйте
group {
_id:{
"$field.k"
}
}
Гена
спасибо, сейчас попробую
Гена
не, пишет ошибку(
Гена
он просит после "$field.k" двоеточие
Nick
уберите вокруг "$field.k" скобки
Гена
что то вышло
Гена
но пока не понял что
Гена
 Nick
Nick
ваши значения и вышли
Гена
то есть 134 то значение
Nick
прочитайте весь раздел, много вопросов снимется
Гена
ок
спасибо)
Гена
у меня теперь вопрос, как посчитать все документы у которых одинаковый вывод.
то есть например все где есть 134
Roman
Первый пример же
https://docs.mongodb.com/manual/reference/operator/aggregation/group/#count-the-number-of-documents-in-a-collection
Гена
хммм
Гена
наверное я как то не так тестировал
Гена
спасибо
Roman
Только для _id задаете не null, а поле по которому группируете
Гена
а вместо каунт ?
Гена
простите что задалбливаю, я просто уже в отчаянии(
Roman
count - это просто имя поля, в котором будет результат, можете назвать как хотите
Гена
вроде готово) спасибо
Гена
 Anonymous
Anonymous
Привет! подскажите, плиз, если я в компас монго подключаюсь без пароля, то почему pycharm запрашивает пароль? пробовал по всякому и никак не подключается. PS defaultauthdb и admin не прокатило.
 Veaceslav
Veaceslav
Всем привет, можно ли как-то в $arrayelemat если нету нужного field-а, отдавать дефолтное значение ?
Anonymous
добрый день, коллеги!
есть запрос, вида (в аггрегации):
$match: {
$or: [
{
userId: ObjectId('5cc25e9a63fb1ebc93b23575')
},
{
status: '1',
fieldUser: '5304'
}
],
status: {
$ne: '2'
}
}
Вопрос, какие индексы должны быть?
В коллекции 5 милллионов документов
Сейчас такие индексы:
index({ userId: 1 })
index({ status: 1, fieldUser: 1 })
index({ status: 1 })
выгрузка данных с профайлинга (system.profile) показывает высокие показатели (millis), самый высокий - 98000
Дока не очень помогает - https://docs.mongodb.com/manual/reference/operator/query/or/
Yaroslav
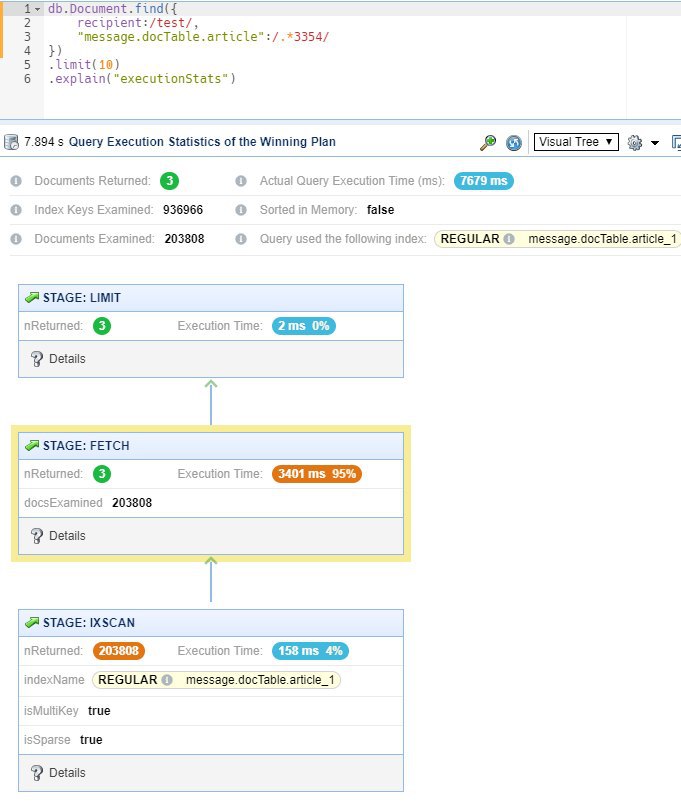
Посмотрите query plan, там будет расписано что с вашим запросом происходит, сможете разрбраться на какой стадии втыкает.
У вас три поля в запросе, чтобы монга при фильтрации не подтягивала документы с диска нужно как минимум, чтобы все эти поля были в индексе. Я бы разбил это на два запроса и сделал два двойных индеса (status, fieldUser), (status, userId). Но сначала лучше через query план понять что у вас за проблема)
 Ivan
Ivan
Ребят а кто-нибудь монгу к графане прикручивал?
 Mher
Mher
 Ivan
Ivan
Пока на том же стенде где и монга
Mher
самый простой вариант это с прометием
Mher
у меня даже где то есть контейнер собранный
Mher
щас, если найду скину
Ivan
Да вряд ли в лабе позволят контейнер деплоить чей-нибудь
Ivan
Я про то что к своему удивлению нашел в графане кучу датасорсов, но монги как датасорс нету
Ivan
Нашел вот такой проект
https://github.com/JamesOsgood/mongodb-grafana
Но я хз как он будет по прозиводительности работать. У нас в эластик падает по 80гб счетчиков в день. Эластик вывозит, но у него нейтивный датасорс в графане. Сейчас решил попробовать монгу потестить и вот заткнулся
Mher
а тебе для мониторинга нужно или для запросов?
Ivan
Запросы с графаны в монгу делать
Mher
ну так бы и сказал... подключаешь плагин для графаны, и пользуешься, по сути все
Ivan
Да вот хотел спросить если кто-то уже ставил, какие фидбеки по производительности. Если никто не ставил, поставлю и отпишусь вывезло/невывезло :)